株式会社ジェイテックジャパン CTOの高丘 @tomohisaです。最近、Resultパターンおよびそれによりエラーハンドリングおよびデータのパイプラインを関数で繋いでいく、Railway Oriented Programmingを実践するためのResultBoxesを作っています。
Railway Oriented Programming とは
Railway Oriented Programming は、エラーをthrowするのではなく、Result型で関数の戻り値にする書き方にデータのパイプラインも構築するもので、F#での関数型プログラミングに関する本も書いている、Scott Wlaschin氏が提唱したものです。
Scott氏が書いた、Domain Modeling Made Functional という本は、和訳され、「関数型ドメインモデリング ドメイン駆動設計とF#でソフトウェアの複雑さに立ち向かおう」というタイトルで来週発売予定です。
この本の中でもRailway Oriented Programming についてかかれているのですが、名前は"Railroad Oriented Programming"という名称となっています。一貫していないため、最初びっくりしたのですが、そのことについて𝕏でポストしたら著者のScott氏が説明してくれました。
こんにちは!間違いではありません!イギリス英語の方言では「railway」を使います。しかし、本の出版社はアメリカで、「railroad」を使っているので、変更しました😃 。どちらでも大丈夫です!気に入っていただけて嬉しいです。
ということで、Railway Oriented Programmingでも、Railroad Oriented Programming でも良いとのことです。
Railway Oriented Programming によって何が良くなるのか。
これはもちろん個人的感想であるのですが、Railway Oriented Programming により、プログラムが簡単になるのでしょうか?まず1つのファイルをRailway Oriented Programming に変更前のコードと後のコードをご覧ください。
変更前のコード
public class BlobAccessor(BlobConfiguration configuration)
{
public async Task<Result<bool>> SaveBlobAsync(
string containerName,
string filename,
byte[] Data)
{
var containerResult = GetContainer(containerName);
if (!containerResult.IsSuccessful)
{
return new Result<bool>(containerResult.Error);
}
var container = containerResult.Value;
var blobClient = container.GetBlobClient(filename);
await blobClient.UploadAsync(new MemoryStream(Data));
return true;
}
public async Task<Result<bool>> FileExistsAsync(string containerName, string filename)
{
var containerResult = GetContainer(containerName);
if (!containerResult.IsSuccessful)
{
return new Result<bool>(containerResult.Error ?? new Exception("Container not found"));
}
var container = containerResult.Value;
var blobClient = container.GetBlobClient(filename);
var response = await blobClient.ExistsAsync();
return response.Value;
}
public async Task<Result<byte[]>> GetBlobAsync(string containername, string filename)
{
var containerResult = GetContainer(containername);
if (!containerResult.IsSuccessful)
{
return new Result<byte[]>(
containerResult.Error ?? new Exception("Container not found"));
}
var container = containerResult.Value;
var blobClient = container.GetBlobClient(filename);
var response = await blobClient.DownloadAsync();
using var memoryStream = new MemoryStream();
await response.Value.Content.CopyToAsync(memoryStream);
return memoryStream.ToArray();
}
public Result<BlobContainerClient> GetContainer(string container)
{
try
{
return new BlobContainerClient(configuration.ConnectionString, container);
}
catch (Exception e)
{
return new Result<BlobContainerClient>(e);
}
}
}
変更後のコード
public class BlobAccessor(BlobConfiguration configuration)
{
public async Task<ResultBox<UnitValue>> SaveBlobAsync(
string containerName,
string filename,
byte[] data)
=> await GetContainer(containerName)
.ConveyorWrapTry(container => container.GetBlobClient(filename))
.ConveyorWrapTry(
async blobClient => await blobClient.UploadAsync(new MemoryStream(data)))
.Remap(_ => UnitValue.None); // エラーを返さなかったらtrue 成功
public async Task<ResultBox<bool>> FileExistsAsync(string containerName, string filename)
=> await GetContainer(containerName)
.ConveyorWrapTry(container => container.GetBlobClient(filename))
.ConveyorWrapTry(async blobClient => await blobClient.ExistsAsync())
.Remap(response => response.Value);
public async Task<ResultBox<byte[]>> GetBlobAsync(string containername, string filename)
=> await GetContainer(containername)
.ConveyorWrapTry(container => container.GetBlobClient(filename))
.ConveyorWrapTry(async blobClient => await blobClient.DownloadAsync())
.ConveyorWrapTry(
async response =>
{
using var memoryStream = new MemoryStream();
await response.Value.Content.CopyToAsync(memoryStream);
return memoryStream.ToArray();
});
public ResultBox<BlobContainerClient> GetContainer(string container)
=> ResultBox.WrapTry(
() => new BlobContainerClient(configuration.ConnectionString, container));
}
変わったこと
色々変わったのですが、以下の点があり、ResultBoxを使ったRailway Oriented Programmingが使いやすいと感じました。
- 短くかける (64-> 39行) 短くかける = 見るコードが少なくなるので良いと思います。
- エラー処理をシンプルにできる 基本的にエラーの時は最終的に親に送られる形になるので、最後の最後にどうするかを決めることができます。
-
次に渡す値を精査できる。 普通の関数の場合、関数内で定義した一時変数が最後まで使えるため、間違えて使う可能性がありますが、Railway Oriented Programmingではリターンしたものが基本的には次に渡されます。それだと複雑なものが扱えないため、
Combine()を使うと、もらったものと返したものの2値を返してくれます。これによって、本当に必要なものだけが渡されて、渡した値しか使われないので、間違えて使うことがなくなります。 - 行う作業にフォーカスできる。 処理を書いていても基本的にそれぞれの処理がResultBoxで渡す処理ごとに関数になっているので、単独の関数として分割することも可能ですし、分割せずに直接書いている時も、入力と出力に注力できるため、認知負荷が少ないと感じます。
-
繰り返し処理や処理の挿入が行いやすい それぞれの処理で
ResultBox<TValueType>になっているので、処理の挿入や繰り返しが簡単に行の挿入でできる。 - ResultBox限定ですが、sync / asyncのコードのミックスが楽に書ける ResultBoxでは、async (Task) と同期コードを自然に接続して最後にまとめて実行できるように記述していますので、関数内の色々な書き方をミックスできるようになり、シンプルに書けるようになりました。
このように、色々な点でわかりやすくプログラムが書けるようになってきました。
CQRSとRailway Oriented Programmingの融合
Railway Oriented Programmingを行なっていると、色々なところに導入したくなり、特に私たちの作っているイベントソーシング・CQRSフレームワーク、Sekibanに導入したくなりました。
上記の記事で、Sekibanにおける、コードの書き方の変遷をまとめたのですが、Sekibanは社内で使っているイベントソーシングフレームワークであるのですが、オープンソースとしてリリースしているため、どれだけ効率的に書けるかというのをこれまで色々考えてきました。CQRSにおいては、ドメインへのアクセスは基本的にコマンドとクエリーに制限されます。データを保存する時はコマンド、データを取得する時はクエリーを使用するのですが、Sekibanで工夫している点としては、このコマンドとクエリーをどれだけわかりやすく、楽に書けるかということを意識しています。
コマンド、クエリとDIの影響
これまで色々工夫してきたのですが、今までコマンド、クエリは以下のクラス構成で定義していました。
コマンド
- コマンドデータクラス
- コマンドハンドラークラス (DIが必要)
クエリー
- クエリパラメータデータクラス
- クエリハンドラークラス(DIが必要)
- クエリレスポンスデータクラス
DIが必要なハンドラークラスに関しては、C#では普通の書き方である、クラスのコンストラクタを使用したDIを使用していました。しかし、Resultクラスを使用して色々改善しているにあたり、ハンドラークラスは不要ではないかと感じました。DIに関しては、ハンドラークラスのコンストラクタを使用するのではなく、ハンドラー関数に渡すContextから、DIしたいクラスを取得するという方法を採用しました。これにより、ハンドラークラスを定義する必要はなくなり、データクラスにハンドラーメソッドを直接定義できるようになりました。そのため、以下のようなクラス構成にすることができます。
コマンド
- コマンドデータクラス + コマンドハンドラーメソッド(DI可能)
クエリー
- クエリパラメータデータクラス + くえらハンドラーメソッド(DI可能)
- クエリレスポンスデータクラス
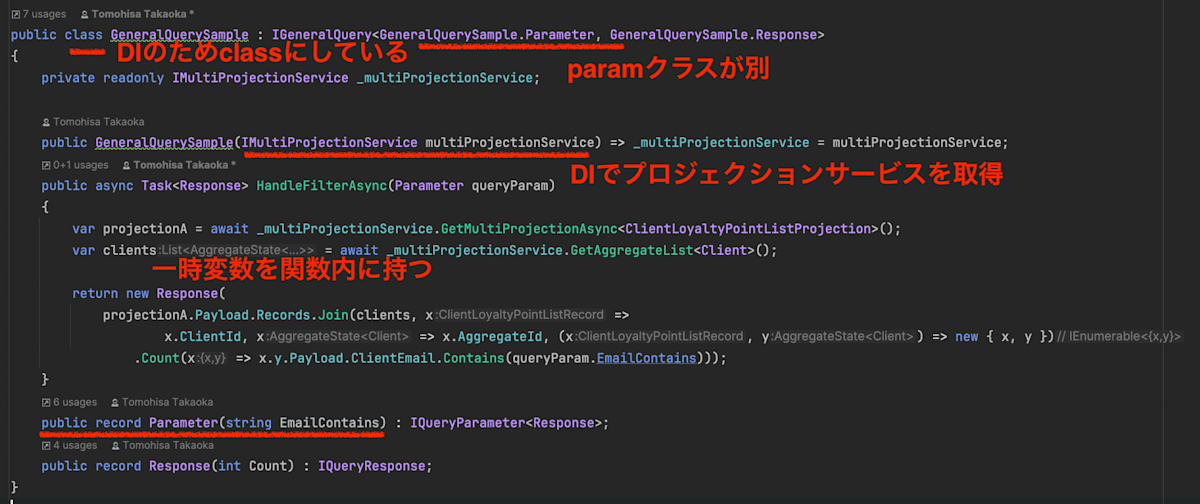
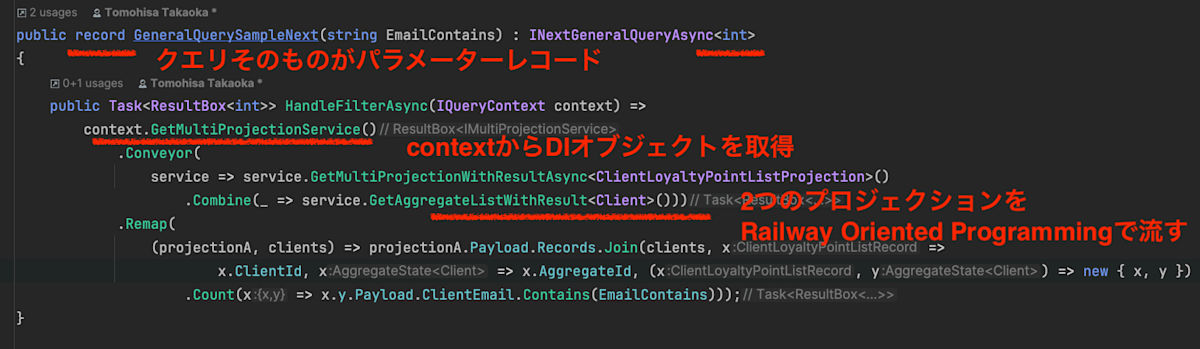
画像で説明付きで書くと、以下のような変化になりました。
変更前
変更後
使用するコード

ハンドラークラスがなるなることにより、コマンドやクエリに必要なインターフェースを記述すると、必要なハンドラーをそのデータクラス(record)内に直接記述することができます。また、クラスでDIをすることがなくなったため、DIのサービスコレクションに登録する必要もなくなり、簡単に使用できるようになりました。
CQRSによりシンプルになるドメインへのアクセス
Sekibanのコマンドは、基本的にイベントソーシングの1つの集約しか変更できません。Clientのコマンドであれば、1つのコマンドで複数のClientの集約を変更できるわけではなく、たくさんあるClientの集約の中の、1つの集約IDに対してのみ副作用を与える(イベントを保存する)ことができます。このルールにより、コマンドをシンプルに保つことができ、ほとんどのケースではフロントから1つのコマンドを呼ぶことにより目的を達成することができます。
複数の集約種類、また複数の集約に影響を及ぼすケースの場合、”プロセスマネージャ”的なユースケースを書いて、複数のコマンドを処理するAPIを記述します。それ以外の時は、コマンドを直接フロントエンドから叩くことによってバックエンドのドメインにアクセスしますので、レイヤーを作る必要はありません。Sekibanを使用しているときには、コマンドをAPIに自動変換する機能を使って、基本的にはSekibanのコマンドを直接アクセスしつつ、プロセスマネージャに関しては、APIとコントローラーで接続し、そのAPIをフロントエンドからアクセスします。
クエリに関しても、Sekibanの場合は、ライブプロジェクションを定義して、それに対するクエリを記述しますが、クエリはSekibanによる自動生成で直接APIになるので、レイヤーを記述するすることなく、フロントエンドからアクセスすることができます。
この概念は Vertical Slice Architecture (縦割りスライスアーキテクチャー)と呼ばれているものと近く、これにより、集約単位の変更であればレイヤーを意識せず、詰め替えもせずにコマンドとクエリーを記述できます。この方法の場合、コマンドとクエリーがユースケースに直結している必要があります。CRUD的な、テーブルの全項目を入出力するものではなく、ビジネスにおける出来事ごとにその出来事で変更することが必要なデータだけをイベントにして保存する形で設計する必要がありますが、イベントソーシングはその形で元々構成しているので、CQRSとセットで考えることができます。
実際にSekibanを用いてイベントとクエリを書いている例
コマンド
- Clientを作成するためには以下の検証を通過する必要がある
- BranchId - 必須
- ClientName - 必須、30文字以内
- ClientEmailAddress - 必須、メールアドレスとして正しい形式
- BranchIdから検索し、Branchが存在していてアクティブである必要がある
- ClientEmailAddressがすでに存在しないものである必要がある
- 上記の条件を満たすときに、ClientCreatedのイベントを作成
public record CreateClientWithResult(
[property: Required]
Guid BranchId,
[property: Required, MaxLength(30)]
string ClientName,
[property: Required, EmailAddress]
string ClientEmail) : ICommandWithHandlerAsync<Client, CreateClientWithResult>
{
public Guid GetAggregateId() => Guid.NewGuid();
public static async Task<ResultBox<UnitValue>> HandleCommandAsync(CreateClientWithResult command, ICommandContext<Client> context) =>
await context.GetRequiredService<IQueryExecutor>()
.Conveyor(queryExecutor => queryExecutor.ExecuteWithResultAsync(new BranchExistsQuery.Parameter(command.BranchId)))
.Verify(
value => value.Exists
? ExceptionOrNone.None
: new SekibanAggregateNotExistsException(command.BranchId, nameof(Branch), (command as ICommandCommon).GetRootPartitionKey()))
.Conveyor(_ => context.GetRequiredService<IQueryExecutor>())
.Conveyor(
queryExecutor => queryExecutor.ExecuteWithResultAsync(
new ClientEmailExistsQuery.Parameter(command.ClientEmail)
{
RootPartitionKey = (command as ICommandCommon).GetRootPartitionKey()
}))
.Verify(response => response.Exists ? new SekibanEmailAlreadyRegistered() : ExceptionOrNone.None)
.Conveyor(_ => context.AppendEvent(new ClientCreated(command.BranchId, command.ClientName, command.ClientEmail)));
}
クエリ
- クライアントリストを返すクエリ
- NameFilterにLike検索で合致する人だけ返す
- ここでは使っていないが、ページング機能なども追加可能
public record GetClientPayloadQueryNext(string NameFilter) : INextAggregateListQuery<Client, GetClientPayloadQuery_Response>
{
public ResultBox<IEnumerable<GetClientPayloadQuery_Response>> HandleFilter(IEnumerable<AggregateState<Client>> list, IQueryContext context) =>
ResultBox.WrapTry(
() => list.Where(m => m.Payload.ClientName.Contains(NameFilter))
.Select(m => new GetClientPayloadQuery_Response(m.Payload, m.AggregateId, m.Version)));
public ResultBox<IEnumerable<GetClientPayloadQuery_Response>> HandleSort(
IEnumerable<GetClientPayloadQuery_Response> filteredList,
IQueryContext context) =>
ResultBox.WrapTry(() => filteredList.OrderBy(m => m.Client.ClientName).AsEnumerable());
}
Sekibanは以下のリポジトリからオープンソースでどなたでも使用できます。
C#だからなかなか使わないという方も、GithubのStarだけでもつけていただけるととてもうれしいです。
まとめ
Railway Oriented Programming と関数型で記述する方法について色々考えていますが、数年前では考えもしなかった方法でシンプルに問題を解説するようになっているとには感じます。一つの問題は、関数型思考になっていない社内メンバーにこの書き方を提案して受け入れられるかどうかなのですが、出来るメンバーから、利点を説明して少しづつ皆の理解を向上して行こうかと思い、このように文章として今の理解を残しています。
またこれ以上関数型にのめり込むか、限界に気がついて手続き型コードに戻っていくかわかりませんが、また進展を書いていきたいと思います。

Discussion