データプラットフォームにおけるパーソナルデータとの向き合い方
この記事は datatech-jp Advent Calendar 2022 15 日目の投稿です。
TL;DR
- データ活用において、パーソナルデータとの関わりは切っても切り離せない存在。
- パーソナルデータと個人情報の区分けと分類を正しく理解し、持ち得るデータがどういうリスクがあるのか?どいう状態であれば利活用や第三者への提供が可能なのかを理解する
- その上で、パーソナルデータの漏洩リスクと利活用の利便性のバランスを選択したアーキテクチャを設計しデータプラットフォームを実現する
はじめまして、DeNAのデータエンジニアの Shinichiro Joya と申します。
ビックデータやAIなどと叫ばれて久しいですが、5−6年のデータエンジニアとしての経験の中で、ユーザさん、顧客から預かった大切なパーソナルデータについて、少し知見と実際にどうするべきか?という考えがまとまり始めたので、このタイミングで紹介させて頂ければと思います。
勿論、至らない点は多岐に渡ると思います。その際は指摘いただく事で私自身の理解も深められればと思います。
章立て
- パーソナルデータとは何か?
- パーソナルデータの定義・解釈・対応方針
- Google Cloudを中心としたパーソナルデータの保護
前提事項
- 本ページでは、日本国法を中心に取り扱います。EUのEU一般データ保護規則(GDPR)や、カルフォルニアのカリフォルニア州消費者プライバシー法(CCPA)は本投稿の範囲外とします。
- 第3章では、実際のサービスを活用したパーソナルデータの保護について触れますが、Google Cloudのソリューションを中心としています。
- この投稿は、所属する会社を代表した意見ではありません。また、所属する会社のシステム構成を表したものでもありません。
- 解釈や定義は、2022年12月時点の物です。法改正等で変わる場合があります。
対象読者
- データ基盤、分析基盤の開発・運用に従事している方
- DXやビックデータに関連したシステム企画を行っている方
- アナリストやデータサイエンティストなどデータを扱う業務に従事している方
1章 パーソナルデータとは何か?
総務省の平成29年度 情報通信白書によりますと、ビッグデータとして以下の定義が行われています。
| 種別 | 情報の主体 | 説明 |
|---|---|---|
| オープンデータ | 政府、国、地方公共団体 | 官民データ活用推進基本法を踏まえ、公共情報としてオープン化されているデータ |
| 知のデジタルデータ | 企業 | 暗黙知(ノウハウ)を構造化・データ化した物。農業・インフラ管理・ビジネスといった産業・企業が持ちうるパーソナルデータ以外のデータの事を指す |
| M2Mデータ | 企業 | IoTデバイスなどから吐き出される、ストリーミングデータ。M2M(Machine to Machine) |
| パーソナルデータ | 個人 | "個人の属性情報、移動・行動・購買履歴、ウェアラブル機器から収集された個人情報を含む。また、後述する『改正個人情報保護法』においてビッグデータの適正な利活用に資する環境整備のために「匿名加工情報」の制度が設けられたことを踏まえ、特定の個人を識別できないように加工された人流情報、商品情報等も含まれる。そのため、本章では、「個人情報」とは法律で明確に定義されている情報を指し、「パーソナルデータ」とは、個人情報に加え、個人情報との境界が曖昧なものを含む、個人と関係性が見出される広範囲の情報を指すものとする。"(情報通信白書より引用) |
つまり、個人の特定する識別子もあれば、それだけでは特定出来ない履歴情報もパーソナルデータとして含みます。また、改正個人情報保護法に記載の通り、特定の個人を識別出来ないように加工した仮名加工情報および匿名加工情報も含みます。
このページでは上記ビックデータ分類の内、パーソナルデータの取り扱い方について記載していきます。
なぜパーソナルデータを扱う必要があるか?
幾つかの現場にて、データプラットフォームを立ち上げさせていただく中で、パーソナルデータの扱いについては扱いが難しく、なんとなく扱いたくないといった意見があります。
勿論、お預かりした大切なデータですので漏洩したり意図しない利用をされると、提供した個人への不利益を与える可能性があり軽々には扱うことが出来ません。
一方で、今まで紙面やPCのExcelでパーソナルデータを扱っていた業務も少なからず存在し、それをDXといった文脈でシステム化するとなると引き続き個人情報を取り扱う必要があります。これらは事業運営上、必然性のある業務で有ることが多いです。
そのため、利便性とセキュリティが担保された形でパーソナルデータも含むデータ活用を行いたいユーザと、なるべくリスクを取りたくないシステム開発側で折り合いがつかない。といった事が良くあると考えています。
個人的な意見ではありますが、利用者にとって安心・便利なデータ活用環境が無ければ、例えシステムを構築しても、バックドアが生まれてしまい結果漏洩するといったことになるのでは無いでしょうか。
企業・ビジネスにおいて、パーソナルデータを一切扱わないビジネスは殆ど無くなってきていると感じています。世界の法規制としても年々取り扱いが厳しくはなっていますが、一方でようやく法律の定義が進んだとも言えます。法律と業務のニーズ・シーズを理解しデータプラットフォームのアーキテクチャや、各種処理、運用ルールに取り込む事はデータエンジニアとしての腕の見せ所だと考えています。
2章 パーソナルデータの定義・解釈・対応方針
パーソナルデータの定義と解釈
前述の通り、パーソナルデータには、個人を特定・識別出来る情報と個人の履歴情報と個人を特定出来ないように加工された情報が広く含まれます。
私が経験や周辺の情報を含めて纏めさせていただきますと、以下の通りになります。
| 種別 | 名前 | 説明 | 例 |
|---|---|---|---|
| 個人情報 | "直接識別情報" ※1 | "それ単体で直接に個人の特定を可能にする情報 | マイナンバー、指紋データ、顔認識データ、遺伝子情報、名前、データベースの一意なID" ※1 |
| 個人情報 | "間接識別情報" ※1 | "それ単体は個人を識別可能な状態では無いが、複数組み合わせることによって個人を識別しうる情報" | 年齢、生年月日、性別 ※1 |
| 個人情報 | "連絡可能情報" ※1 | "それ単体で個人に連絡することが可能な情報" ※1 | 住所、電話番号、Emailアドレス |
| 個人情報 | 要配慮情報 | より慎重な取り扱いを要する個人情報 | 人種、信条、社会的身分、病歴、犯罪の経歴など |
| 個人情報 | "個人に被害を与える情報" ※1 | "それ単体で個人に被害を与える事が可能な情報" ※1 | クレジットカード情報、銀行口座番号・暗証番号、オンラインシステムのID/パスワード |
| 個人情報 | 仮名加工情報※2 | 他の情報と照合しない限り、特定の個人を識別出来ないように加工した個人に関連する情報 | 名前の除去やハッシュ化、住所を都道府県に置き換える、生年月日を生年月にするなど |
| 非個人情報 | 匿名加工情報※2 | 特定の個人を識別することが出来ないように個人情報を加工し、当該個人情報を復元出来ないようにした情報のことを言う | 名前の除去、住所を都道府県に置き換える、生年月日を削除するなど |
| 個人情報 | 個人関連情報※2 | 仮名加工情報,匿名加工情報に該当しない個人のデータ | Cookie、アクセスログ、購買履歴、移動履歴,IPアドレスなど |
情報の関係性を図示してみました。別タブで開いてください。
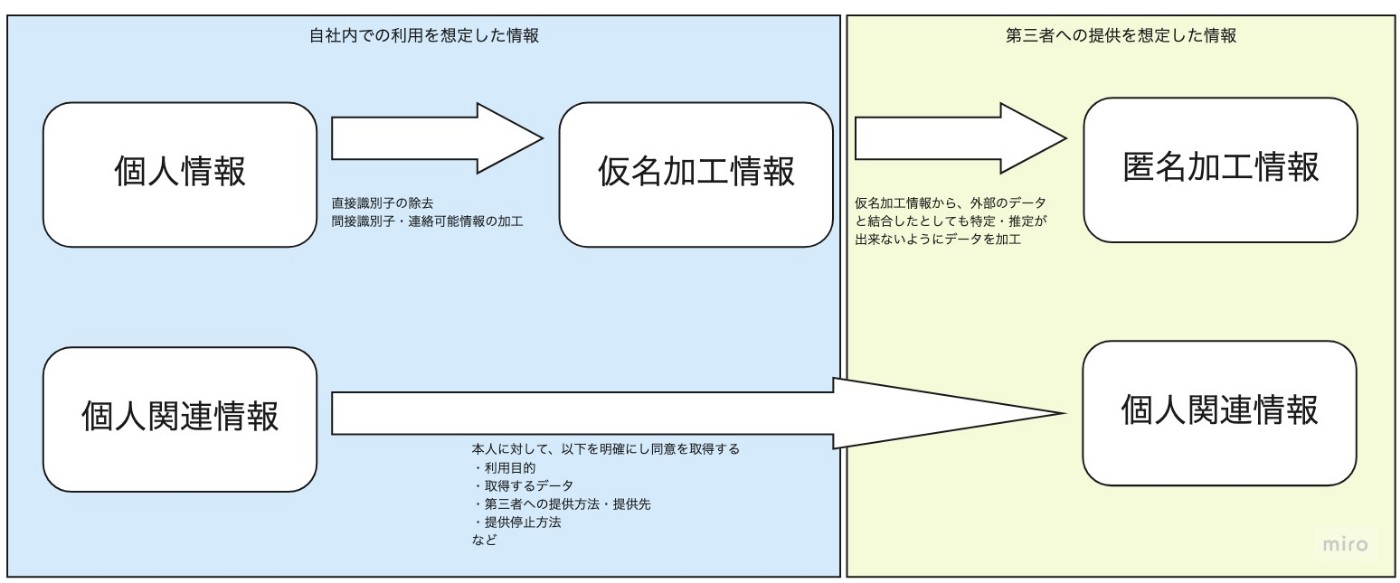
補足情報
- 名前はなぜ直接識別情報か?
- 名前は、それだけでは個人を特定しない場合も多いですが、非常に珍しい名字・名前の場合はそれだけで個人を特定可能にするため、"直接識別情報" ※1 と考えたほうが良いです。
- 個人関連情報
- 2022/4に施行された情報です
- 個人情報として定義されていない一方で、実は以下の条件に合致すると個人を特定もしくは推定出来てしまう場合があります。個人関連情報から個人への利益・不利益が決まる様なデータ活用を行う場合は、特に注意が必要なデータだと考えています。(以下※1より引用)
- 特性性:履歴の一部に、まれにしか現れない特異な値が含まれる場合
- 習慣性:履歴に特定の値が頻繁に出現し、その人物の週間を通じて不変な属性値が推測される場合
- 一意性:履歴のバリエーションが多く、同一の履歴情報が二度と出現しない場合
- そのため、第三者へ提供を行う場合は本人への同意が必要な情報となります。
- 仮名加工情報
- 以前は、分析・MLの用途として、匿名加工情報が定義されていましたが、加工難易度が非常に高く利用が現実的ではありませんでした。そのため、令和2年に仮名加工情報が定義されています。そのため自社内での利用を想定しています。
- 第三者への提供を制限おり、他の情報を用いた個人の識別は禁じられていますが、プライバシーポリシーなどで公表すれば利用目的を後から追加変更することが可能な情報です。
- 匿名加工情報
- 第三者への提供が可能ですが、他のデータと結合しても特定・推定が出来ないように加工する必要があるなど非常に加工要件が難しいのが特徴です。
- k匿名性、l多様性、t近似性を保つ必要がある
- 匿名加工情報の作成には、内製で開発する他に以下の様なソリューションを活用する手段もあります。https://www.ntt-tx.co.jp/products/anontool/
- 仮名加工情報と同様にプライバシーポリシーに作成目的や加工方法、安全管理措置の内容を記載し公表することが必要です。
- 第三者への提供が可能ですが、他のデータと結合しても特定・推定が出来ないように加工する必要があるなど非常に加工要件が難しいのが特徴です。
※1 の記載箇所は以下の書籍から引用しています。出版から少し時間が立っていますが、非常に良い書籍と考えています。
※2 は以下のサイトを参考しています。
対応すべきこと
仮に新たにデータプラットフォームを立ち上げるとして、何をすればよいのでしょうか?個人の経験から言えば、以下の活動が必要と考えています。
利用目的の把握と規約、プライバシーポリシーの確認
データエンジニアは実は、多様な利用者と関わるため、データ活用のニーズと形態を熟知している事が多いです。そのため、サービス利用規約を確認し、利用目的の特定(個人情報保護法17条)と照らし合わせて合理的な範囲で目的を定義出来ているか。エンジニアが踏み込んで確認すべきと考えます。
場合によっては、目的外の利用を引き起こしてしまうケースもあります。その場合は利用規約の改定と再同意の取得は必ず必要です。
仮名加工情報・匿名加工情報・個人関連情報の取り扱いもプライバシーポリシーに列挙する必要があります。合わせて確認しましょう。
情報のTiering
パーソナルデータの種別に合わせて、Tieringし定義を行っておくと共通認識が作れて便利です。
以下は例になります。
| tier | 名前 | 説明 | 利用例 | 扱う情報 |
|---|---|---|---|---|
| tier1 | rawデータ層 | 個人情報がそのまま保管されている層 | カスタマー対応で、顧客の個人情報を利用目的の範囲かつ合理的な範囲で把握する必要がある。 | 個人情報、個人関連情報 |
| tier2 | データ利活用層 | "直接識別子"を除去もしくはハッシュ化、"間接識別子"、"連絡可能情報"、要配慮情報については、除去もしくは一部除去を行うなど、外部のデータと紐付けなければ個人と特定・推定出来ない状態に変換 | 分析環境、AI環境、各部署のデータ活用環境 | 仮名加工情報、個人関連情報 |
| tier3 | データ提供層 | tier2のデータを匿名加工情報に加工し第三者への提供。個人関連情報 | 提携する企業へのデータ提供、広告などのSaaSアプリケーションへのデータ提供 | 匿名加工情報、(本人同意済みの)個人関連情報 |
個人情報の分類とアクセスポリシーの取り決め
ここまででパーソナルデータの中の個人情報の分類とTieringが出来ました。ここで実際に、データを確認しつつ、個人情報の分類と誰がそのデータを閲覧してよいのか。アクセスポリシーを決めていきましょう。
例えば、以下の様なイメージです
| カラム名 | 論理名 | サンプル | 個人情報分類 | tier2への加工要件 | アクセス可能な部署 |
|---|---|---|---|---|---|
| userId | 会員ID | 0001 | 直接識別情報 | ハッシュ化 | CS部署、営業部署 |
| lastName | 性 | 山田 | 直接識別情報 | 除去 | CS部署、営業部署 |
| firstName | 名 | F | 直接識別情報 | 除去 | CS部署、営業部署 |
| address | 住所 | 東京都○○区△△1-x-2 | 連絡可能情報 | 都道府県に丸める | CS部署、営業部署 |
| joinDate | 入会日 | 2022年1月10日 | 個人関連情報 | 不要 | 自社内であればアクセス可能 |
| creditCardNumber | クレジットカード番号 | xxx-yyyy | 個人に被害を与える情報 | 除去 | 不可 |
アクセス制御の要件決め
アクセス制御も、Tier毎に設計すると利便性とセキュリティの双方が保てて有用です。
以下の例では、Tier1からデータプラットフォームで構築した場合を想定しています。
| Tier | ネットワーク制御 | 認証・認可 | 踏み台アクセス要否 | 監査ログ取得・検査 |
|---|---|---|---|---|
| Tier1 | IP制限有り | Google Workspace, IAM | 必須。Identity-Aware Proxy経由でのアクセス | 常時アクセスログを取得し日次でアクセス元毎のアクセスリストを検査。5年分をGoogle Cloud Storageに保管 |
| Tier2 | IP制限なし | Google Workspace, IAM | 不要 | 常時アクセスログを取得。3ヶ月分のログをGoogle Cloud Storageに保管 |
| Tier3 | IP制限なし | Google Workspace, IAM | 不要 | 常時アクセスログを取得。3ヶ月分のログをGoogle Cloud Storageに保管 |
アーキテクト、各種設計
ここまで各種要件の整理を行いました。以降はデータエンジニアが、データプラットフォームのアーキテクチャや各種設計を行います。
各Tierの考え方をインプットしつつアーキテクチャイメージを列挙してみます。
- Tier1をサービス側で持つアーキテクチャ
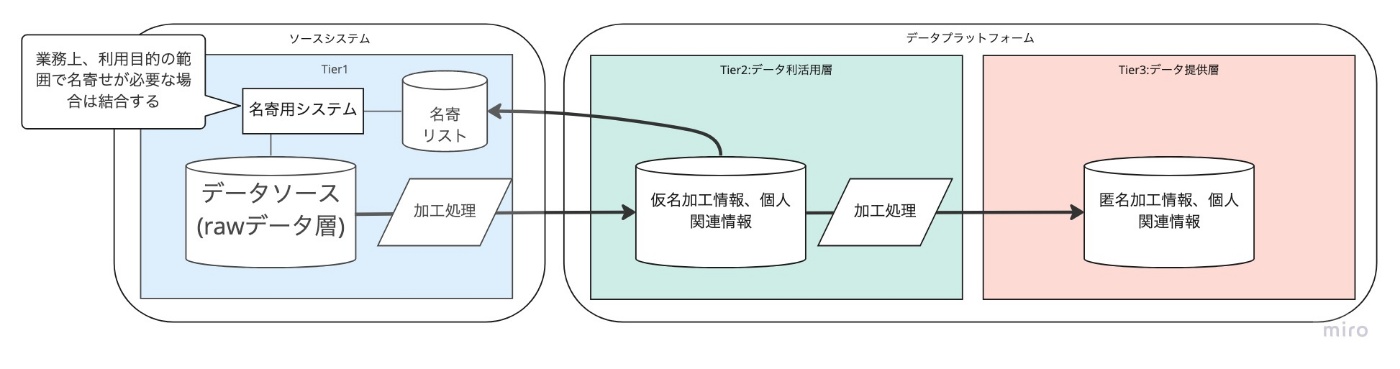
- データソースのシステム側で、個人情報を扱うアーキテクチャになります。
- 個人情報のリスクポイントを1箇所に閉じ込められるメリットがあります。
- 一方で、個人情報との名寄せによる業務が必要な場合は、それ用のシステムや仕組みが必要になります。システムがない場合は、都度名寄せ依頼を行う必要性があります。
- データがあまり点在しておらず、名寄せ用のシステム開発・保守が行える場合には、このアーキテクチャパターンが選択出来ると考えます。
- Tier1をデータプラットフォームで持ち、各Tierを分離するアーキテクチャ
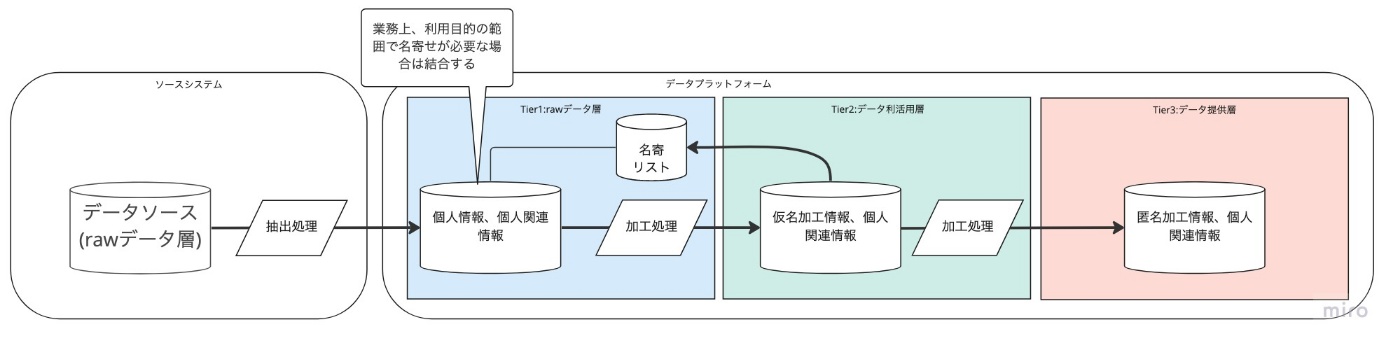
- データプラットフォーム側で、個人情報を扱うアーキテクチャになります。
- 個人情報がデータプラットフォームに送信されるので、Tier1層の扱いは非常に慎重になる必要があります。
- 一方で、名寄等の個人情報を利用目的の範囲内で活用する場合には、ソースシステムとは切り出して行う事が出来ます。
- 例えば、データが各所に点在していたり、データソース側で名寄せ用システムの開発・保守が難しい場合は、このアーキテクチャパターンが選択出来ると考えます。
3章 Google Cloudを中心とした個人情報の保護
ここまでは概念レベルでの解説でした。最後の章では、実際にGoogle Cloudを使ったパーソナルデータの保護・アーキテクチャについて、概要を説明します。
※解説のために空想で考えたアーキテクチャですのでご了承ください。
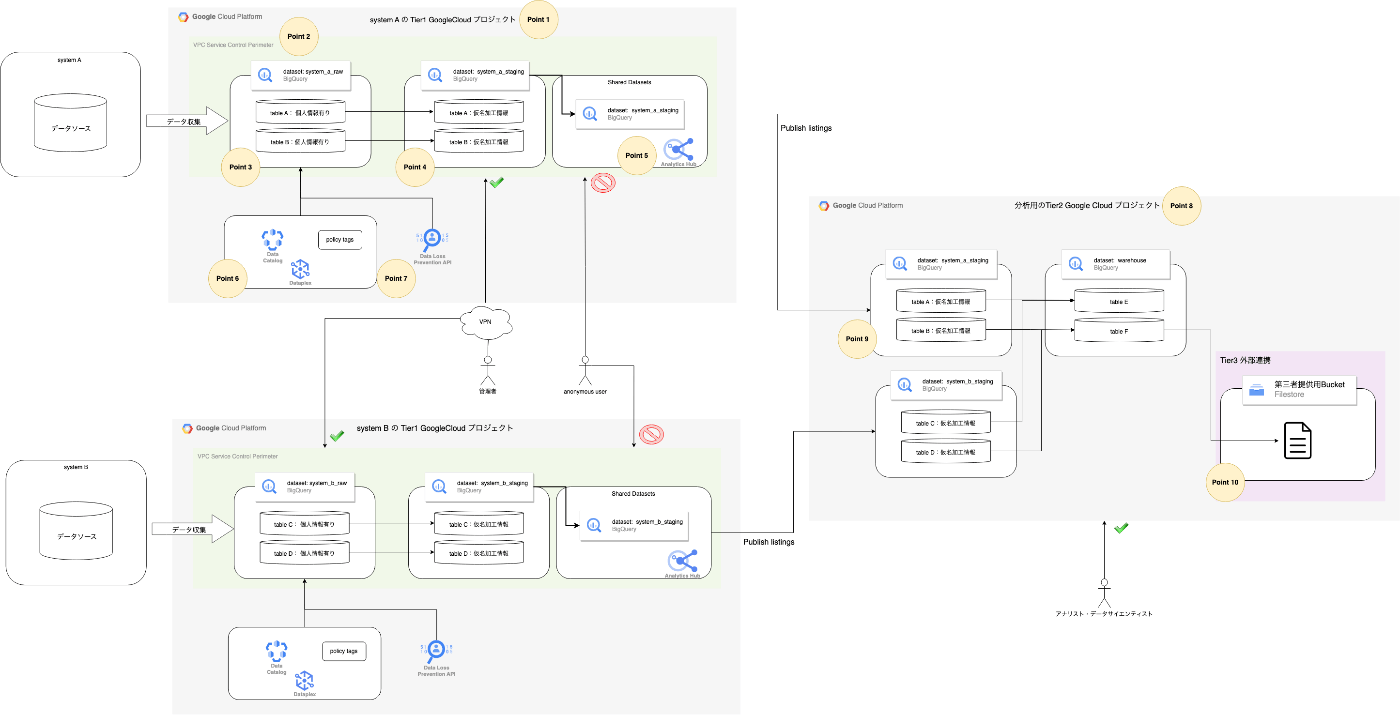
全体アーキテクチャ
全体像が流石に小さいですね。各セクション毎に説明していきます。
前提・目指した姿
- Tier1をデータプラットフォームで実現する事を前提としています。
- 例えば、各所にデータが点在しており、データプラットフォーム上で名寄せする必要があった。と考えましょう
- system A と system Bがそれぞれあり、個人情報を有するシステムのデータを活用したいニーズがあったとします。
- Tier1要件
- データプラットフォーム管理者がVPNを使ったアクセスのみ可能にする
- Tier1時点で、仮名加工情報に変換し直接識別情報を除いたり、間接識別情報・連絡情報などの加工を行う
- 安全で管理がしやすい形で、Tier2の分析環境に仮名加工情報を提供する
- 認証認可は、Google WorkspaceのアカウントとIAMを用いる
- 例え、Tier1にアクセスできる部署だったとしても、アクセス可能な個人情報と不可能な個人情報を分けられるようにする
- Tier2要件
- アナリストやサイエンティストなどがVPNを扱わなかったとしてもアクセス可能にする
- 認証認可は、Google WorkspaceのアカウントとIAMを用いる
- 加工した匿名加工情報もしくは本人同意済みの個人関連情報を第三者に提供する環境を構築する
Tier1
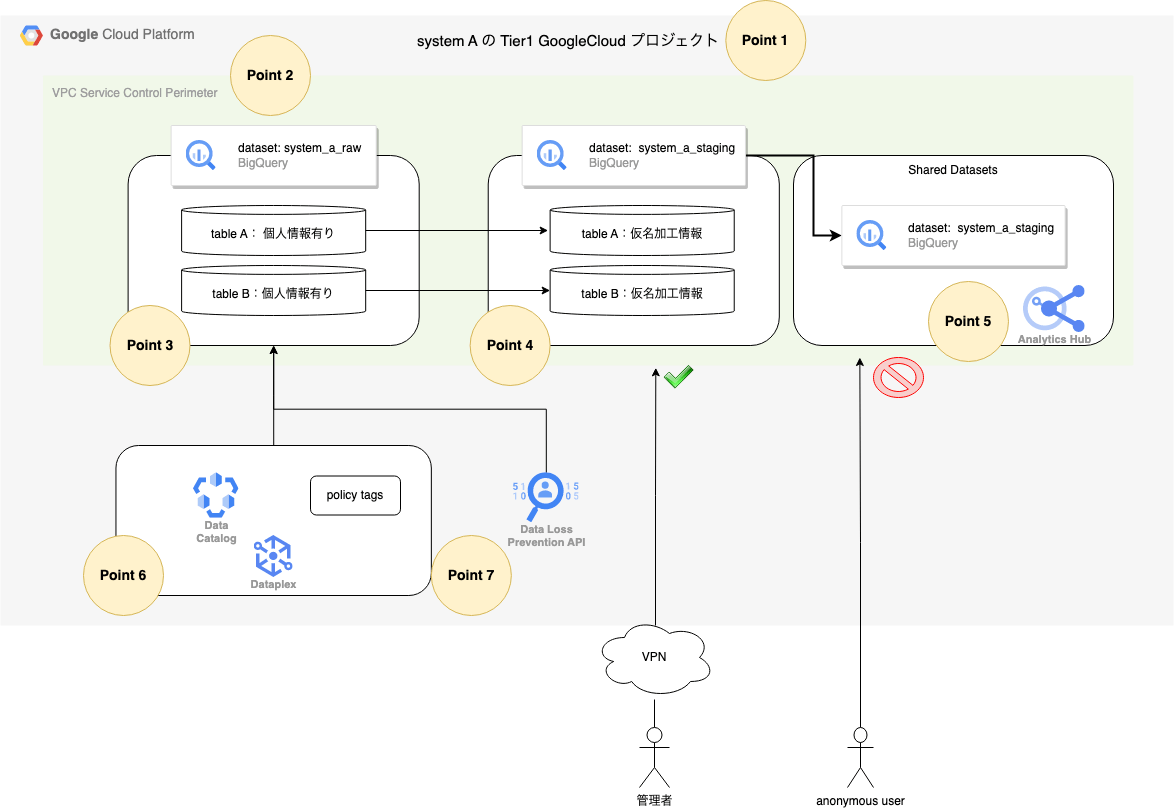
Tier1のアーキテクチャ
Tier1を各システム毎にGoogle Cloudプロジェクトを分離する形で、リスクの高いデータを閉じ込める考え方です。VPC Service ControlsやDataCatalog。Cloud DLPなどで2重、3重で防御を図ります
各Pointの補足情報
Point 1
- system A および system Bの個人情報を含むGoogle Cloudを構築します。
- このプロジェクトはアクセス可能なメンバーやアクセス元のネットワークは限定されます。
Point 2
-
VPC Service Controlsを活用しアクセス元を制限します。 - 限定されたネットワークからのアクセスのみ許可します
Point 3
- 元データ(rawデータ)を表します。このタイミングでは、直接識別情報などが未加工の状態で保管されています。
Point 4
- オーケストレーションツールなどでDAGを構築し、定期的に仮名加工情報を作成します。
- この際に、事前に加工しておくと便利な加工をしておくと良さそうですね。
- 例えば、enumの値を文字列にするなど
Point 5
-
Analytics Hubというサービスを使って、安全にTier2へのデータセット共有を行います。
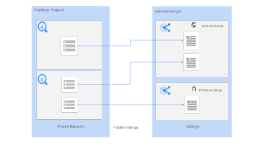
ref: https://cloud.google.com/bigquery/docs/analytics-hub-introduction?hl=ja - BigQueryのデータセット単位で、Projectの宛先を決めて共有する事が可能です。IAMによる共有も可能ですが、設定がBigQueryのデータセットに対して行うので非常に管理が為難い問題があります。
-
Analytics Hubであれば一元的に共有先が把握できるので、安全な利用が促せます。
Point 6
- Dataplexサービスの、
Data CatalogとPolicy tagsを活用します。-
Data Catalogは各データセット、テーブル、カラムの説明をカタログ情報として管理できます。これにより、利用者・分析者へ正しいデータの情報を伝える事が可能です -
Policy tagsはカラムレベルでのアクセスコントロールに役立ちます。例えば、テーブル自体は参照可能だが、直接識別情報はアクセスさせたくない。といった挙動を実現することが可能です。- 詳細は、GoogleCloudの記事をご確認ください。
-
Point 7
-
Cloud DLPというサービスを使って、個人情報の検知を行います。 - 勿論事前に定義・分類を行いますが、システムは常に更新されるもので、個人情報も意図せず入ってくることが考えられます。
- 正規表現などのパターンマッチにて、データを探索して個人情報が意図せず混入していないか定期的に検査し、意図しないものが検知されれば即時対応を行います。
Tier2
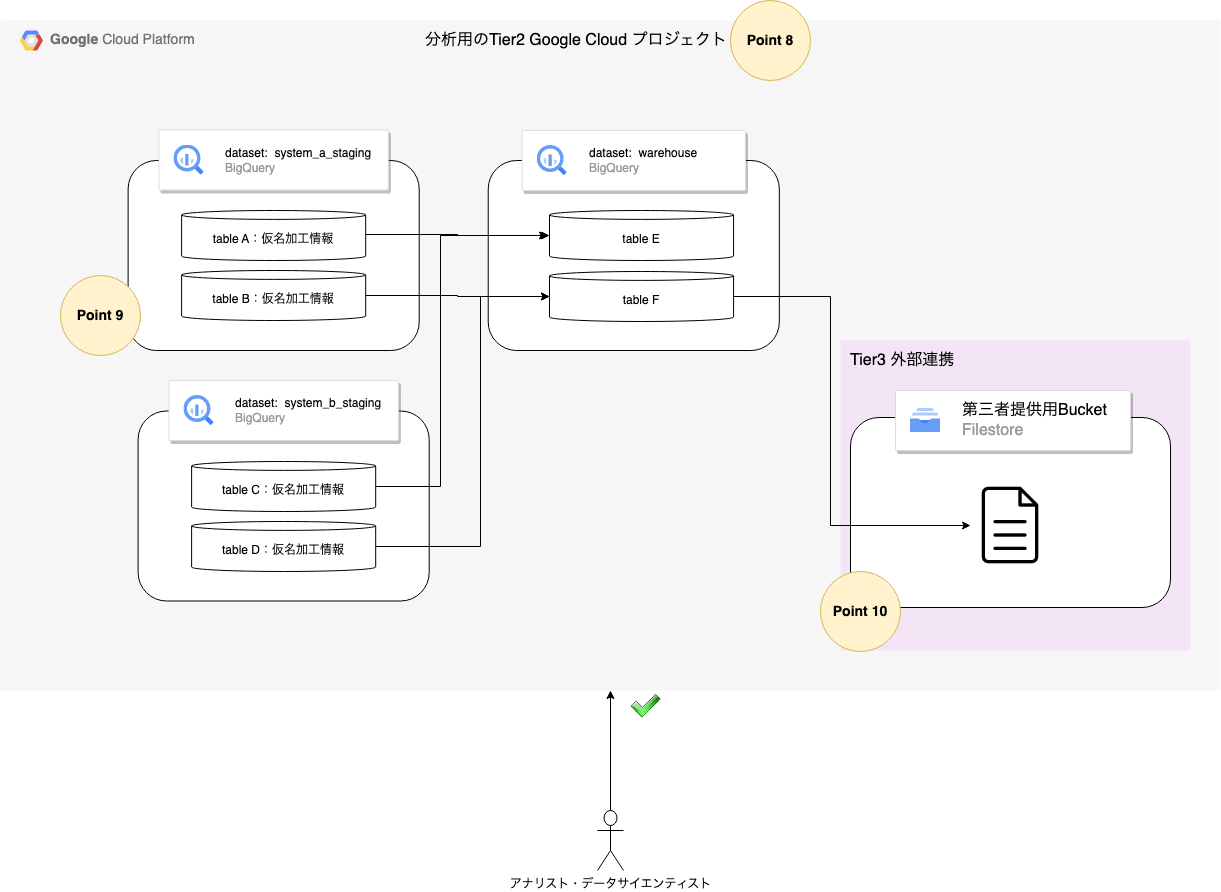
Tier2のアーキテクチャ
Tier2は、データ利活用層として整えられた環境です。system A および system Bから仮名加工情報がAnalytics Hub を経由して連携されるので、アナリストやデータサイエンティストは、Tier1のプロジェクトがどうなっているかわかりません。
また、プロジェクトを更に分ける場合もありますが、このパターンでは、Google Cloud Storage をTier3として定義し、第三者提供用の環境を構築しています。
各Pointの補足情報
Point 8
- このプロジェクトは、Tier2で社内利用を想定したデータ利活用環境として定義
- Tier1から法律・倫理・規約・プライバシーポリシーの観点から問題の無いデータを連携受ける
- ネットワークアクセス制限などは比較的緩和されている環境
- IP制限はセキュアに保つ有効な手段ですが、SaaSサービスによってはアクセス元IPが特定出来ない場合があり、利用が阻害される場合があります。それを想定して、緩和している立て付けです。
Point 9
- Tier1 から
Analytics Hubを経由して送信されたデータセットです。Tier1のデータセット名で、Tier2のプロジェクトのデータセットとして登録されます。 - アナリストなどの利用者は、Tier1データへのアクセス権限は不要であり、Tier2のBigQueryへの権限さえ持っていればアクセス可能です。
Point 10
- Tier2のデータから、個人関連情報(同意済み)および匿名加工情報を抽出し提供する層になります。
- この例では、Google Cloud Storageにファイルとして連携しています。
アーキテクチャを考えてみて
- 実際には足らない要素やサービスなどがありますが、セキュリティに限って記載してみました。
- 昨今ですと、データメッシュアーキテクチャを聞きますが、それを意識して情報のリスクとアクセス範囲を適切に分離出来たのでは無いかと考えています。
- 実際に検証中のため、大規模な実例はまだまだこれからですが、データメッシュならではの苦労といった点が分かってきたら投稿したいと考えています。
最後に
パーソナルデータの扱いは、各社ルールや定義があるかと思いますが、法務観点やセキュリティ部署観点の記載が多く、データプラットフォーム・活用観点で個別に定義することは少なくとも私の周りではあまり有りませんでした。
なんとなく理解していた状況ですが、今回整理する中で、なんとなく分かっていたつもりがより具体的な理解に深掘れたと思います。やっぱりアウトプットって良いですね。
良いお年を
Discussion