【C#】Amazon S3 SelectでS3にアップロードしたCSVをSQL検索してみた
はじめに
大量データを検索する際、DBへの負荷とならないよう、別のリソースで検索できないかと調べているとAmazon S3 Selectというものを知りました。結構手軽に試せそうなので、試してみます。
Amazon S3 Selectとは
S3に保存したオブジェクト(CSVやJSONファイル)に対して、SQLクエリでフィルタリングできます。出力結果はCSV、JSON形式に対応しています。
JOINには対応していないため複雑なクエリを扱う場合はAmazon Athenaを利用することになります。
検証概要
.NET SDKからAmazon S3 Selectを利用してみます。 以下が今回作成したプログラムの流れです。
- CSVファイルの作成
- S3アップロード
- S3 Selectを実行
それでは早速作ってみましょう。
やってみた
C#(.NET6)で開発していきます。Windows環境を前提にしています。
S3バケット作成、権限・認証情報の設定は説明を省略します。
プロジェクト作成
Visual Studioから以下の手順でプロジェクトを作成しました。
「新しいプロジェクトの作成」を選択
⇒ 「コンソールアプリ」を選択
⇒ プロジェクト名を入力
⇒ フレームワークに「.Net 6.0」を選択 「最上位レベルのステートメントを使用しない」にチェック
パッケージのインストール
NuGetでAWSSDK.S3をインストールします。
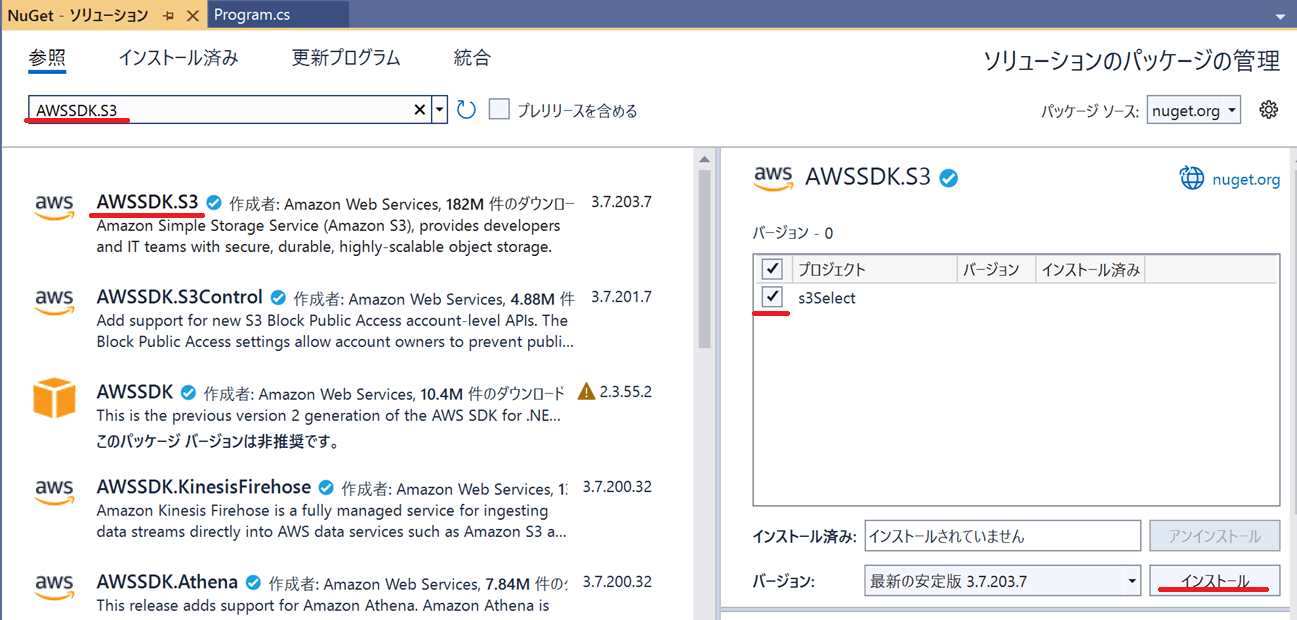
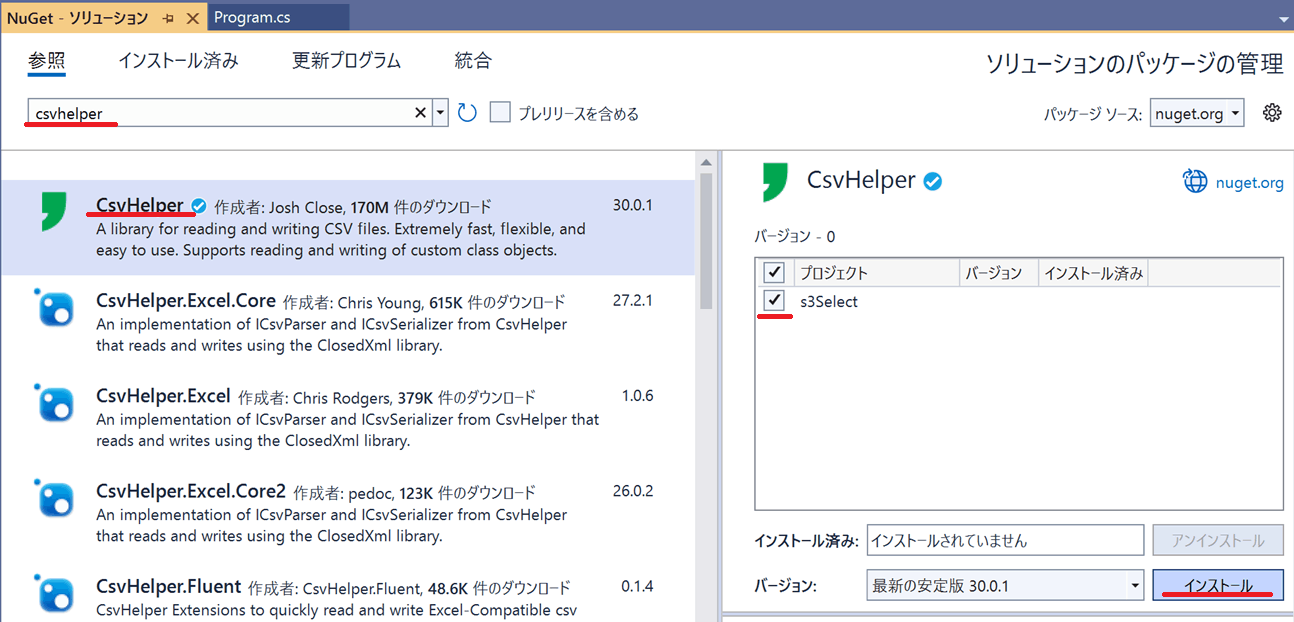
また、CSVを扱うためCsvHelperもインストールします。
CSVファイルの作成
テスト用のCSVファイルを作成します。CsvHelperのCsvWriterでCSVファイルを作成します。
データ内にカンマやダブルクォートを混ぜています。
private static void CSV作成()
{
// テスト用データ作成
var 社員リスト = new List<社員>
{
// カンマが含まれているデータ
new 社員{Id=1, 支店=支店.東京, 役職="課長", 社員名="一,郎"},
// シングルクォートが含まれているデータ
new 社員{Id=2, 支店=支店.東京, 役職="社員", 社員名="次'郎"},
// ダブルクォートが含まれているデータ
new 社員{Id=3, 支店=支店.東京, 役職="課長", 社員名="三\"郎"},
// 改行が含まれているデータ
new 社員{Id=4, 支店=支店.大阪, 役職="社員", 社員名=$"四{Environment.NewLine}郎"},
new 社員{Id=5, 支店=支店.大阪, 役職="課長", 社員名="五郎"},
};
// CSVに書き込み
using var sw = new StreamWriter(_fileName);
using var csv = new CsvWriter(sw, CultureInfo.InvariantCulture);
csv.WriteRecords(社員リスト);
}
CSVデータ構造は下記のクラスを定義しています。
IndexでCSVのカラム位置、NameでCSVのカラム名を指定しています。
public class 社員
{
[Index(0)]
[Name("id")]
public int Id { get; set; }
[Index(1)]
[Name("branch")]
public 支店 支店 { get; set; }
[Index(2)]
[Name("post")]
public string 役職 { get; set; } = null!;
[Index(3)]
[Name("name")]
public string 社員名 { get; set; } = null!;
}
public enum 支店 { 東京, 大阪, }
S3アップロード
AWSSDK.S3のTransferUtilityを使用してアップロードします。
private static void S3アップロード()
{
var s3Client = new AmazonS3Client();
var fileTransferUtility = new TransferUtility(s3Client);
fileTransferUtility.Upload(_fileName, _bucketName, _keyName);
}
Amazon S3 Select
ここからが本題です。SDKのSelectObjectContentAsyncメソッドでクエリを実行します。
入力形式、出力形式ともにCSVとしています。オプションの詳細はソースコメントに記載しています。
結果の取り出しにはCsvReaderのGetRecordsを使用し、オブジェクトにパースしています。
private static async Task S3Select()
{
var config = new CsvConfiguration(CultureInfo.InvariantCulture)
{
HasHeaderRecord = false,
};
using var eventStream = await GetSelectObjectContentEventStream();
foreach (var ev in eventStream)
{
if (ev is RecordsEvent records)
{
using var reader = new StreamReader(records.Payload, Encoding.UTF8);
using var csv = new CsvReader(reader, config);
var 社員リスト = csv.GetRecords<社員>();
foreach (var 社員 in 社員リスト)
{
Console.WriteLine($"{社員.Id} {社員.支店}支店 {社員.役職} {社員.社員名}さん");
}
}
}
}
private static async Task<ISelectObjectContentEventStream> GetSelectObjectContentEventStream()
{
var s3Client = new AmazonS3Client();
var query = "select * from S3Object s where s.id <= '4'";
var response = await s3Client.SelectObjectContentAsync(new SelectObjectContentRequest()
{
BucketName = _bucketName,
Key = _keyName,
ExpressionType = ExpressionType.SQL,
Expression = query,
InputSerialization = new InputSerialization()
{
// 入力形式はCSVを指定
CSV = new CSVInput()
{
// ヘッダあり
FileHeaderInfo = FileHeaderInfo.Use,
// 改行コードを指定
RecordDelimiter = Environment.NewLine,
// データ内に改行が含まれる場合はtrueを指定するがパフォーマンスが落ちる
// 改行考慮が不要の場合はデフォルト(指定なし)のままで良い
AllowQuotedRecordDelimiter = true,
}
},
OutputSerialization = new OutputSerialization()
{
// 出力形式はCSVを指定
CSV = new CSVOutput()
{
// 出力フィールドを常に引用符で囲む
QuoteFields = QuoteFields.Always,
}
}
});
return response.Payload;
}
実行結果
カンマやダブルクォート、改行も取り出せています。

まとめ
テーブルの古いデータは削除したいが、まれに過去にさかのぼって検索したい場合などに使ってみようと思います。他にもシステム間のデータ連携で使えそうですね。
(おまけ)GZIP形式にも対応している
GZIP形式でも検索できるようなので、試してみました。
CSVの作成個所でGZipStreamを通すよう修正しました。
- using var sw = new StreamWriter(_fileName);
+ using var fs = new FileStream(_fileName, FileMode.Create);
+ using var gs = new GZipStream(fs, CompressionLevel.Optimal);
+ using var sw = new StreamWriter(gs);
using var csv = new CsvWriter(sw, CultureInfo.InvariantCulture);
csv.WriteRecords(社員リスト);
また、SelectObjectContentRequestでCompressionType.Gzipを指定します。
var response = await s3Client.SelectObjectContentAsync(new SelectObjectContentRequest()
{
BucketName = _bucketName,
Key = _keyName,
ExpressionType = ExpressionType.SQL,
Expression = query,
InputSerialization = new InputSerialization()
{
// 入力形式はCSVを指定
CSV = new CSVInput()
{
// ヘッダあり
FileHeaderInfo = FileHeaderInfo.Use,
// 改行コードを指定
RecordDelimiter = Environment.NewLine,
// データ内に改行が含まれる場合はtrueを指定するがパフォーマンスが落ちる
// 改行考慮が不要の場合はデフォルト(指定なし)のままで良い
AllowQuotedRecordDelimiter = true,
},
+ // GZIP形式を指定
+ CompressionType = CompressionType.Gzip,
},
OutputSerialization = new OutputSerialization()
{
// 出力形式はCSVを指定
CSV = new CSVOutput()
{
// 出力フィールドを常に引用符で囲む
QuoteFields = QuoteFields.Always,
}
}
});
実行すると同様の結果が得られました。
Discussion