GraphQLの基本を掴む
はじめに
近年、Web開発の世界でGraphQLという技術が、API設計の新しい標準として注目を集めています。これは、従来の主流であったREST APIが抱える「必要なデータだけを取得できない」という課題を解決するために開発されました。
本記事で分かること
- GraphQLとは何か
- 基本概念
- GraphQLと従来のAPIと比較した利点
GraphQLとは何か
GraphQLは、APIのためのクエリ言語であり、サーバー側でそのクエリを処理するための実行環境でもあります。
従来のAPIが「事前に決められたデータをすべて渡す」方式だったのに対し、GraphQLの核心は、「クライアントが必要なデータとその構造を正確に宣言(クエリ)する」点にあります。
基本的な構造
- クライアント主導:データを要求するクライアント側(フロントエンド)が、取得したいフィールドを正確に指定します。
- 単一のエンドポイント:通常、GraphQLサーバーは/graphqlのような単一のHTTPエンドポイントを持ちます。すべてのデータ操作はこの単一の窓口を通じて行われます。
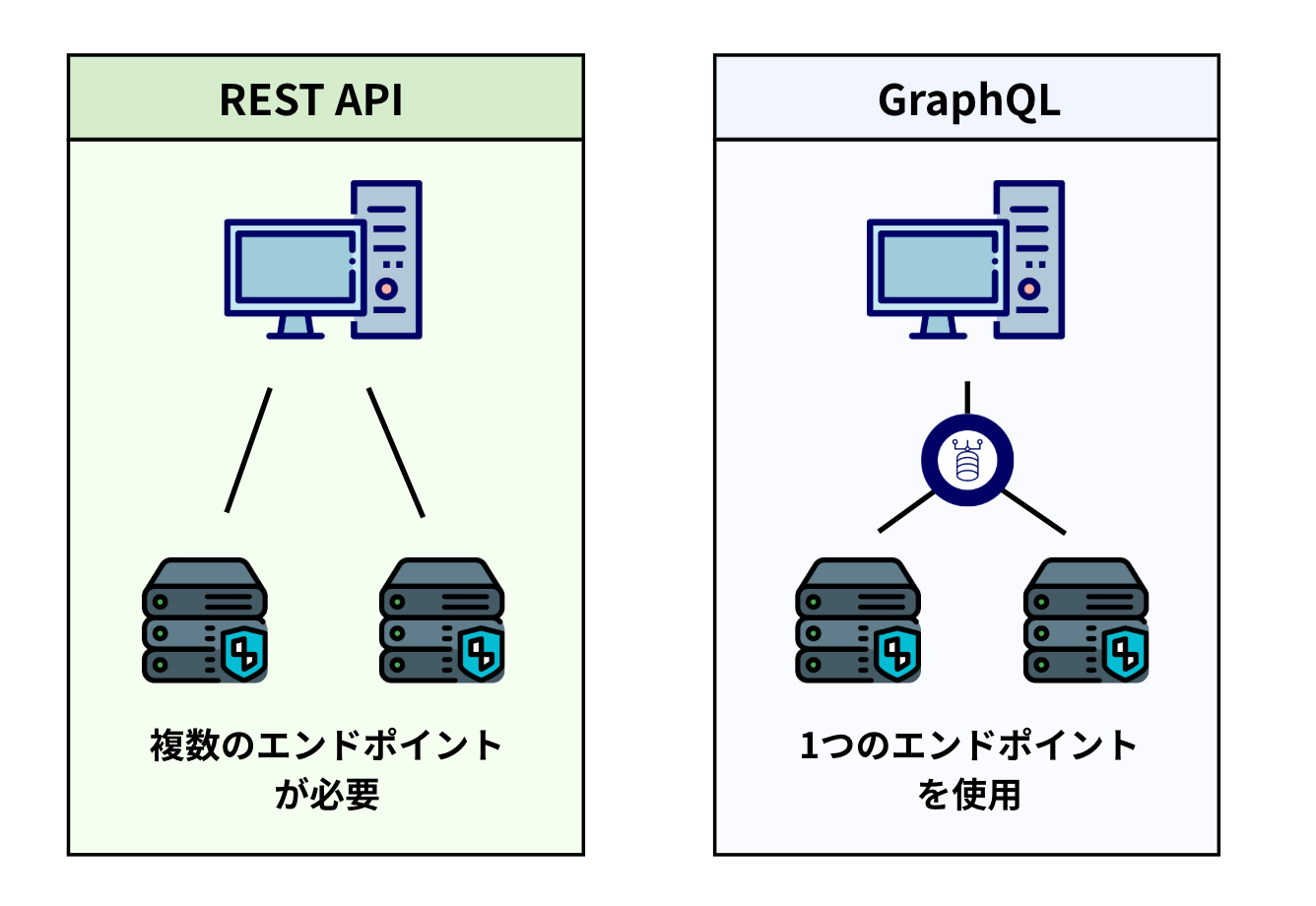
Web APIの標準:REST APIの基本
GraphQLが解決しようとする課題を理解するために、現在の主流であるREST APIの仕組みを確認します。
REST APIは、インターネット上でリソースをやり取りするためのシンプルで統一された設計原則です。リソースを専用のURLで識別し、HTTPメソッド(GET、POSTなど)を使って操作します。
- リソース:操作したいデータの単位(例:記事)
-
エンドポイント:リソースにアクセスするためのURL(例:
/post/123) -
HTTPメソッド:行いたい操作(例:
GETで取得)
GraphQLとREST APIの決定的な違い
GraphQLがなぜ登場したのかを理解するには、REST APIの一般的な課題を知る必要があります。
データの過剰取得
クライアントがほしいデータが一部であっても、サーバーが定義したすべてのフィールドが返されます。これにより、ネットワーク帯域が無駄になります。
リクエストの多発
関連する複数のリソース(例:ユーザー情報と、そのユーザーが書いた記事一覧)を取得するために、クライアントが何度も別々のAPIエンドポイントを叩く必要があります。
GraphQLによる解決
GraphQLは、クライアントがネストされたデータ構造を含めて一度のクエリで要求できるため、これらの問題を解決します。
| REST API | GraphQL | |
|---|---|---|
| データ取得法 | サーバーが定義した構造をすべて返す | クライアントが必要なフィールドだけを正確に指定する |
| エンドポイント数 | リソースごとに異なるURL | 単一のURL |
| リクエスト回数 | 複数の関連データを取得するのに複数回必要 | 複雑な関連データも一度のリクエストで取得可能 |
GraphQLの根幹:スキーマと型システム
GraphQLが柔軟なクエリを可能にするのは、その核となるスキーマと型システムのおかげです。
スキーマ
「このAPIがクライアントに提供できるデータのすべて」を厳密に定義する設計図です。これは、APIの「契約書」のようなものであり、クライアントはスキーマに書かれている型とフィールドの範囲内でのみクエリを作成できます。
- 定義: スキーマは、GraphQL独自のスキーマ定義言語 (SDL: Schema Definition Language) を使って記述されます。
-
型の定義: スキーマには、
User型など、返されるデータ構造の型が定義されます。
スキーマの例
# ユーザーのデータ構造を定義
type User {
id: ID! # 一意な識別子 (必須)
name: String # ユーザーの名前
email: String # メールアドレス
isOnline: Boolean! # オンライン状態
lastSeen: String # 最終アクセス時刻
}
GraphQLの主要な3つの操作
GraphQLでデータを操作する基本tけいな方法には、主に以下の3種類があります。
Query(クエリ)
- 役割:データの読み出しを行います。
- 特徴:クライアントが取得したいデータとその構造を宣言する最も基本的な操作です。
クエリの例
このクエリでは、IDが「1」のユーザーの名前とメールアドレスを取得します。
query {
user(id: "1") {
name
email
}
}
Mutation(ミューテーション)
- 役割:データの作成、更新、削除といった書き込み操作を行います。
- 特徴:クエリとは異なり、サーバー上のデータを変更する操作であるため、処理後に変更された新しいデータをクライアントに返すことができます。
Mutationの例
このミューテーションでは、IDが「1」のユーザーの名前を「Tarou」に更新します。
mutation {
update(id: "1", input: { name:"Tarou" }) {
id
name
}
}
Subscription(サブスクリプション)
- 役割:サーバー側のデータの変更をリアルタイム(非同期)でクライアントに通知します。
- 特徴:クエリやミューテーションnが一回限りのリクエスト(HTTP)であるのに対し、サブスクリプションは持続的な接続を確立し、データが更新されるたびにサーバーからクライアントへ自動的にプッシュされます。
サブスクリプションの例
このサブスクリプションでは、IDが「1」のユーザーのステータス(オンライン/オフライン)が変更された時に、変更後のステータスを取得します。
subscription userStatusChanged {
userStatus(id: "1") {
id
isOnline
lastSeen
}
}
データの柔軟な指定:Argument(引数)
GraphQLクエリの柔軟性を高めるのがArgument(引数)です。Argumentを使うことで、クライアントは単にリソース全体を要求するのではなく、フィルタリングや条件を指定してデータを取得できます。
- 役割:フィールドに渡されるパラメータで、取得するデータを絞り込んだり、条件をつけたりするために使われます。
-
実装:Argumentは、フィールド名の後に
()を使って記述されます。
Argumentの具体例
先ほどのクエリ例では、user フィールドに対して id というArgument(引数)を渡し、「IDが '1' のユーザー」という条件を指定しています。
query {
# userフィールドにid="1"という引数を渡している
user(id: "1") {
name
email
}
}
GraphQLのメリット
-
開発効率の向上と型の保証
厳格なスキーマがあるため、クライアント側はクエリ作成前に返されるデータ構造を正確に知ることができ、データの型の不一致によるバグを防げます(型安全)。これにより、クライアントとサーバー間の連携がスムーズになり、開発速度が向上します。 -
APIの非破壊的な進化
クライアントは必要なフィールドだけを取得するため、サーバー側が既存のフィールドを残したまま新しいフィールドを追加しても、クライアント側に破壊的な変更(Breaking Change)が発生しません。APIのバージョンアップが容易になります。
GraphQLのデメリット
-
ファイルキャッシュの複雑化
GraphQLは通常、単一の /graphql エンドポイントへのPOSTリクエストを使用するため、HTTPの標準的なキャッシュ機能(ブラウザキャッシュやCDNなど)が効きにくくなります。カスタムのキャッシュ戦略を実装する負担が発生します。 -
サーバー側の実装の複雑性
複雑なクエリ(ネストや複数の引数)に対応するため、データソース(データベース、他のマイクロサービスなど)からデータを収集・統合するロジックの実装が、REST APIと比べて複雑になる傾向があります。
まとめ
- GraphQL = クライアントが必要なデータだけを正確に宣言できるクエリ言語
- データの過剰取得や多重リクエストといったREST APIの課題を解決
- スキーマでAPIの契約を定義し、Query、Mutation、Subscriptionの3つの操作で読み出し、書き込み、リアルタイム通信を実行
Discussion