打率、OPSと得点を分析 with Python



⏰はじめに
この記事では Pyhton を使った野球の簡単なデータ分析を行います。ここでは「打率」「OPS」といった指標と「得点」との関係を分析します。以下の3つのようなことを行います。
- Baseball Reference からデータを読み込みます。
- 読み込んだデータから打率、OPSなど各指標と得点との関連を見るために、散布図をプロットします。
- 定量的に分析するために回帰分析を行います。
近年、出塁率と長打率の足し算から計算される指標「OPS(On-base Plus Slugging)」が様々なメディアでも取り上げられています。この記事の簡単な分析を行うことで、OPSの価値が分かるかもしれません。結論を言ってしまうと、打率よりもOPSの方が、攻撃力(打撃が強い←より多くの得点を生み出す力)を表現する数値としてより「あてになりそうだ」ということです。
👜準備
パッケージ
!pip install pandas html5lib beautifulsoup4 numpy scikit-learn matplotlib seaborn tqdm
- pandas:表の操作関連
- html5lib, beautifulsoup4:HTML、Web ページのデータの読み込み関連
- numpy, scikit-learn:数値、統計の計算関連
- matplotlib, seaborn:プロット関連
- tqdm:プログレスバーの表示
データ
MLB のチーム打撃成績(2010年~2022年)のデータを取得します。チーム打撃成績は打率、OPS、得点、安打などについてチームごとに平均 / 合計をとったものです。
Baseball Reference
Baseball Reference (BR)は Sports Reference による野球情報サイトです。野球(MLB)の情報サイトは他に MLB 公式、Fox Sports、ESPN などが有名です。BR はそれらに比べてチープな見た目のサイトですが、かなり細かい情報まで載っています。
例えば、2022年のチーム打撃成績はこちらです。
"Share & Export" を押すと、CSV や Excel の形式などでもダウンロードできることが分かります。その中の "Get Link Table" を押してみると、文字通りこの表の URL が取得できます。ダウンロードした CSV、Excel を Python で開いてもいいのですが、ここではこの URL を活用し、Python でデータのダウンロードを行います。
Pandas
今回のような表データを扱うのに、Pandas はぴったりです。Pandas を使うことで、データの読み込みから加工まで効率的に行うことができます。
以下のようにして、さきほどのテーブルの URL から、データを読み込みます。
import pandas as pd
url = 'https://www.baseball-reference.com/leagues/majors/2022-standard-batting.shtml#teams_standard_batting'
result = pd.read_html(url) # データの読み込み
print(len(result)) # 読み込みこまれたデータの数
df = result[0] # 結果に含まれるデータを取り出す
print(df) # データの表示
1
Tm #Bat BatAge R/G G PA AB R \
0 Arizona Diamondbacks 57 26.5 4.33 162 6027 5351 702
1 Atlanta Braves 53 27.5 4.87 162 6082 5509 789
2 Baltimore Orioles 58 27.0 4.16 162 6049 5429 674
先ほどサイトで見た表と同じようなデータが読み込まれました。
今回は2010年から2022年までのデータを取得します。上では2022年のデータを読み込みましたが、他の年はどのように取得すればいいでしょう?結論を言うと、指定したURLの年に関する部分を任意にいじればOKです。
'https://www.baseball-reference.com/leagues/majors/2022-standard-batting.shtml#teams_standard_batting'
不安であれば「2022」の部分を任意の年に変えたURLにブラウザでアクセスしてみてください。その年のページに飛ぶはずです。これを利用し、以下のようにして2010年から2022年までのデータをまとめて取得し、CSV ファイルとして保存します。
import pandas as pd
import numpy as np
from tqdm.notebook import tqdm
import os
# year のデータを読み込む
def download_stat(year):
url = f'https://www.baseball-reference.com/leagues/majors/{year}-standard-batting.shtml#teams_standard_batting'
result = pd.read_html(url)
return result[0]
# start_year から end_year までのデータを取得し、各年で CSV を保存する
def main():
start_year = 2010
end_year = 2022
data_dir = '/content'
for year in tqdm(range(start_year, end_year+1)):
stat = download_stat(year)
name = f'leagues-standard-batting-{year}.csv'
stat.to_csv(os.path.join(data_dir, name), index=None)
main()
/content に2019年であれば leagues-standard-batting-2019.csv といった名前でデータが保存されました。
!head /content/leagues-standard-batting-2019.csv
Tm,#Bat,BatAge,R/G,G,PA,AB,R,H,2B,3B,HR,RBI,SB,CS,BB,SO,BA,OBP,SLG,OPS,OPS+,TB,GDP,HBP,SH,SF,IBB,LOB
Arizona Diamondbacks,45,28.7,5.02,162,6315,5633,813,1419,288,40,220,778,88,14,540,1360,.252,.323,.434,.757,94,2447,120,70,31,40,36,1119
Atlanta Braves,50,28.0,5.28,162,6302,5560,855,1432,277,29,249,824,89,28,619,1467,.258,.336,.452,.789,98,2514,104,60,25,35,39,1138
Baltimore Orioles,58,26.5,4.50,162,6189,5596,729,1379,252,25,213,698,84,30,462,1435,.246,.310,.415,.725,90,2320,111,71,22,37,8,1063
保存した、CSVファイルは以下のようにして見ることができます。
def read_stat(year, data_dir):
name = f'leagues-standard-batting-{year}.csv'
stat = pd.read_csv(os.path.join(data_dir, name))
return stat
read_stat(2022, '/content')
Tm #Bat BatAge R/G G PA AB R \
0 Arizona Diamondbacks 57 26.5 4.33 162 6027 5351 702
1 Atlanta Braves 53 27.5 4.87 162 6082 5509 789
2 Baltimore Orioles 58 27.0 4.16 162 6049 5429 674
前処理
分析に使用するにはデータを加工しなくてはいけません。
チーム名の処理
- 2010~2022の間にチーム名が変わっているチームがあります。それらを統一しないと、別々なチームとして扱われてしまいます。全データを読み込んでチーム名をカウントしましょう。
# 指定した年の範囲のデータを読み込み、1つのDataFrameにまとめる
def read_stat_all(start_year, end_year, data_dir):
list_stat = []
for year in tqdm(range(start_year, end_year+1)):
stat = read_stat(year, data_dir)
stat['year'] = year
list_stat.append(stat)
return pd.concat(list_stat)
start_year = 2010
end_year = 2022
data_dir = '/content'
stat_all = read_stat_all(start_year, end_year, data_dir) # 全データを読み込む
stat_all['Tm'].value_counts()
Arizona Diamondbacks 13
Atlanta Braves 13
Tm 13
League Average 13
Washington Nationals 13
Toronto Blue Jays 13
Texas Rangers 13
Tampa Bay Rays 13
St. Louis Cardinals 13
San Francisco Giants 13
Seattle Mariners 13
San Diego Padres 13
Pittsburgh Pirates 13
Philadelphia Phillies 13
Oakland Athletics 13
New York Yankees 13
New York Mets 13
Minnesota Twins 13
Chicago Cubs 13
Los Angeles Dodgers 13
Baltimore Orioles 13
Kansas City Royals 13
Houston Astros 13
Boston Red Sox 13
Detroit Tigers 13
Colorado Rockies 13
Milwaukee Brewers 13
Cincinnati Reds 13
Chicago White Sox 13
Cleveland Indians 12
Miami Marlins 11
Los Angeles Angels 7
Los Angeles Angels of Anaheim 6
Florida Marlins 2
Cleveland Guardians 1
Name: Tm, dtype: int64
Los Angeles Angels of Anaheim → Los Angeles Angels や 最近では Cleveland Indians → Cleveland Guardians などがあります。また、Tm、League Average というのは表の下の方にある合計と平均に関する行です。チーム名の変更に対応するには、基本的には対応関係を地道に教えて、統一するしかないでしょう。データの規模が大きい場合では、より効率的な加工アイデアを考えなくてはいけませんが、ここでは泥臭く処理します。チーム名は変更後で統一します。以下のように、対応関係を示した dictionary を定義し、チーム名を統一します。また、Tm、League Average 行を削除します。
def reshape_team_name(stat_all):
# 対応関係の dictionary
dict_team_name_replace = {
'Cleveland Indians':'Cleveland Guardians',
'Florida Marlins': 'Miami Marlins',
'Los Angeles Angels of Anaheim': 'Los Angeles Angels',
}
# 削除する行
list_team_name_delete = [np.nan, 'Tm', 'League Average']
stat_all = stat_all[~stat_all['Tm'].isin(list_team_name_delete)] # 行の削除
stat_all = stat_all.replace({'Tm': dict_team_name_replace}) # チーム名を統一
return stat_all
stat_all = reshape_team_name(stat_all)
print(stat_all['Tm'].value_counts())
Arizona Diamondbacks 13
Atlanta Braves 13
Toronto Blue Jays 13
Texas Rangers 13
Tampa Bay Rays 13
St. Louis Cardinals 13
San Francisco Giants 13
Seattle Mariners 13
San Diego Padres 13
Pittsburgh Pirates 13
Philadelphia Phillies 13
Oakland Athletics 13
New York Yankees 13
New York Mets 13
Minnesota Twins 13
Milwaukee Brewers 13
Los Angeles Dodgers 13
Los Angeles Angels 13
Kansas City Royals 13
Houston Astros 13
Miami Marlins 13
Detroit Tigers 13
Colorado Rockies 13
Cleveland Guardians 13
Cincinnati Reds 13
Chicago White Sox 13
Chicago Cubs 13
Boston Red Sox 13
Baltimore Orioles 13
Washington Nationals 13
Name: Tm, dtype: int64
📈プロット
用意したデータを使って散布図をプロットしましょう。今回は「得点」と他の打撃指標との関係を見ます。まずは得点と打率(BA)との散布図をプロットします。
import matplotlib.pyplot as plt
import seaborn as sns
def main(data, target):
fig, ax = plt.subplots(figsize=(6, 6))
sns.scatterplot(data=data, x=target, y='R', hue='year',
ax=ax, palette='deep')
plt.show()
main(stat_all, 'BA')
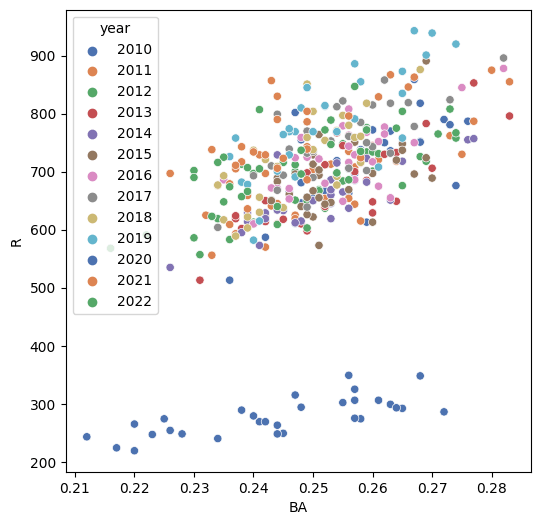
プロットできました。しかし、図上部のカラフルな群と下部の青色の群が分離していることが気になります。下部の青色の群は2020年のデータです。2020年はコロナ短縮シーズンだったため、積み上げ指標の得点(R)は他の年に比べ少なくなっています。2020年のデータはここではあまり役に立たないので、除外しましょう。
main(stat_all[stat_all['year']!=2020], 'BA')

得点と打率には正の相関関係があるように見えます。
打率以外の指標についても散布図をプロットしてみましょう。以下では出塁率(OBP)、長打率(SLG)、OPS、OPS+ のついてプロットします。
main(stat_all[stat_all['year']!=2020], 'OBP')

main(stat_all[stat_all['year']!=2020], 'SLG')

main(stat_all[stat_all['year']!=2020], 'OPS')

main(stat_all[stat_all['year']!=2020], 'OPS+')

打率に比べてこれらの指標はばらつきが少なくプロットされていることが分かると思います。打率とOPSに着目すると、例えば OPS 約.750の球団の多くは700点~800点くらいに分布しており、そのくらいの点を取るのかなと予測できます。一方、打率約.250の球団は600点~850点くらいに分布しており、どのくらい点を取るのか予測しづらいです。今あげたものは、ほんの一例ですが、もっと細かく見ていけば、ばらつきのある散布図からインサイトを引き出すことが難しいことに気づくはずです。

✨回帰分析
予測のしやすさを定量的に図ることに回帰分析を活かすことができるかもしれません。最小二乗法による線形回帰直線の決定係数は説明変数(打率やOPS)が目的変数(得点)をどれくらい説明できるかを測る指標として用いられます。決定係数が大きい値をとる場合、回帰モデル(直線)のあてはまりが良いと考えられます。
以下のように、説明変数:打率 / OPS、目的変数:得点として回帰モデルと決定係数を計算します。また、回帰直線を散布図に重ねてプロットします。
from sklearn.linear_model import LinearRegression
# 回帰モデルを計算する
def build_model(x, y):
model = LinearRegression()
model.fit(x, y)
return model
# 回帰直線の式、決定係数を整形して表示する
def print_summary(model, x, y):
print(f'y= {model.coef_[0][0]:.3f}*x + {model.intercept_[0]:.3f}')
print('R^2: ', model.score(x, y))
def main(data, target):
# DataFrameから説明変数targetと得点を抽出する
x = data[[target]]
y = data[['R']]
# 回帰分析
model = build_model(x, y)
print_summary(model, x, y)
pred = model.predict(x) # 回帰直線
# プロット
fig, ax = plt.subplots(figsize=(6, 6))
# 散布図
sns.scatterplot(data=data, x=target, y='R', hue='year',
ax=ax, palette='deep')
# 回帰直線
sns.lineplot(
data={'x':x.values.reshape(-1), 'y':pred.reshape(-1)},
x='x', y='y'
)
plt.show()
main(stat_all[stat_all['year']!=2020], 'BA')
y= 3969.306*x + -288.387
R^2: 0.35490605922097573

main(stat_all[stat_all['year']!=2020], 'OPS')
y= 1947.314*x + -702.597
R^2: 0.8859455148019227

打率-得点の決定係数
以上です。間違い等があれば、ぜひご指摘ください。
Discussion