株式会社ジェイテックジャパン CTOの高丘 @tomohisaです。この記事では、C#で開発を行うにあたり、Result型やRailway Oriented Programming簡単に使うことのできるOSSライブラリ、SingleValueResultsを公開したのでご紹介します。
C#のプロジェクトに以下のnugetパッケージをインストールすることによって使用可能です。
dotnet add package SingleValueResults
Visual Studio や Riderなどを使っている場合は、SingleValueResultsで検索していただいてGUIからインストール可能です。SingleValueResultsは.NET 8のプロジェクトで使用可能です。
Result、Railway Oriented Programming とは?
Result型とは
Result型は、関数型言語などの多くの言語では標準的に使用されているもので、エラーが発生した時に、C#の通常の手法のように、Exception(例外)を throw してそれを呼び出し元で catch する方法ではなく、関数の戻りの値とエラー情報を同時にResult型を使って返す手法です。エラー、もしくは戻り値のどちらかがあるため、呼び出し元ではエラーの有無で成功を判断することができます。
簡単なコードでは以下のような違いです。
// Result型を使用した書き方
public Result<int> Divide(int n, int d) => d switch {
0 => new ApplicationError("0で割れないためエラーです。"),
_ => n / d
};
public void Main()
{
switch (Divide(1,0))
{
case { IsSucceed : false } error:
Console.WriteLine(error.Exception);
break;
case { IsSucceed : true } success:
Console.WriteLine(success.Value);
break;
}
}
// Result型を使用せずにthrowする書き方
public int Divide(int n, int d) => d switch {
0 => throw new ApplicationError("0で割れないためエラーです。"),
_ => n / d
};
public void Main()
{
try {
var answer = Divide(1,0);
Console.WriteLine(answer);
} catch (Exception e)
{
Console.WriteLine(error);
}
}
コード量としては大きく変わらないように見えますし、どちらでも同じコードを書くことができるのですが、Result型を使用することにより、以下のような利点があります。
- try/catch は速度が遅いため、大量に起こる場合Result型の方がパフォーマンスが良い
- 判別の時に switch case および switch 式を利用することにより、わかりやすく記述することができる
- C#でもここ数年で機能拡張されている パターンマッチング の機能を最大限に活用することができる
- 好みの問題ですが、コードがスッキリする
特に個人的には、処理が複雑になればなるほど、Result型を使うことにより、処理が簡単になると感じて、今回のこちらのプロジェクトを作成しました。
Railway Oriented Programmingとは
Railway Oriented Programming とは、F#を使用した開発手法についてのブログや本を書いている、Scott Wlaschin 氏がブログやyoutubeにも残っている登壇でも発表している、複数のResult型関数を連結してエラー処理を統一する手法です。
Railway Oriented Programming - F# for Fun and Profit
Scott Wlaschin — Railway oriented programming - Youtube
簡単に説明すると、3つの処理が連続する場合、Result型で接続することにより、処理1が失敗した場合はそのエラーを返して、成功した場合は成功した値を処理2に渡す、処理2が失敗した失敗した場合はそのエラーを返し、成功した時だけ処理3に渡すという記述を簡単に書くことができる記述方式といえます。
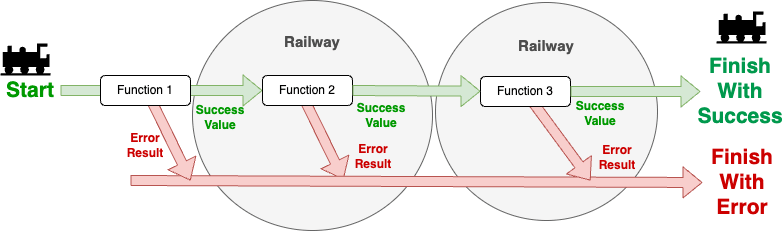
Result を使わずに書いた場合は例えば以下のようになります。
public function int Incremement(int target)
{
if (target > 1000) throw new ApplicationException("can not use over 1000.");
return target + 1;
}
public function int Double(int target)
{
if (target > 1000) throw new ApplicationException("can not use over 1000.");
return target * 2;
}
public function int Triple(int target)
{
if (target > 1000) throw new ApplicationException("can not use over 1000.");
return target * 3;
}
public void Main()
{
try
{
// (100 + 1) * 2 * 3 = 606
var value = Triple(Double(Increment(100)));
Console.WriteLine(value);
} catch (Exception e)
{
Console.WriteLine(error);
}
}
いろいろな書き方があるので上の書き方が全てではありませんが、Incrementの結果をDoubleに渡して、Doubleの結果をTripleに渡すのですが、2回目に実行されるDoubleのかっこの中に1回目を入れることになるのですが、この記法がわかりにくいのは、Incrementが最初に実行されるにもかかわらず、一番後ろに書かれている点です。これを避けるために値を一度変数に記録することもできますが、そうすると長い記述になるだけではなく、一時変数を使うことで、変数名の書き間違えなどによりバグが入る可能性が出てきます。
public void Main()
{
try
{
// (100 + 1) * 2 * 3 = 606
var value1 = Increment(100));
var value2 = Double(value1);
var value3 = Triple(value2);
Console.WriteLine(value3);
} catch (Exception e)
{
Console.WriteLine(error);
}
}
Result + Railway Oriented Programming を使うと以下のような実装になります。言語やライブラリによって書き方は様々なのですが、今回リリースしたSingleValueResultsを使用した記述を紹介します。
Result 型に Railway メソッドが準備されていて、以下のように記述可能です。
public static SingleValueResult<int> Increment(int target) => target switch
{
> 1000 => new ApplicationException($"{target} is not allowed for {nameof(Increment)}"),
_ => target + 1
};
public static SingleValueResult<int> Double(int target) => target switch
{
> 1000 => new ApplicationException($"{target} is not allowed for {nameof(Double)}"),
_ => target * 2
};
public static SingleValueResult<int> Triple(int target) => target switch
{
> 1000 => new ApplicationException($"{target} is not allowed for {nameof(Triple)}"),
_ => target * 3
};
public void Main(string[] args)
{
// (100 + 1) * 2 * 3 = 606
switch (Increment(100).Railway(Double).Railway(Triple))
{
case { Exception: { } error }:
Console.WriteLine($"Error: {error}");
break;
case { Value: { } value }:
Console.WriteLine($"Value: {value}");
break;
}
}
Doubleの入力はint型ですが、Incrementの出力型と同じなので、メソッドを渡すことにより、Incrementの出力を自動的にDoubleに渡すように、Railwayメソッドには記述されています。もしIncrementにエラーが起きた場合は、DoubleとTripleは実行されずに、エラーのみを返します。
RailWayメソッドの実装は以下のようになっています。
public SingleValueResult<TValue2> Railway<TValue2>(
Func<TValue, SingleValueResult<TValue2>> handleValueFunc)
where TValue2 : notnull
=> this
switch
{
{ Exception: not null } e => e.Exception,
{ Value: { } value } => handleValueFunc(value),
_ => SingleValueResult<TValue2>.OutOfRange
};
エラーがあった場合はそのままエラーを返し、成功した場合は値を次のメソッドに繋ぐという形です。このようにRailway Oriented Programming の機能はシンプルで、各メソッドもシンプルなのですが、自分のプロジェクトで統一的にC#を使って扱いたかったので、作成して、OSSとしてリリースしました。
設計コンセプト
C#にはすでにいくつかの有名なResult機能を持つライブラリが存在します。
それぞれ高機能なのですが、特にResult型のコアの部分の定義が複雑になりがちです。いくつかのライブラリを使って個人的に試してみたのが以下のレポジトリです。
上記が DotNextのResultの定義ですが、値とエラーをprivateで包んで、メソッドで取り出す形で実装しています。個人的には最近はデータはできるだけシンプルに定義しているため、これを簡単に定義しつつ、パターンマッチングを最大限活用できる方針で実装しました。
C#のレコード型をベースに作られていますが、Value 型と Exceptionの両方に ? がついているので型としてはnullを許容しています。これは一見使いにくく感じるのですが、パターンマッチングを使用すると、簡単に判別できます。
string RunIncrement(int target) =>
Increment(target) switch
{
{ Exception: { } error } => $"Error: {error}",
{ Value: { } value } => $"Value: {value}",
_ => "Unknown"
};
C#のパターンマッチングの機能を使用すると{ Exception: { } error } と書くことにより、Exceptionプロパティが not null の場合に、その値をerror一時変数に入れて使うことができます。error一時変数は、null出ないことがわかっているため、not nullで受け取ることができるため、nullチェックをする必要がありません。
同様に、{ Value: { } value } これによってValueが入っている場合にそれを使うことができます。この書き方がライブラリ内でも使用されているため、Valueの型は、 notnull 制約をつけており、null許容値型、null許容参照型両方使わないことを想定してライブラリが作られています。
パターンマッチングに関してはこちらの記事をご覧ください。
自分で定義して使うことの利点としては、ある機能が必要になった時に、1つのライブラリにはあるが、他のライブラリにない場合に、自分で拡張メソッドを定義して管理するなら、最初から自分で作ったライブラリに追加していった方が良いと感じたためです。
まとめ
この記事では、Result型とRailway Oriented Programmingの定義の説明と、簡単なSingleValueResultsの設計思想を説明しました。具体的な使い方に関しては、英語でリポジトリに書いていますが、zennでもまた記事を書いていきたいと思います。

Discussion