自問自答することで正解を導きだすAI!Self-ask
| Title | Measuring and Narrowing the Compositionality Gap in Language Models |
|---|---|
| authors | Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A. Smith, Mike Lewis |
| organizations | Paul G. Allen School of Computer Science & Engineering, University of Washington, MosaicML, Meta AI Research, Allen Institute for AI |
| conference | |
| link | https://arxiv.org/abs/2210.03350 |
| github | https://github.com/ofirpress/self-ask |
概要
GPT-3を筆頭とした大規模言語モデルは、モデルサイズが大きくなるに連れて質問応答性能が著しく向上する。例えば、How long was Queen Elizabeth’s reign? (エリザベス女王の在位期間は?)というような質問に答えるのは容易である。ただ、これが膨大なコーパスの暗記によるものなのか、推論によって導き出しているものなのかは依然として不明である。
そこで、事実と事実を組み合わせたマルチホップ質問に対してどれだけ正解できるかによってcompositional ability (構成能力) が備わっているかを定量的に調査した。その結果、言語モデルが大規模化しても、構成的な推論を行う能力が上昇しないことを発見した(下図の緑と青の差がモデルサイズを大きくしても埋まっていない)。

そこで、chain of thoughtのような直感的なプロンプトがこのCompositionality Gapを縮小させることを示した。さらに、chain of thoughtを改良した新しい手法であるself-askを提示した。self-askでは、質問を自問自答しながら分割することで正しい正解を導き出す。さらに、このself-askでは検索エンジンを簡単にプラグインできることを示し、精度をさらに向上できることを示した。
Compositional ability (構成能力)をどうやって定量化した?

上記のように2つの質問で構成される1つの質問を作成した。この全体の質問と、2つの質問の正答率を測った。それがCompositionality Gap。このCompositionality Gapがモデルパラメータが増大しても変化がないことを確認した。
これを測定するために、Compositional Celebrities (CC) データセット新たに作成。これは、有名人のステータスと、それに関連する事実を組み合わせて生成した質問のデータセットだ。
self-askとは?
Chain of thoughtでは、正解の根拠を自問自答するように解答を導き出す手法。これに対して、提案するself-askは、マルチホップ質問をより単純なサブ質問に分解し、次にサブ質問に答え、最後にメイン質問に答えるというプロンプト。
実際の例を見た方がわかりやすい。


どんな実験で確かめた?
既存のデータセット2WikiMultiHopQA・Musiqueと、新たに作成したBamboogle・CCを使用した。比較手法としては、Direct prompting、Chain of Thought、Self-ask、Self-ask + Search Engineの4つの手法を用いた。
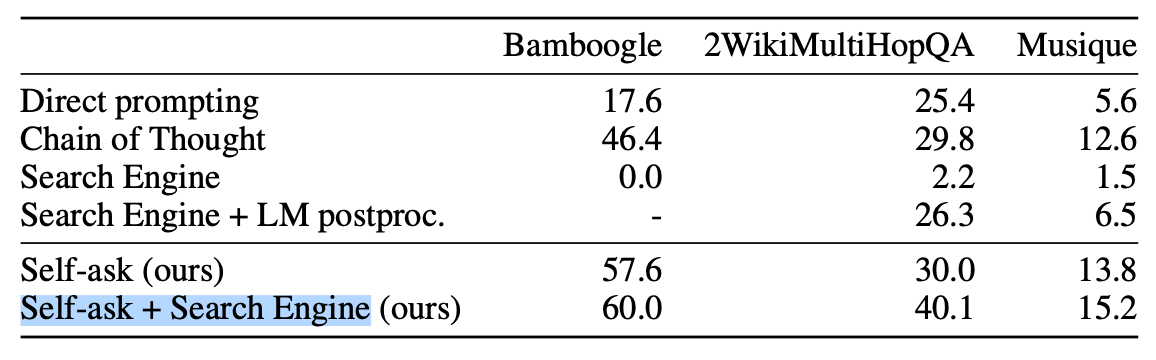
Self-ask + search Engineが圧倒的に高精度。
まとめと所感
langchainでも活用されているself-askに関して簡単にまとめました。基盤モデルを使いこなす研究はここ最近ホットな研究分野です。日頃からキャッチアップしていきたい分野ですね。
とはいえこのself-askもかなり直感的にわかりやすい研究だと思います。逆にいえば、まだLLMはその理論を理解しきれていない部分も多いようです。
In-context learningの理論的解明に近づこうとしているこちらのような論文も重要になってくるかもしれません。
Discussion