手を動かしながら学ぶクリーンアーキテクチャ
こんにちは。
私は今、実務でクリーンアーキテクチャを採用しているサービスのバックエンド開発に携わっています。クリーンアーキテクチャについてはどれだけ記事を読んでも、分かったような分からないようなといった状態が続いていたのですが、実装をしてみることで理解が深まったような気がしています。
なので今回は自分と同じようにクリーンアーキテクチャについて理解に苦しんでいる人に向けて、手を動かしながらクリーンアーキテクチャを学べるような記事を書きました。
言語はGoを使用していますが、Goは文法がシンプルであるため、Goに親しみがない人でも実装内容は理解できるのではないかと思います。
プログラムはGitHubにて公開しているので、必要であれば見てもらえればと思います。
対象読者
- クリーンアーキテクチャについて記事や書籍を読んでみたけど、いまいち理解できていない人
- クリーンアーキテクチャの概念は理解しているけど、それをどう実装するのかに悩んでいる人
- クリーンアーキテクチャを理解するだけでなく、実装できるようになりたい人
クリーンアーキテクチャ概要
クリーンアーキテクチャについて調べると必ずと言っても良いほど目にするのが次の画像です。
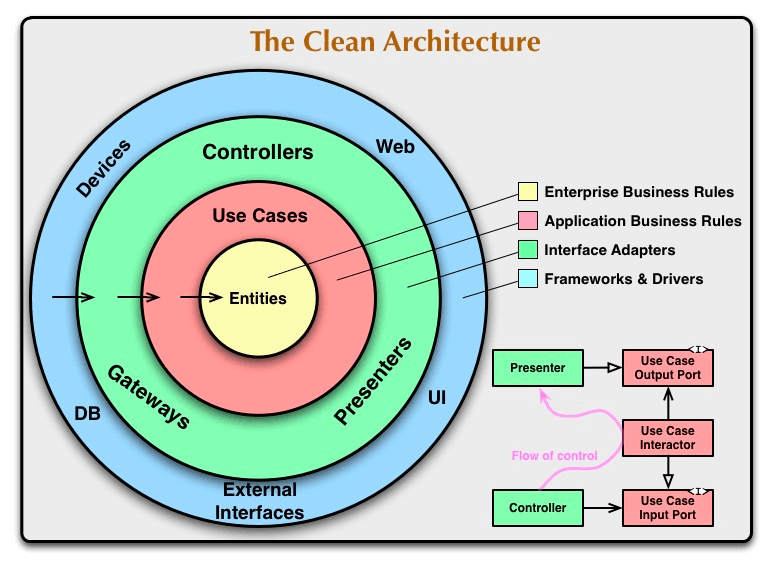
クリーンアーキテクチャで実現したいことは「関心の分離」です。
「関心の分離」によって、テストがしやすく、変化に柔軟に対応できるアプリケーションを構築することができます。
クリーンアーキテクチャでは
- レイヤーに分割する
- 依存関係にルールを持たせる
ことで、「関心の分離」を実現します。
レイヤーの分割に関しては抽象度別にレイヤーを分割します。依存関係のルールに関しては、具体的で抽象度の低い(下位の)レイヤーが抽象度の高い(上位の)レイヤーに依存するようにします。
図に沿って説明すると、一番外側のレイヤ―が最も抽象度が低く、一番内側が最も抽象度が高くなっており、外側から内側のレイヤーに向けての依存のみを許可するのがクリーンアーキテクチャです。
制作物について
今回は極めてシンプルなブログアプリケーションをクリーンアーキテクチャに沿って作成します。記事の作成、閲覧、更新、削除といったCRUD処理を実装したいと思います。
プロジェクトのファイル・ディレクトリ構成は以下の通りです。
C:.
│ .gitignore
│ compose.override.yml
│ compose.override.yml.sample
│ compose.yml
│ Dockerfile
│ go.mod
│ go.sum
│ LICENSE
│ main.go
│ Makefile
│ README.md
│ schema.sql
│ sqlboiler.toml
├─.github
│ │ dependabot.yml
│ └─workflows
│ lint.yml
│ test.yml
├─adapter
│ ├─controller
│ │ article.go
│ ├─gateway
│ │ article.go
│ └─presenter
│ article.go
├─driver
│ db.go
│ router.go
├─entities
│ articles.go
│ boil_queries.go
│ boil_table_names.go
│ boil_types.go
│ boil_view_names.go
│ mysql_upsert.go
└─usecase
├─interactor
│ article.go
├─port
│ article.go
└─repository
article.go
まずアプリケーションの動作を確認したいという方は、
> git clone https://github.com/JunNishimura/clean-architecture-with-go
> cd ./clean-architecture-with-go
> make init
> make up
でアプリケーションを動かした後、curlコマンドを使ってAPIを叩いてもらえればと思います。
> curl -i -XPOST -d '{"title": "test", "body": "this is a test article"}' localhost:8080/articles
> curl -i -XGET localhost:8080/articles
> curl -i -XGET localhost:8080/articles/1
> curl -i -XPUT -d '{"title": "updated title", "body": "this article is updated"}' localhost:8080/articles/1
> curl -i -XDELETE localhost:8080/articles/1
Entities
一番内側のEnterprise Business Rulesと書かれているこのレイヤーではコアとなるビジネスロジックを実装します。
このレイヤーは図から見て取れるように、他のどのレイヤーにも依存してはいけません。他のレイヤーに依存しなくなることで、このレイヤーの安定性が増します。
今回はSQL BoilerというORMライブラリを利用して、コードを生成しています。
MySQLコンテナを立ち上げた後、次のSQLを実行してテーブルを作成します。
CREATE TABLE `articles` (
`id` bigint NOT NULL AUTO_INCREMENT,
`title` varchar(255) NOT NULL,
`body` text NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
その後に以下のsqlboilerコマンドを実行するとコードが自動生成されます。
> sqlboiler mysql -c sqlboiler.toml -o entities -p entities --no-tests --wipe
コマンドに出てくるsqlboiler.tomlの中身は以下のようになっています。
[mysql]
dbname = "db"
host = "localhost"
port = "3306"
user = "user"
pass = "password"
sslmode = "false"
Usecases
ビジネスロジックのAPIを記述することで、このソフトウェアは何を実現するのかを表現するのがこのレイヤーです。
Usecaseはinteractor, port, repositoryで構成されています。portとrepositoryは下位レイヤーのインターフェースになっています。具体的には、inputPortがcontroller、outputPortがpresenter、repositoryがgatewayのインターフェースになっています。
まずportで入力と出力のインターフェースを定義します。
repositoryでは一つ下のレイヤーのgatewayのインターフェースを定義します。
interactorはoutputPortとrepositoryを使って、インターフェースであるinputPortを満たすように実装します。
Interface & Adapters
入力(controller)、出力(presenter)、データ永続化処理(gateway)を記述するレイヤーです。
controllerはゲームのコントローラーと同じようにユーザーからの入力を解釈・変換しユースケースに伝えます。各メソッドはhttp.HandlerFunc型を満たすように引数として、ResponseWriterと*Requestを受け付けています。
gatewayではDBとのやり取りを記述します。
presenterでは出力に関する定義を記述します。ここではレスポンスをJSON形式に変換して出力しています。
Frameworks & Drivers
このレイヤーではDBのコネクション確立やルーティングの設定、フレームワークの利用を記述します。
DBにはMySQLを、ルーティングにはchiというライブラリを使用しています。
まとめ
今回は極めてシンプルなアプリケーションをクリーンアーキテクチャで構築しました。実務などではドメインの数も増えてもっと複雑になるかと思いますが、今回のハンズオンを通じて少しでもクリーンアーキテクチャでアプリケーションを構築するイメージが沸いていただければ幸いです。
冒頭でも述べましたがクリーンアーキテクチャで重要なのは「関心の分離」であり、その実現方法は明確に定義されていません。あくまで今回の実装はクリーンアーキテクチャの一例なので、もし読者の皆様がクリーンアーキテクチャを実装する際は、自分の作りたいソフトウェアに応じて最適な実装方法を模索して頂ければと思います。
その際に今回のサンプルが役に立てば私としては嬉しい限りです。
参考文献
記事
Discussion