Open9
ML/DL周り メモ
BatchNormalization
What
NNの各層への入力を正規化する手法
観測する限り一般的にはDropoutとの組み合わせが優れているらしい
How to work
- バッチ内の要素ごとに平均と標準偏差を算出
- 畳み込み->チャンネル
- 全結合層->ユニット
- 入力から対応するチャンネルの平均値をひき、標準偏差(+0で割らないための補正項)で割って正規化
- それをアフィン変換
Advantage
内部共変量シフトを減らすため?(それを否定する論文も出ていて諸説あり)
- 高い学習率が設定可能になる
- 正則化がかかる
- 精度が向上する
- 重みの初期化影響軽減
共変量シフトとは
Dataset Shift(TrainとTestで入力データの分布が異なる状況)際に現れる症状の一つ。
独立変数の分布が変化することを指して、潜在変数の状態変化・時間変化・空間変化と行った原因がある。もっと簡潔に言うとデータの分布が変化することで変な予測をしてまう状況のパターンの一つ。
基本的にはTrain→Testで発生する(もしくは逆)の問題で、入力に対する条件付き分布自体は変わっていない。数式で表すとこう言うこと。
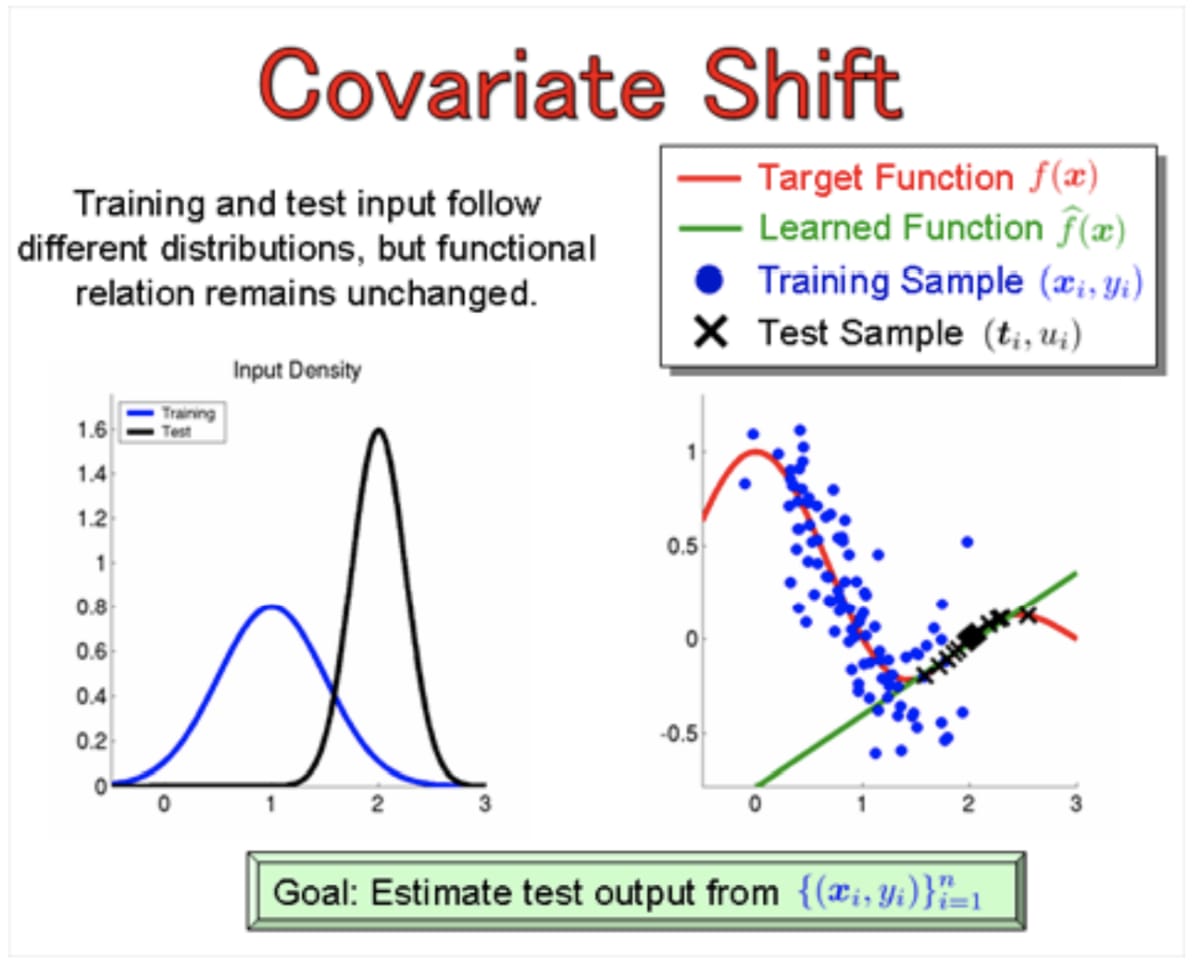
予測自体には問題ないケースも多いが、Cross-validationで悪影響がある。
(基本Cross-validationnのほとんどのバイアスはこの共変量シフトのせいらしい)
i.e) 小さい値ばかりのデータで学習させ、大きなデータがいっぱいのテストデータを予測させると共変量シフトのせいでぱっと見スコアがとても悪くなる
- 内部共変量シフト: 訓練中にネットワーク内の各層の間で起きる共変量シフト
出典
EDA用
- pandas-profiling
- sweetviz
事前学習済みNLPモデルってどうやって探すの
huggingface
テキストデータの取扱
前処理⇨Vectorize
前処理
- 文章の意味分析では`I`や`you`と言った一般的に頻出な単語を除く(ストップワードと呼ばれる)
- 記号や数字を取り除く
- 大文字小文字を全て小文字にする
- 前処理用ライブラリの[texthero](https://github.com/jbesomi/texthero) を使う
Vectorize
- BERT使う
- https://www.kaggle.com/vbookshelf/basics-of-bert-and-xlm-roberta-pytorch - TF-IDF使う
- 文章ごとの単語の出現回数を文章集合の起床どで掛け合わせた特徴量
- Bag of wordの発展系
- 基本はカウントだけなので単純だが、事前学習などが不要で手軽に試せて場合によってはかなり性能がでるのでベースラインとして最適
-
Okapi BM25
- TF-IDFの情報に加えて文章に含まれる総単語数の情報(DL値)を用いる
- ※ただしIDFの算出式がTF-IDFと異なる
ref
言語判定ってどうやるの
- fastText
- pycld2
ref
1対多のテーブル・データってどう扱うの
- One-hotベクトル化
-
Word2Vec
- window幅を大きく取るとトピック、せまくすると文法を学習できると言われている
- 過学習しちゃうケースもありがちなのでベースラインに入れておくと闇の特徴量として見落とす可能性がある
特徴量の減らし方は?
意味のないものを削る
- 値が全部0,同じ
- 他の特徴量と完全相関のもの
コンペ開始直後にいつもやること
- 全カラムの統計量を取る(min,max,mean,std,number of uniquness etc.)
- top10のvalueを調べる
- feature vs target の分布
- カテゴリ vs target (bar plot etc.)
- ベン図でtrainとtestでラベルがどれくらい共通しているか