🙂
機械学習でよく使うPandasを使ったデータのフィルタリング



Pandasは、Pythonのデータ分析において最も人気のあるライブラリの一つで、その強力なデータ操作機能を使って、効率的にデータをフィルタリングすることができます。
機械学習でよく使う処理をまとめておきます。
1. 特定の値に基づくフィルタリング
特定の値や条件に一致する行のみを選択します。
import pandas as pd
filtered_df = df[df['column'] == value]
たとえば下記のような日付とタイプをまとめたデータ【test_df】を使って処理を行うとします。
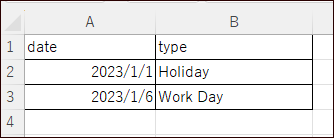
タイプが"Work Day"のデータのみ取り出す場合は、次のようにします。
import pandas as pd
filtered_test_df = test_df[test_df['type'] == 'Work Day']
2. 複数の条件に基づくフィルタリング
複数の条件を組み合わせてフィルタリングします。&(AND)や|(OR)を使用します。
import pandas as pd
filtered_df = df[(df['column1'] > value1) & (df['column2'] < value2)]
3. 欠損値の除外
欠損値(NaN)を含む行を削除します。
import pandas as pd
filtered_df = df.dropna()
4. 重複値の除外
重複する行を削除します。
import pandas as pd
filtered_df = df.drop_duplicates()
5. 特定の範囲内の値に基づくフィルタリング
値が特定の範囲内にある行のみを選択します。
import pandas as pd
filtered_df = df[df['column'].between(value1, value2)]
6. 文字列操作によるフィルタリング
特定の文字列パターンに一致する行を選択します(例えば、文字列が特定の文字で始まる場合など)。
import pandas as pd
filtered_df = df[df['column'].str.startswith('prefix')]
Discussion