データマージ後にMemoryError: Unable to allocateと出たら複数列を使って結合してみて
Pandasライブラリの merge 関数は、異なるデータベースを結合するためによく使用されます。非常に便利な機能ですが、大規模なデータセットを扱う際には、この結合操作がメモリの問題を引き起こす可能性があります。
わたしは結合方法を間違えて、次のようなエラーが表示されました^^;
MemoryError: Unable to allocate 1.11 GiB for an array with shape (148779180,) and data type int64
結合方法を変えたところ、修正できました。どのように結合方法を変えたかを説明します。
結合方法の見直し
例として次の2つのデータベースを結合するとします。
train_df

dealings_df
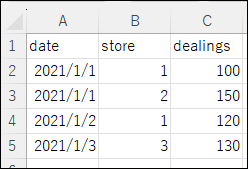
結合方法① 1つの列をキーとして使用して2つのデータフレームを結合
date 列をキーとして使用して2つのデータフレームを結合しています。
train_df = pd.merge(train_df, dealings_df, on='date', how='left')
【結合後】

データ量が多くなければ、下記のように結合しても問題は出ません。ですが、dealings_df に同じ date が多数存在する場合、メモリ使用量が膨大になる可能性があります。
結合方法② 2つの列をキーとして使用して2つのデータフレームを結合
date と store列をキーとして使用して2つのデータフレームを結合しています。
train_df = pd.merge(train_df, dealings_df, on=['date', 'store'], how='left')
【結合後】

この変更により、マージ操作は date と store の両方の列で一致する行に限定されます。結合される行の数を大幅に削減し、結果的にメモリの使用量を減少させます。
なぜ2つ目の方法が効果的なのか?
2つ目の方法でメモリを減少させた理由をもう少し詳しく説明します。
結合方法①では、date 列のみを使用して結合しています。各日付に対して dealings_df 内のすべての行が考慮され、結果として得られるデータフレームが非常に大きくなる可能性があります。
一方、結合方法②ではdate と store の両方をキーとして使用することで、より厳密なマッチング条件が設定され、必要な行のみが結合されます。
他のメモリを減らす方法
なお上記の方法は、データによっては使えません。その場合は次のような方法でメモリを減らすことができます。
-データ型を見直し:
例えば、数字のデータ型int64 を int32 や int16 に変更するなどです。
-データのダウンサンプリング:
サンプリングすることでデータ量を減らします。ランダムに行を選択するか、特定の期間のデータのみを使用するなどです。
-不要な列の削除:
結合前に不要な列を削除して、データフレームのサイズを小さくします。
Discussion