HashiCorp NomadでGitHub Actions Self-hosted Runnerを簡単にautoscale運用する
HashiCorp Nomad おさらい
Nomad は HashiCorp が2015年から開発を続けている、非常に軽量かつ高速なワークロードスケジューラーです。Nomad が管理するクラスターに対して、コンテナアプリケーションはもちろん、Java アプリ (.jar)、任意のバイナリ、QEMU 仮想マシンなど、レガシーアプリを含む様々な種類のワークロードをオーケストレーション・スケジューリング実行することができます。GPU を利用するワークロードにも対応しています。
世界で見ると実際のミッションクリティカルな本番環境での稼働実績も多数あり、下記では利用事例の一部が紹介されています。
有名な例としては、Cloudflare 内部での利用事例や、CircleCI の job 実行環境に Nomad が採用されていたりします。
過去 Cloud Operator Days Tokyo 2021 で、実際に CircleCI のエンジニアの方が CircleCI でどのように Nomad が利用されているのか、詳細に説明されています。とても参考になるので下記に動画へのリンクを置いておきます。
もう2年ほど前のデータになってしまいますが、Nomad のスケーラビリティを実際に HashiCorp が性能試験した実験データも公開されています。実験に利用した詳細な環境は記事の中で言及されていますが、3台の Nomad Scheduler サーバーを使って 200万個の Docker コンテナをスケジューリングするという実験です。
この時、ピーク時で実に 6,100 台の Nomad node (AWS Spot Instances) が auto-scaling group によって登録されましたが、その巨大なクラスタ群に対してもワークロードを問題なくスケジューリングすることができていたそうです。
余談
もうすぐリリースされる Nomad 1.3 では、built-in Service Discovery 機能が追加される予定です!これにより、template stanza を使った dynamic なサービスホスト情報の inject 程度の単純な要件であれば、Consul を使わなくても同様の事が実現できるようになります。便利。
Kubernetes と何が違うの?
については、公式のページがありますので、ご確認ください。
Nomad はその軽量さ・シンプルさ故の非常に高いパフォーマンスが特徴です。シングルバイナリで動作し、サーバーのリソースを無駄なく効率的にワークロードへ割り当てることができます。
ツールやエコシステムの充実度、という意味ではもちろん今日の Kubernetes に軍配が上がることは言うまでもありません。ただ、導入の敷居の低さという観点では Kubernetes に比べて大きなメリットを持っています。私も最近 Kubernetes をぼちぼち勉強していますが、それもあって余計に Nomad のシンプルなアーキテクチャが際立って感じられ、これは間違いなく多くの人にとって非常に理解・学習しやすいものです。
どちらが良い悪いという世界線ではなく、それぞれの持つメリット・デメリットを考慮し、適材適所でユースケースに応じてお互いが共存・活用できるのではないかと思っています。
(本題) GitHub Actions Self-hosted Runner
Self-hosted Runner 自体の詳細な説明はここでは割愛します。
GitHub Actions の workflow を自身が管理する任意のインフラで実行できる便利なやつですね。workflow の実行環境により細かなリソース割当を行ったり (CPU, メモリ, etc)、CI/CD パイプラインからプライベートネットワークのリソース対して直接アクセスしたい場合にはとても有効なソリューションです。
ところで多くの方はどのようにこの実行環境を運用されているのでしょうか?
調べたところ、Kubernetes や各クラウドベンダーが提供するマネージドのコンテナ実行環境などで工夫して回している組織が多い印象でした。今回は YAML を書きたくないので、少なくとも Kubernetes では頑張りません。
どうやって runners を auto-scaling させるか問題
GitHub 公式では、Webhooks を使うのがよい、とされています。
Runners は当然 GitHub Actions が走っている間しか必要とされないリソースなので、常時実行では無駄使いになってしまいます。要求されるリソースの使用量もその日の忙しさ次第。このため、auto-scaling は実運用では欠かせないでしょう。
公式の例では、workflow_job イベントをトリガーに、必要な分だけ self-hosted runners を "on-demand" で起動して、使い終わったら捨てる、というフローが提案されています。
現在は ephemeral モードが使えるので、1つの runner に対して1つの job だけを実行させ、終わったら破棄、同一の workflow ファイル内から呼ばれた別の job は新しく立ち上げた runner を使う、といったことが比較的簡単にできるようになっています。
Nomad を使う (parameterized batch jobs)
Nomad では、一般的な long-lived なアプリケーションは service job として作成可能ですが、一時的な job の実行用として batch job も用意されています。
そしてこの batch job に対して任意のパラメーター属性を持たせ、実行時にパラメーターを指定することで挙動の変わる複数の job を簡単に dispatch できるのが、parameterized batch jobs です。
これはまさに Self-hosted runners のような使い捨て環境に最適の実行環境であり、パラメーターを使うことで target となる runners のコンテナのスペックを調整する、といったことも簡単にできそうです。
構成イメージ図
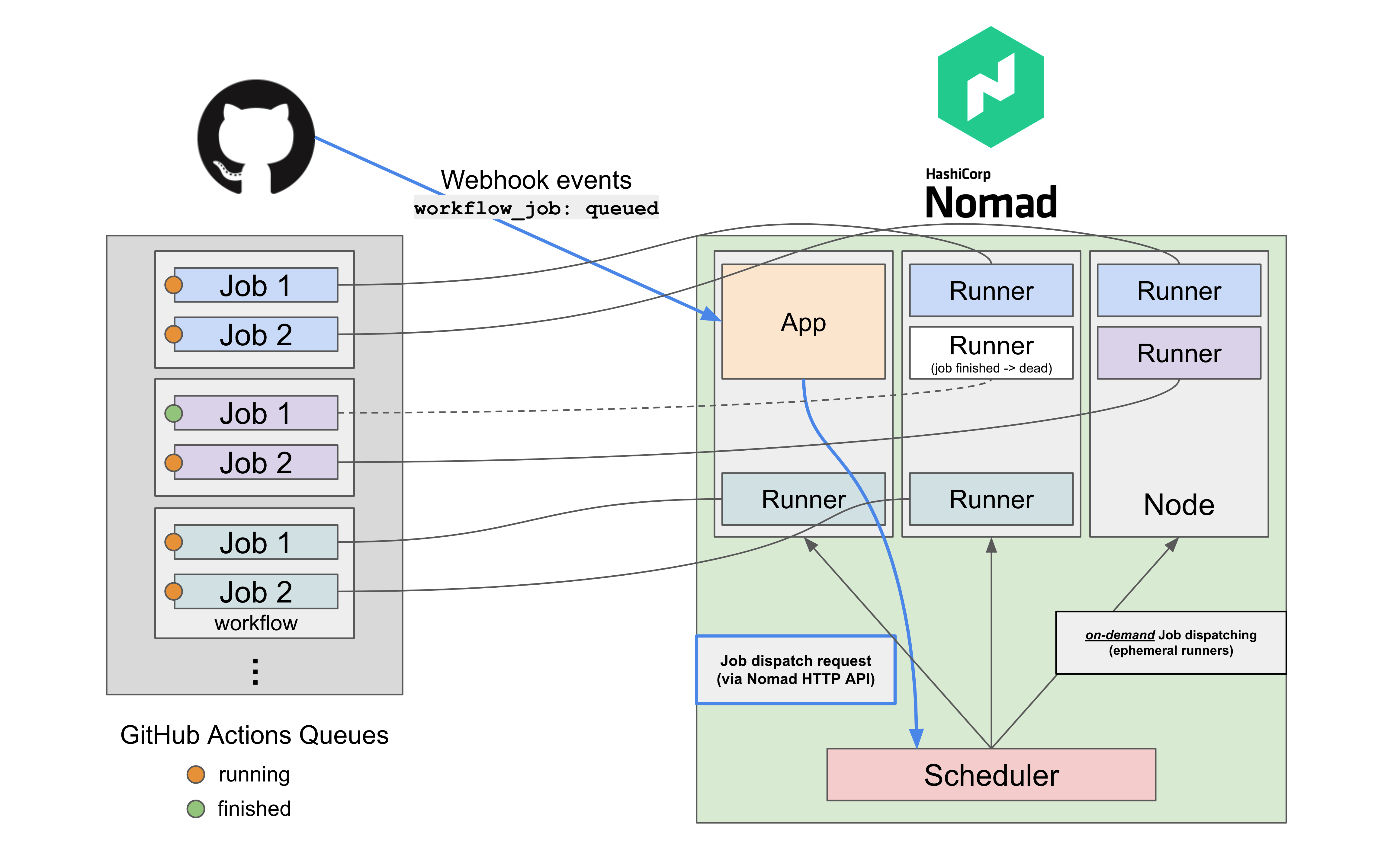
図はだいぶ適当に線を引きましたが、複数台の Scheduler (Nomad Servers) と複数台の Nodes (Nomad Clients) がある一般的なクラスタ構成をイメージしています。dc や region といった Nomad 独自の概念はここでは省略していますが、各 Node はこうしたセグメントによって何らか分散して配置されていることが多いでしょう。
肝心な GitHub から送られてくる Webhook の受け取りですが、今回は同じく Nomad 上で service job として小さな Node.js アプリを常時稼働させ、このアプリで Webhook を受け取り、内容に応じで直接自身の Nomad クラスタに API で job の dispatch を行います。dispatch された job (コンテナ) は、アサインされた GitHub Actions の Job の実行が終了すると即座に終了し、リソースを開放します。
もちろんこのアプリは Nomad 以外の場所で単独で動作させても問題ありません。あくまでアプリから Nomad クラスタへの疎通性 (Nomad token を使って HTTP API をコールできる) があれば大丈夫です。
Nomad job 定義 (Runners)
今回は下記で公開されている Docker Github Actions Runner を利用して、ephemeral runner を Docker コンテナとして動作させます。
下記はこの Docker イメージを Nomad job として定義する例です。
job "github_runner" {
datacenters = ["dc1"]
type = "batch"
parameterized {
payload = "forbidden"
meta_required = ["GH_REPO_URL"]
}
vault {
policies = ["github-hashicorp-demo"]
change_mode = "signal"
change_signal = "SIGINT"
}
group "runners" {
task "runner" {
driver = "docker"
template {
env = true
destination = "secret/vault.env"
data = <<EOF
ACCESS_TOKEN = "{{with secret "demos-secret/data/github-hashicorp-demo"}}{{index .Data.data "github-pat"}}{{end}}"
EOF
}
env {
EPHEMERAL = "true"
DISABLE_AUTO_UPDATE = "true"
RUNNER_NAME_PREFIX = "gh-runner"
RUNNER_WORKDIR = "/tmp/runner/work"
RUNNER_SCOPE = "repo"
REPO_URL = "${NOMAD_META_GH_REPO_URL}"
LABELS = "linux,x86,t2-micro"
}
config {
image = "myoung34/github-runner:latest"
privileged = true
userns_mode = "host"
volumes = [
"/var/run/docker.sock:/var/run/docker.sock",
]
}
}
}
}
この例では Nomad の Vault integration を利用しているため、定義ファイルにはシークレット類が一切ハードコードされておらず、簡単に任意の VCS で管理できます。
Vault を利用しない場合は、上記の定義から vault {...} および template{...} stanza を消し、task->env に ACCESS_TOKEN を直接渡します。これは GitHub Runner token を動的に発行するための PAT (personal access token) です。
今回の例では、Repository 単位での Runner 管理をするので、環境変数として REPO_URL を渡す必要があります。これを job 定義に直接書いてしまうと、この job 定義はその repository 専用になってしまい、共有ができません。そこで、parameterized stanza 内でこの job の dispatch 時に必要な meta data (key/value pair) を定義しており、今回は GH_REPO_URL としています。先ほどの図で説明した Webhook 受け取り先のアプリは、Webhook の payload データから呼び出し元の repository を取得し、Nomad API を送るときにこの GH_REPO_URL meta data を POST データにセットします。これにより、job dispatch 時に動的にパラメーターを指定でき、この job 定義を異なる repository 間で使い回すことができます。
Webhook server
あくまでもアイデイアの1例として、非常に単純な webhook 受信用のサーバーを Node.js で書いた例を下記のリポジトリに置いておきました。
GitHub 公式から提供されている @octokit/webhooks を使って Webhook を処理しています。
そして、Webhook 受信後にアプリから Nomad の Dispatch Job HTTP API にリクエストを送っているだけです。
workflow_job.queued だけを listen する
@octokit/webhooks では、webhooks.on を使って対象とするイベントを絞れることができます。この例では、workflow_job.queued のみを対象にしています。
今回は Runners コンテナを ephemeral モードで動作させており、コンテナはアサインされた Job が終了すると自動的に自身を repository から deregister して終了するため、例えば workflow_job.completed イベントなどは特に意識せず無視できます。
// Only listen to the "workflow_job.queued" event
const eventName = "workflow_job.queued";
webhooks.on(eventName, ({ id, name, payload }) => {
console.log(`${eventName} event received`);
Nomad.dispatchJob(name, payload);
});
GitHub-hosted runners を使う Job からのイベントを無視する
workflow_job.queued は、呼び出し元の GitHub Actions Job が Self-hosted runners を利用するか否かに関わらず (i.e., runs-on:)、ほぼ全ての Job 呼び出しに対して Webhook イベントが発生します。
GitHub-hosted runners の webhook までも対象にしてしまうと、無駄に runners のコンテナが立ち上がり、大量の Idle runners が発生してしまいます。これを避けるため、payload の中身を見て、workflow_job.labels に self-hosted が含まれている場合だけ Nomad の job dispatch を行うようにしておきます。
// only target events with "self-hosted" label
const triggerConditions = (
payload.workflow_job.labels.length > 0 &&
payload.workflow_job.labels[0] === 'self-hosted'
);
if (!triggerConditions) return;
server アプリを Nomad にデプロイする
job 定義のサンプルは上記の GitHub repo の README にあるので、参考にしてください。
その他応用
Runners コンテナの実行先ホストをコントロールしたい
GitHub-hosted runners がそうであるように、Self-hosted runners においても実行先のホストを変えたい場合があると思います。Nomad は Linux に加え、Windows や macOS にインストールすることも可能です。
このように OS や CPU architecture の異なる Node を Nomad クラスタ内で組み合わせて運用する場合、constraint や affinity 機能を使って、実行先ホストを柔軟に制御することができます。
Actions workflow 内で指定できる runs-on: の custom label 機能を上手く利用し、アプリから GH_REPO_URL を動的に渡しているのと同様の方法で、dispatch 時にこれらの値を動的に指定し、目的のホスト上で runners コンテナを実行することができると思います。
Nomad Node 自体も auto-scaling させたい
これまでの内容は、既存の Nomad クラスタ上に runners コンテナを auto-scaling させていく、というストーリーです。なので、当然クラスタ全体のキャパシティが埋まってしまった場合、それ以上 runners コンテナを dispatch することができず、他の job の実行を待つことになります。
Nomad クラスタ自体の auto-scaling は Nomad Auto Scaler を使うことで比較的簡単に行えます。
ターゲット環境としては AWS, GCP, Azure が現在サポートされており、scale-in 時にサービス断が発生しないよう、Node の drain を安全に行ってくれます。
Discussion