【Kubernetes】ServiceとEndpoints・EndpointSliceについてしっかりと解説
はじめに
Kubernetesは、コンテナ化されたアプリケーションを自動で配置・管理・スケーリング(拡張)するためのオーケストレーションツール。
この記事を読むべき対象
- Kubernetesのサービスの概要を理解したい人
- Endpoints APIについて理解したい人
- EndpointSlice APIとは何か把握したい人
Kubernetes Serviceとは?
Kubernetes上のクラスタは、アプリケーションを動かす1つまたは複数のコンテナを実行するPod、そしてそのPodを実行する1つ以上のノードで構成されている。
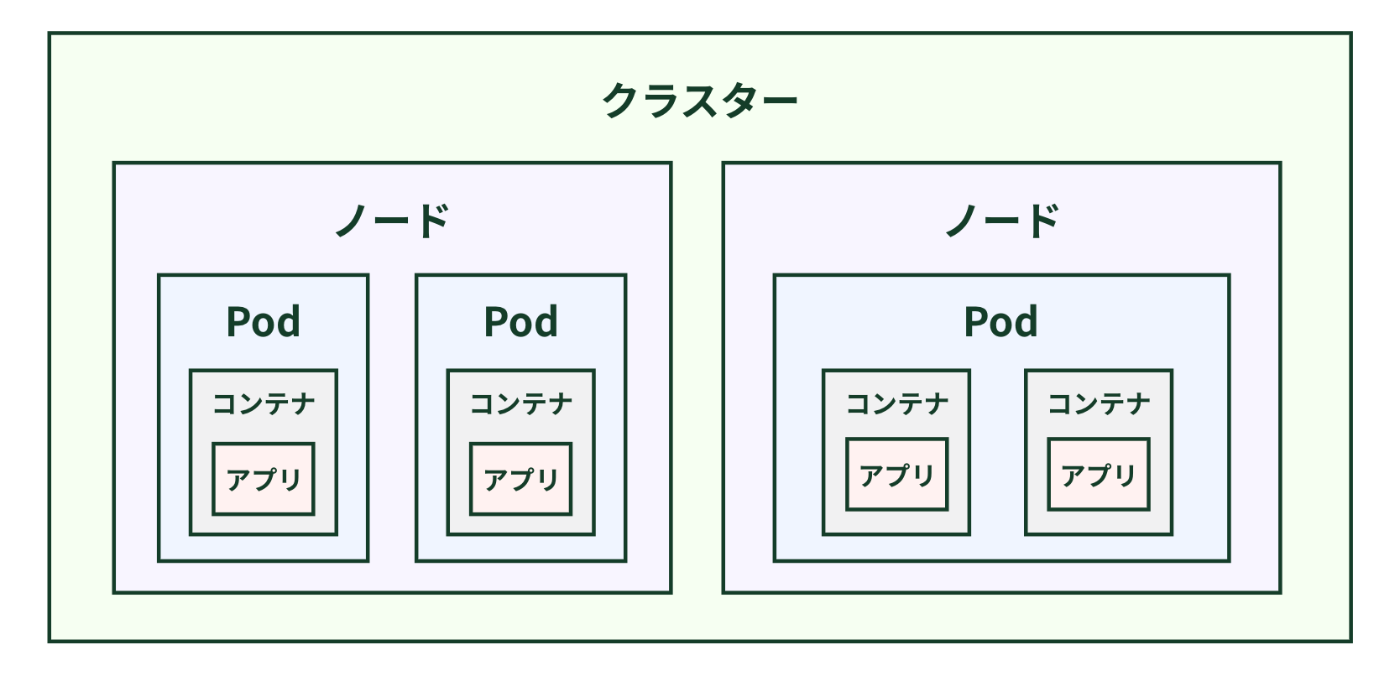
Kubernetesでは、すべてのPodに固有のIPアドレスが割り当てられ、アプリケーションへ直接アクセスできる。
しかし、Podは一時的な存在で、スケーリングや再起動のたびに削除・再作成され、その都度IPアドレスが変わってしまう。
さらにPodに直接アクセスすると負荷分散もできない。
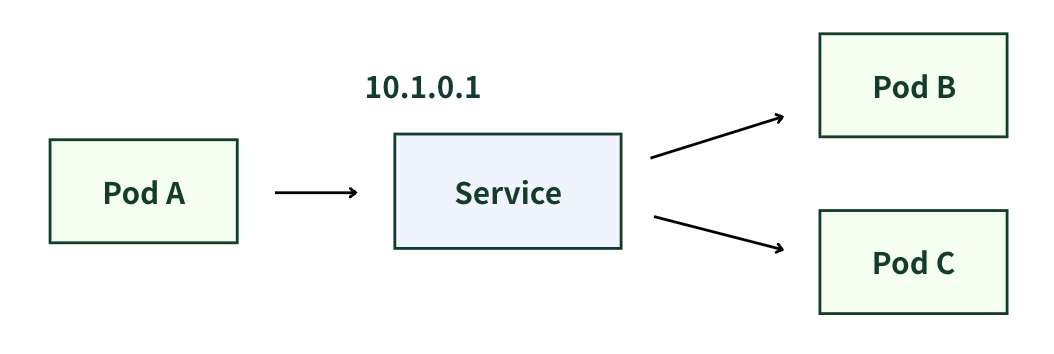
この問題を解決するのがKubernetes Service。
ServiceはPodやノードを抽象化し、アクセス用の固定の仮想IP(固定の入り口のアドレス)を提供する。
これにより、Podの入れ替わりに関係なくアプリケーションへ安定して接続でき、同時に負荷分散も実現。

Seiviceの用途
クラスタ内部での通信
クラスタ内部のPod間での通信に特化しており、外部からアクセスできないため、セキュリティが重要な内部サービス(データベースやマイクロサービスのバックエンドAPIなど)に使用される。
外部との通信
各ノードが特定のポートを解放し、そのポートを経由して外部からサービスにアクセスできるようにする。ノードのIPアドレスとポート番号を知る必要があるため、主に開発やテスト用途で利用される。
負荷分散
外部のロードバランサーを利用してサービスを公開する場合に利用される。ノードのIPアドレスやポート番号を意識する必要はなく、ロードバランサーがトラフィックを適切に分散してくれるため、本番環境での利用に最も適している。
Serviceの4つのタイプ
①ClusterIP(デフォルト)
クラスタ内部での通信を可能にするための設定。クラスタ内でIPアドレスが払い出され、それを利用してPod間で通信を行う。
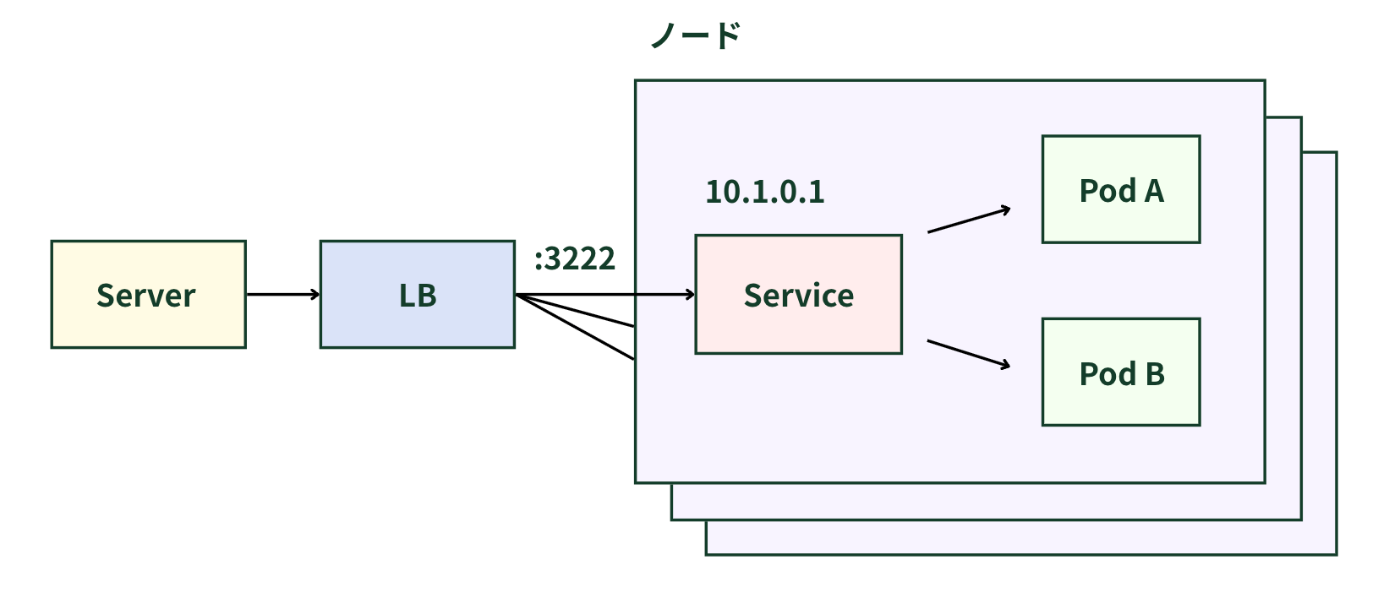
②NodePort
外部からアクセス可能な仮想IPアドレスを、各クラスタノードの静的ポートを介して外部に公開するための設定。
この設定により、クラスタ外からアクセス可能。NodePort設定の際にはCllusterIPも同時に作成される。

③LoadBalancer
NodePortと同様に外部からアクセスするための設定であり、外部のロードバランサを構成する。この設定により、クラスタ外部の負荷分散が可能になり、ノードに障害が発生した場合でもクラスタへのアクセスが維持される。
④ExternalName
Podではなく、外部のDNS名にエイリアスを設定する。
Kubernetesクラスターの外部にあるデータベースやSaaSサービスなど、外部のサービスにアクセスするためのDNSエントリーとして機能する。これにより、アプリケーションのコードを変更することなく、接続先を切り替えることができる。

Enddpointsとは
Serviceに紐づくPodのIPアドレスとポートのリスト。Serviceがトラフィックを転送する先の実際のPodを特定するために使用。
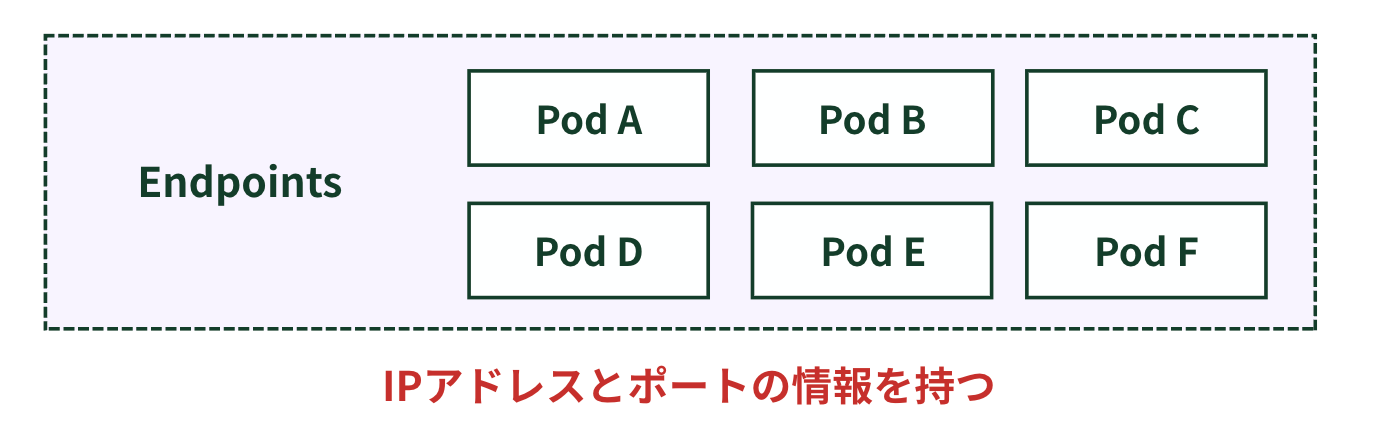
Endpointsの仕組み
自動生成
Serviceを作成し、そのServiceにselector(ラベル)を設定すると、Kubernetesはselectorに一致するラベルを持つすべてのPodを自動的に検出し、そのPodのIPアドレスとコンテナポートからEndpointsオブジェクトを自動的に生成。
Serviceとの関連
EndpointsはServiceと1対1で対応。Serviceにトラフィックが来ると、そのServiceに対応するEndpointsリストを参照し、リスト内のPodにトラフィックを転送。
Podの増減への対応
Podが増減したり、IPアドレスが変わったりするたびに、Endpointsコントローラーがその変更を検知し、Endpointsオブジェクトをリアルタイムで更新。これにより、Serviceは常に利用可能なPodの最新リクエストを把握可能。

Endpointsの用途
① Serviceのトラフィック転送
Serviceがトラフィックを正しいPodにルーティングするために使用される。
②Serviceの抽象化
ServiceがPodのIPアドレスという動的な情報を抽象化し、クライアントに安定したアクセスポイントを提供。これにより、クライアントはPodの変動を意識する必要がなくなる。
EndpointSliceとは
大規模なKubernetesクラスターにおけるServiceのトラフィックルーティングを効率化するために導入された、Podのネットワークエンドポイント(IPアドレスとポート)のグループ化を目的としたリソース。
なぜEndpointSliceが必要なのか
従来のEndpointsオブジェクトは、単一のオブジェクトですべてのPodのエンドポイントを保持していた。しかし、数千ものPodを持つ大規模なServiceでは、この単一のEndpointsオブジェクトが非常に大きくなり、パフォーマンスに問題を起こしていた。以下の課題が存在。
①APIサーバーの負荷
Endpointsは単一の巨大なリストとして存在しており、Podが1つ増減するだけでリスト全体が更新される。この更新が頻繁に起きると、APIサーバーはkube-proxyなどのすべてのクライアントに送信する必要があった。
②クライアント側の非効率性
クライアント(kube-proxyなど)は、APIサーバーから送られてくる情報を利用して、トラフィックルーティングを設定する。例えば、Podが1つ増えた場合でもKube-proxyはIPアドレスが大量にあるリストを受信することになってしまう。
EndpointSliceの仕組み
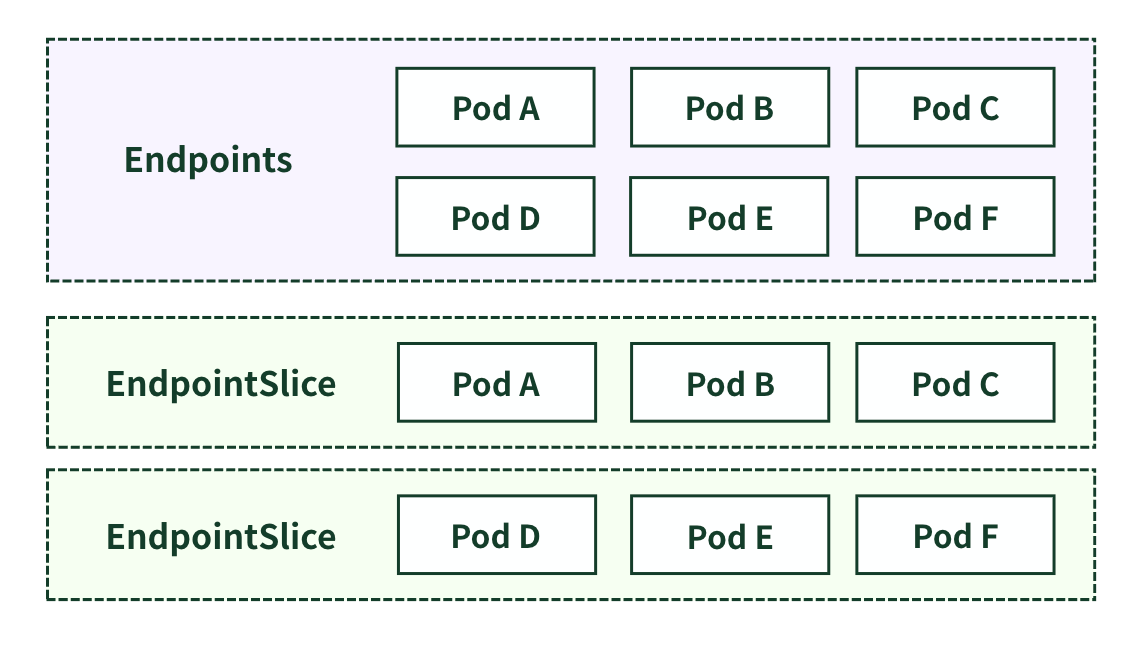
この問題を解決するために、Podのエンドポイントリストを複数の小さなEndpointSliceオブジェクトに分割する。
- グループ化:各EndpointSliceオブジェクトは、最大で約100個のPodエンドポイントを保持する。
- 効率的な更新:PodのIPアドレスやステータスが変更された場合、関連する小さなEndpointSliceオブジェクトのみ更新される。
Endpointsとの比較表
| 特徴 | Endpints | EndpointSlice |
|---|---|---|
| 構造 | 単一のオブジェクト | 複数のオブジェクトに分割 |
| スケーラビリティ | 大規模クラスターでパフォーマンス問題 | 大規模クラスター向けに最適化 |
| 更新 | オブジェクト全体を更新 | 関連する小さなオブジェクトのみを更新 |
まとめ
- KubernetesのServiceは、Podやノードを抽象化し、アクセス用の固定の仮想IP(固定の入り口のアドレス)を提供
- EndpointsはServiceに紐づくPodのIPアドレスとポートのリスト。しかし、大規模なクラスターではリスト全体を更新することからパフォーマンスに問題があった。
- EndpointSliceはEndpoinsの問題を解消し、リストの更新時に関連する小さなオブジェクトのみを更新することでパフォーマンスが改善されている。
Discussion