🚀
初めてのAmazon Glue ~概要編~
Amazon Glueとは?
フルマネージドのETL(Extract・Transform・Load)サービス。様々なデータソースからデータを収集・変換し、保存先にロードする一連の処理を自動化可能。
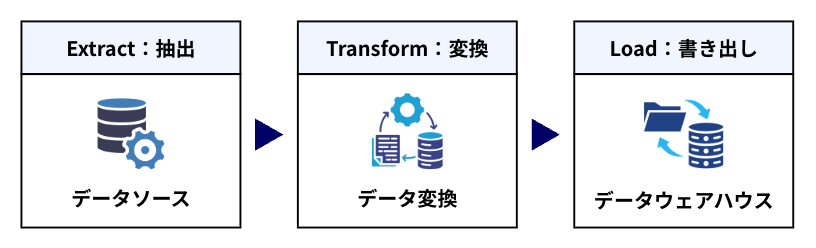
主な特徴
| 特徴 | 説明 |
|---|---|
| フルマネージド | インフラの管理不要。スケーラブルなETL環境が即時利用可能 |
| サーバーレス | サーバーのプロビジョニング不要。実行時のみ課金。 |
| 多様なデータソース対応 |
S3、RDS、Redshift、DynamoDBなど |
| 自動スキーマ推論 |
Glue Crawlerでデータ構造を自動認識 |
| ジョブの管理 |
PythonやSQLでETL処理を記述可能 |
Glueの構成要素

①Glue Crawler(クローラー)
データソースを自動でスキャンし、スキーマ情報を推論して、Glue Data Catalogに登録。
- JSONやCSVなど
構造化/半構造化データにも対応 -
定期実行やスケジュール設定も可能 - 新しいファイルを自動認識して、テーブルに反映可能

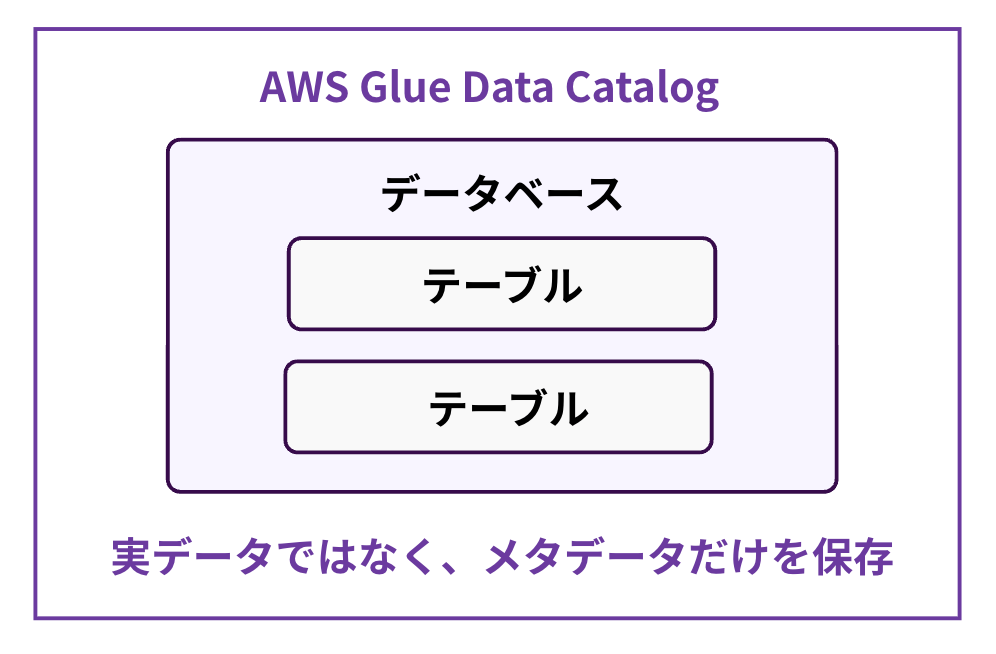
②Glue Data Catalog(データカタログ)
データソースのメタデータ(テーブル名、カラム名、データ型、位置など)を管理する中央リポジトリ。
- 1つのカタログに複数のデータソースをまとめて管理可能
-
Athena、Redshift Spectrum、EMRなど他サービスと連携してクエリ可能 - Crawlerが自動作成する or 手動で定義も可能
③Glue Job(ジョブ)
ETL処理を定義し、実行する本体。PySpark、Python、SQLから選択可能
- ノーコードUI(
Glue Studio)でも作成可能 - 並列処理、パーティション分割も対応
- DPU(Data Processing Unit)単位でスケーリング
DPUとは?
Glueジョブが使う「処理パワーの単位(CPU+メモリ)」のこと。
AWS Glueでは、サーバーを自分で立ち上げる必要がない代わりに、AWSが用意した仮想的な処理リソースを使ってETL処理を行う。
その処理能力の単位が「DPU(Data Processing Unit)」
④Glue Trigger(トリガー)
ジョブやCrawlerを自動実行するスケジューラー・トリガー制御。
- 時間ベース(cronスケジュール)や、イベントベース(他ジョブの成功時)で起動
- DAG(依存関係グラフ)を組み込むことで複雑なETLパイプラインを構築可能
⑤Glue Studio
ジョブをビジュアルに設計・編集・実行・モニタリングできるGUIツール。
- ノーコード/ローコードでデータフローを定義可能
- データのプレビューや中間ステップでの検証も可能
- SQLベースのJob開発もサポート

例
「ソース(S3)→ 選択 → フィルター → 型変換 → 出力先(S3)」のような処理をドラッグ&ドロップで作成可能。
⑥Glue Workflow
トリガーやジョブ、クローラーなどを一連のフローとしてまとめて管理・可視化可能。
- 複数のGlueリソースを1つのパイプラインとして扱える
- 成功・失敗による分岐処理も可能
- 状態を視覚的に追える(グラフビュー)
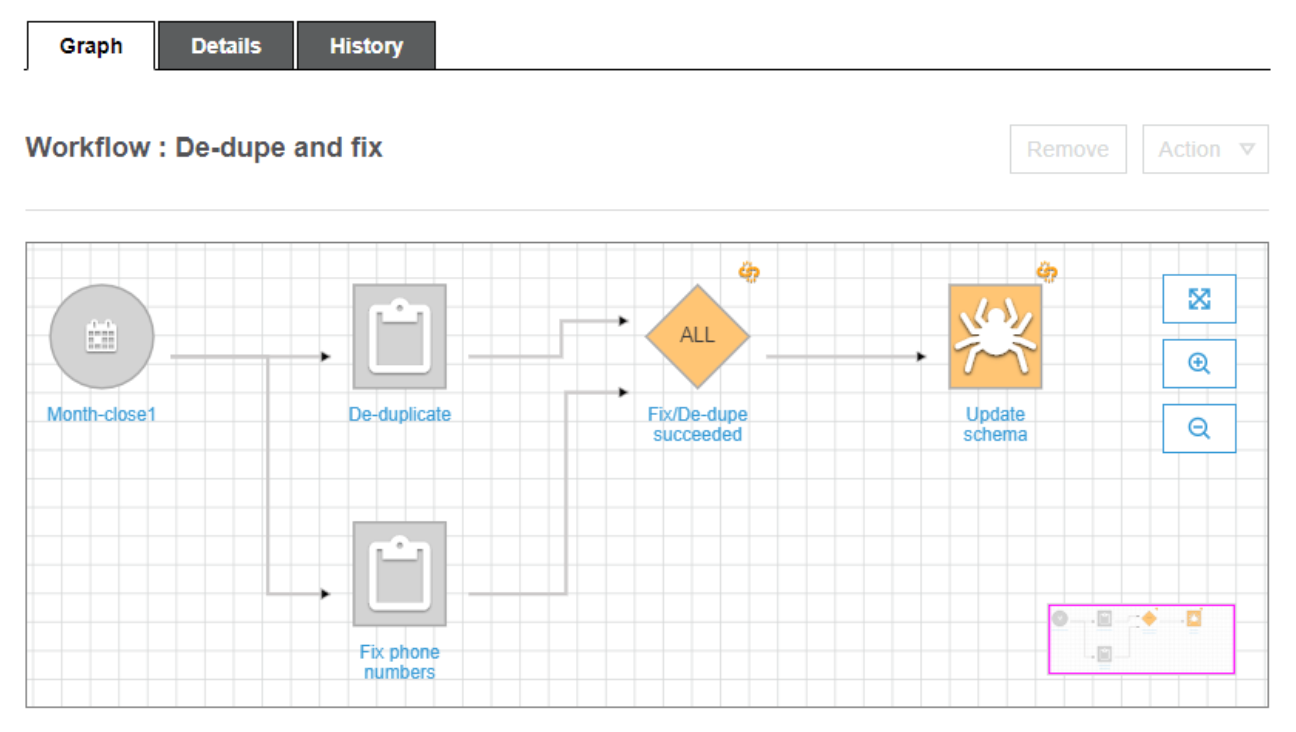
例
「クローラー → ETLジョブ① → 条件分岐 → ETLジョブ② or 終了」といったフローを可視化して実行制御。
簡単なETLの流れ
-
Glue CrawlerでS3などのデータ構造を把握 -
Glue Catalogにスキーマ登録 -
Glue JobでPySparkなどを使って変換処理を記述 - 実行・監視で変換されたデータをS3やRedshiftに出力
課金体系
- 実行したジョブの処理時間(DPU単位)×時間課金
- Crawler実行時間でも課金が発生
- Data Catalogは最初の100万オブジェクトまで無料(以降課金)
他サービスとの違い
| サービス | 特徴 |
|---|---|
| AWS Glue | ノーコードETLに強い、サーバーレス、メタデータ管理可 |
| Amazon EMR | よりカスタマイズ性が高いビッグデータ処理クラスタ |
| Lambda+Step Functions | 軽量ETL処理や分岐ロジックに向く構成 |
まとめ
- AWS Glueは、サーバーレスでETL処理を自動化できるデータ統合サービス。
-
CrawlerやJob、Data Catalogを使って、データを柔軟に変換・管理可能。 - コードでもGUIでも開発可。
Discussion