OpenAI sora technical report まとめ





初めに
先日(2024年2月15日)openaiから,ビデオ生成AI「sora」の概要とテクニカルレポートが発表されました.ありとあらゆる人がtwitterなどでその凄さを発信していますが,マルチモーダルAI・コンテンツ生成の研究開発に携わっている身として,soraに関して考察しようと思いこのノートにまとめていきます.
sora technical report サマリー
Video generation models as world simulators
video generation models is a promising path towards building general purpose simulators of the physical world.
soraはこれまでの研究(RNN・GAN・Transformer・Diffusion model)とは異なり,visual dataの汎用モデルであり,最大1分間の高解像度ビデオを生成できる.また,さまざまな長さ,アスペクト比,解像度のビデオと画像を生成することができる.
Turning visual data into patches
- LLMがtext tokensを持つように,Soraはvisual pathesを使用する.このvisual patchesが効果的な表現方法であることは先行研究より明らか[15,16,17,18].
- ビデオを低次元の潜在空間に圧縮することで,ビデオをパッチに変換.[19]

[15] Dosovitskiy, Alexey, et al. "An image is worth 16x16 words: Transformers for image recognition at scale." arXiv preprint arXiv:2010.11929 (2020).
[16] Arnab, Anurag, et al. "Vivit: A video vision transformer." Proceedings of the IEEE/CVF international conference on computer vision. 2021.
[17] He, Kaiming, et al. "Masked autoencoders are scalable vision learners." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.
[18] Dehghani, Mostafa, et al. "Patch n'Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution." arXiv preprint arXiv:2307.06304 (2023).
[19] Rombach, Robin, et al. "High-resolution image synthesis with latent diffusion models." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.
Video compression network
- 生のvideoを入力として受け取り,時間的・空間的に圧縮された潜在表現を獲得するネットワークを学習.Soraはこの圧縮された潜在空間でトレーニングされ,その後,この圧縮された潜在空間内でビデオを生成する.生成された潜在空間をピクセル空間にマップし直すでデコーダモデルもトレーニングする.[20]
❓ [気になる点] 学習データセットは何?
世の中に溢れるビデオデータセットの最大規模のものはEgo4D (Ego-Exo4D)であると思う.これも学習に使っているのか,これ以上の規模のデータセットを作成したのか,
[20] Kingma, Diederik P., and Max Welling. "Auto-encoding variational bayes." arXiv preprint arXiv:1312.6114 (2013).
Spacetime latent patches / Scaling transformers for video generation
- Soraは, noisy patchesとtext prompsなどのコンディション情報を受け取って動画を生成するdiffusion transformersである.[26]
- diffusion transformersを学習するにつれて品質が改善していくことを確認した(以下ビデオ).

[26] Peebles, William, and Saining Xie. "Scalable diffusion models with transformers." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023
💫 Scalable Diffusion Models with Transformersとは?
U-netアーキテクチャーをlatent patchを処理できるtransformerに置換したモデル.(ICCV2023)
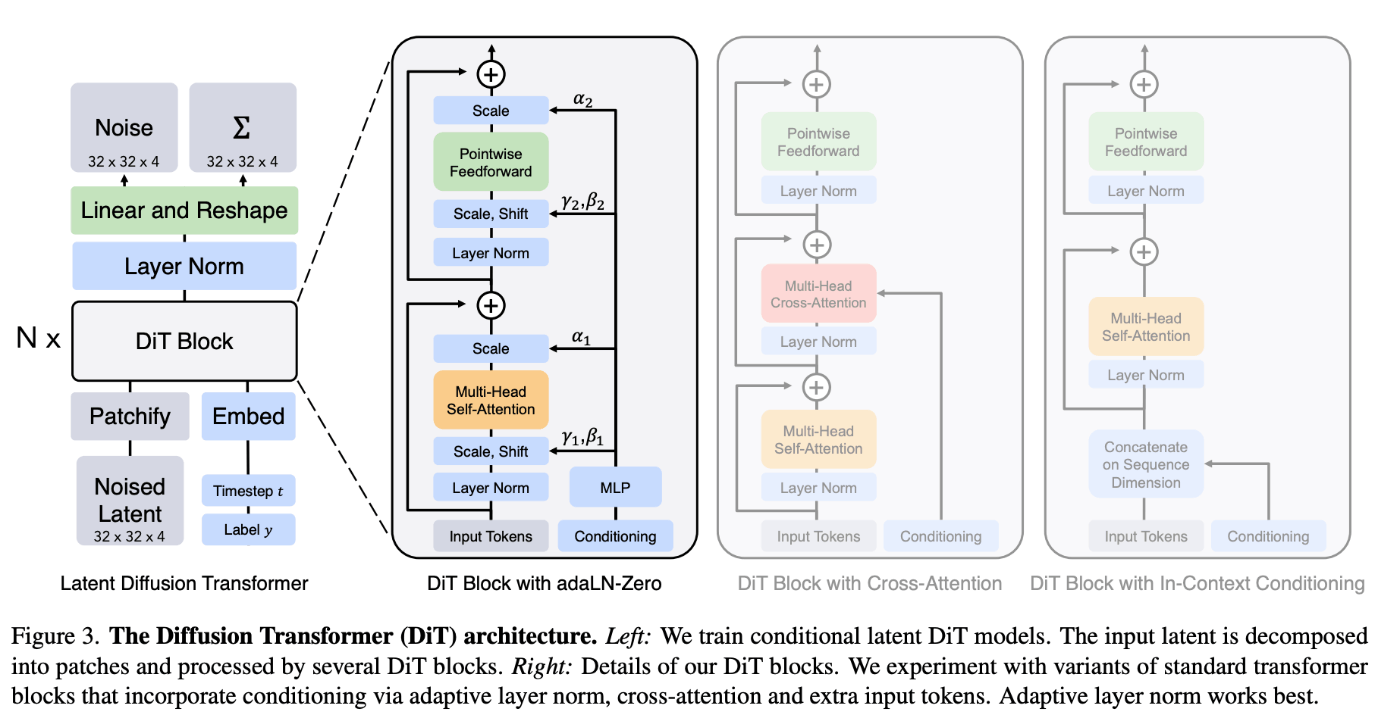
Variable durations, resolutions, aspect ratios
- これまでのアプローチでは,画像・動画を2562564などの解像度に圧縮して学習していたが,soraではそのままの解像度で学習している.
- そのため,ワイドスクリーン(19201080px)や,垂直ビデオ(10801920),その間の全てのサイズのビデオを生成できる.
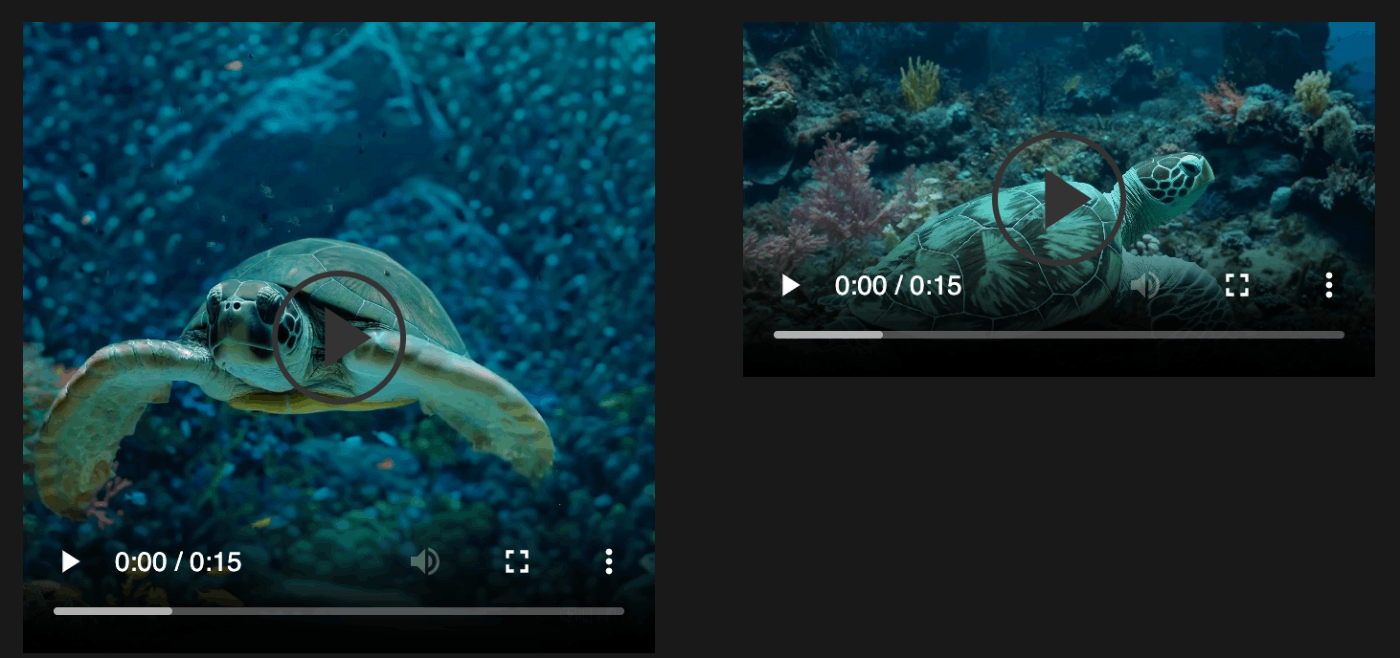
Improved framing and composition
- ネイティブのアスペクト比でビデオを学習すると,構図とフレーミングが改善された.
- 以下の左のビデオが正方形にトリミングして学習したもので,右がネイティブアスペクト比で学習したもの.
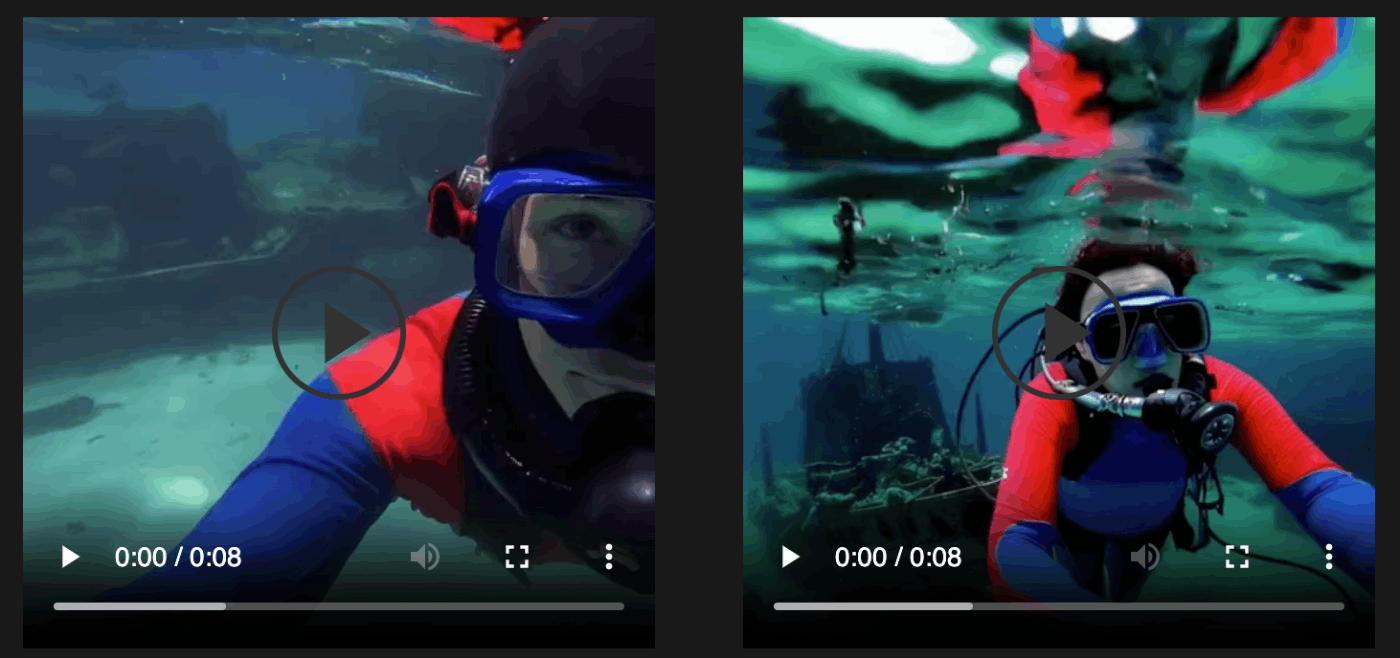
(とはいえ256*256モデルでも鏡面反射が自然すぎる...
Language Understanding
- ビデオに対して,非常に説明的なキャプションを生成するモデルをトレーニング.
- これを用いて学習データセットの全てのビデオに対してキャプションを生成.
- 推論する際は,短いユーザのpromptをGPTを利用して説明的な長いpromptに内部で変更している.



Prompting with images and videos
- 画像からの映像生成
Prompt: In an ornate, historical hall, a massive tidal wave peaks and begins to crash. Two surfers, seizing the moment, skillfully navigate the face of the wave.

- soraは,ビデオの時間を前後に延長することができる
- これを拡張して,無限ループするvideoを作成できる.
- video-to-video変換も可能
- 二つのビデオをシームレスに繋げることもできる.
Emerging simulation capabilities
- Sora は物理世界から人,動物,環境の一部の側面をシミュレートできる.これらの特性は,3D,オブジェクトなどに対する明示的な誘導バイアスなしで出現.これらは純粋にスケールすることによって出現した.
- **3D の一貫性.**Sora はダイナミックなカメラモーションを含むビデオを生成できる.カメラが移動したり回転したりすると,人物やシーンの要素が 3 次元空間内を一貫して移動する.

- ビデオの一貫性の保持.オクルージョンにも対応.

- 時間変化を加味して,絵の続きを描かせたりできる.
- デジタル世界のシミュレートもできる.
Discussion
- ガラスの粉砕など,物理学に基づく相互作用を正確にモデル化できていない.
- ビデオモデルの継続的なスケーリングが,物理世界とデジタル世界,およびその中に住む物体・動物・人々の有能なシミュレーターの開発に向けた有望な道であることを示していると信じている.
これからのAI分野の研究開発への影響を考える
Image/Video Captioning分野への影響
soraは,大量のvideoに対して自前のvideo captioning modelでアノテーションしたデータセットで学習されています.ここまで一貫性がありこ高品質なビデオを生成できることから考えても,相当高品質なvideo captining modelであると考えられます.(生成例の一部はテクニカルレポートに載っています.).しかもマインクラフトのシミュレーション環境が生成できることからも,仮想空間に対するvideo captioningも相当優れていると考えられます.
そもそも,soraの一部であるvisual encoderモデル自体がCLIPよりもはるかに優れたencoderモデルであり,「物体検出」「行動予測」などありとあらゆる下流タスクにも活用できそうです.
ゲーム・映像制作分野への影響
soraで生成した映像を用いて,NeRFで3D再構成したというポストが話題になっています.
この例でも見られるように,soraで生成した映像は3D復元できるほどのポテンシャルがあると思われます.これは,テクニカルレポートでも言及されていましたが,soraが,それほど一貫性のある映像を作成できるということを示しています.
近年,高品質かつ低コストで3D再構成が可能な3D Gaussian Splattingがホットな研究分野です.soraと3d-GSの発展により,テキストから3Dシーンを瞬時に生成できる未来がすぐそこまで来ています.
一方で,編集性というのも気になる点ではあります.
しかし,soraが画像をconditionとして映像を生成できる点や,

テキストpromptで映像を編集できる点を考えると,
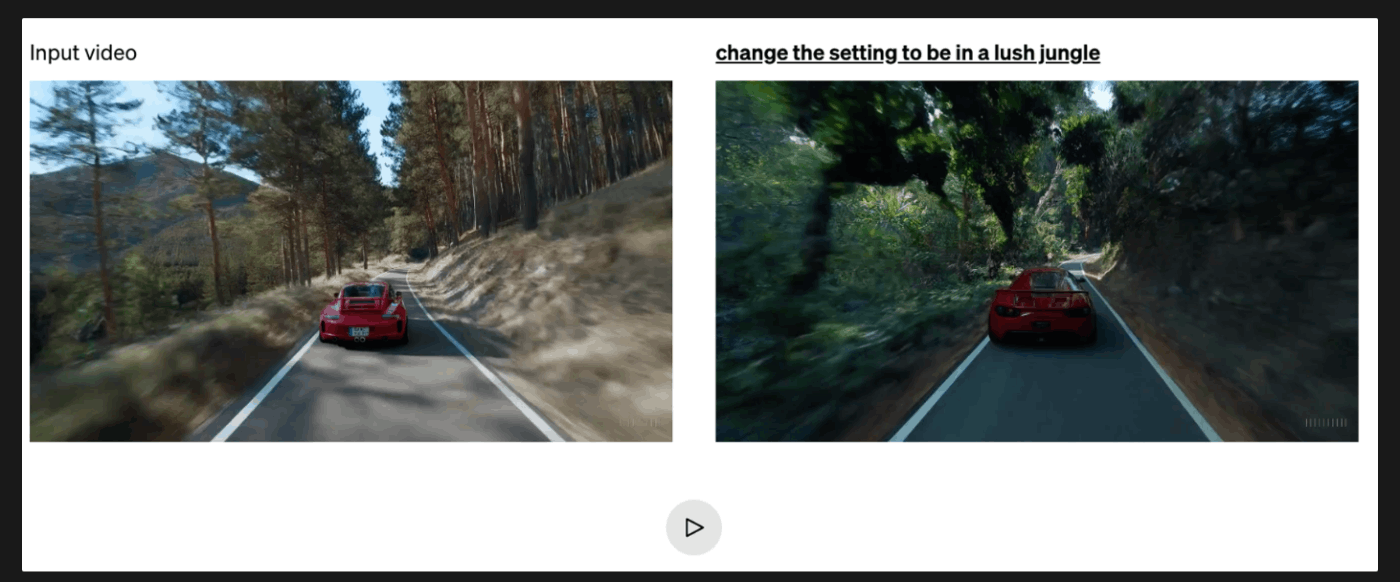
sora自体の編集性が高いために3Dシーンの編集は,容易にできるようになるのではないかと想像できます.画像自体は既に容易にテキストからも編集可能です.
また,soraは構図に対しても深い知識を有していると思われます.
テキストpromptで構図を指示して,所望のカットの映像を生成できることが期待されます.

これは映画制作におけるプリビズ制作においても大いに活用できそうです.とはいえ試してみないとその精度や有用性はわかりませんが.
soraのモデル構造を見る限り,おそらく画像コンディションとして複数枚の画像を与えられます.複数人の登場人物画像と,場所の画像をconditionとして入力し,ドラマのようなシーンを生成することも可能な気がします.
最後に
sora テクニカルレポートにおいて,soraの物理世界をシミュレーションできる能力はスケーリングによって発現したと書かれています.
スケーリング則と,Emergent Abilities(創発的能力)は,LLMで大きな話題になりましたが,soraにおけるEmergent Abilitiesは,さらに大きなインパクトがありますね...
LLMの出現によって,言語を扱うさまざまな事業(chatbot,翻訳,サマリーアシスト,執筆補佐など)が大きく変革したように,soraの出現によって映像を扱う事業でも大きな変革が起きることは確実だと思います.
とはいえ,この技術の変化を楽しみながら,新しい技術をどんどん使いこなしていきたいですね.
参考文献
Discussion