Kinesisについて一度整理する,
概要
kinesisについて自分なりに軽くまとめてみた。
経緯
業務で諸々kinesisを使っているが、一度も体系的に整理しておらず、ど素人がその都度調べて構築しているだけになっているので一度整理する。
前提
定義
Amazon kinesisとは
リアルタイムのストリームデータを収集、処理、分析するためのサービス。
機械学習や分析やその他アプリのストリームデータをリアルタイムで取り込めることができる。
Amazon Kinesis では、フルマネージド型サービスとして、あらゆる規模のストリーミングデータをコスト効率よく処理、分析します。Kinesis をお使いになると、機械学習 (ML)、分析、その他のアプリケーションに用いる動画、音声、アプリケーションログ、ウェブサイトのクリックストリーム、IoT テレメトリーデータをリアルタイムで取り込めます。
kinesis data streamとは
data streamはサーバレスのストリーミングデータサービスであり、あらゆる規模のデータストリームを簡単にキャプチャ、処理、保存することができる。
kinesis data streamを用いることで、リアルタイムで送信されたデータを選択したサービスにストリームすることができます。
Amazon Kinesis Data Streams は、サーバーレスストリーミングデータサービスであり、あらゆる規模のデータストリームを簡単にキャプチャ、処理、保存することを可能にします。
https://aws.amazon.com/jp/kinesis/data-streams/?nc=sn&loc=2&dn=2
kinesis data firehoseとは
ストリーミングされたデータをキャプチャ及び変換、データレイクやデータストア及び分析サービスに配信するETLサービスである。
Amazon Kinesis Data Firehose は、ストリーミングデータを確実にキャプチャおよび変換し、データレイク、データストア、および分析サービスに配信する、抽出、変換、ロード (ETL) サービスです。
kinesis video streams
分析、機械学習、再生及びそのほかの処理のため、接続されたデバイスからAWSへ動画を簡単かつ安全にストリーミングできるようにする。
Amazon Kinesis Video Streams を使用すると、分析、機械学習 (ML)、再生、およびその他の処理のために、接続されたデバイスから AWS へ動画を簡単かつ安全にストリーミングできるようになります。Kinesis Video Streams は、数百万ものデバイスからの動画のストリーミングデータを取り込むために必要なすべてのインフラストラクチャを、自動的にプロビジョンして、伸縮自在にスケールします。
ユースケース
kinesis全体の使用ケースとしてはストリーミングデータの収集および分析ですので、リアルタイムにデータが送信されたり、分析結果の反映に即時性が求められるケースでの使用が望ましい。
公式からは以下などがユースケースとして挙げられている。
- リアルタイムアプリケーションの作成
- 従来バッチ処理で分析されていたのをリアルタイム分析に進化
- IoTデバイスデータの分析
- 動画分析アプリケーションの構築
Data streamに関してはその中でもストリーミングデータの収集サービスで、センサーデータであったり、クッリクストリームデータ、アプリケーションから送信されたユーザーイベントデータを収集するのに用いられる。
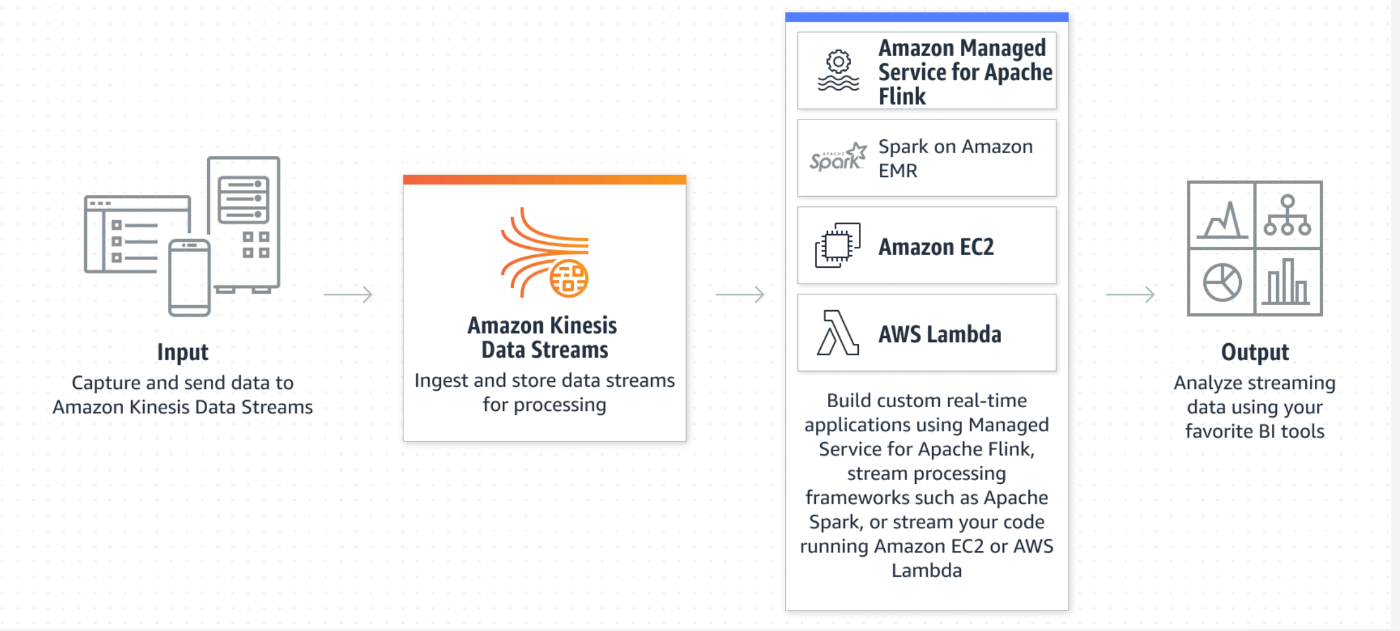
そしてData streamなどで収集されたストリーミングデータをデータレイクおよびデータウェアハウスにストリーミングする役目を行うのがFire hose.
溜まったストリーミングデータをデータレイクに保存するのにアプリケーションコードなどの記述が不要になるサービスである。
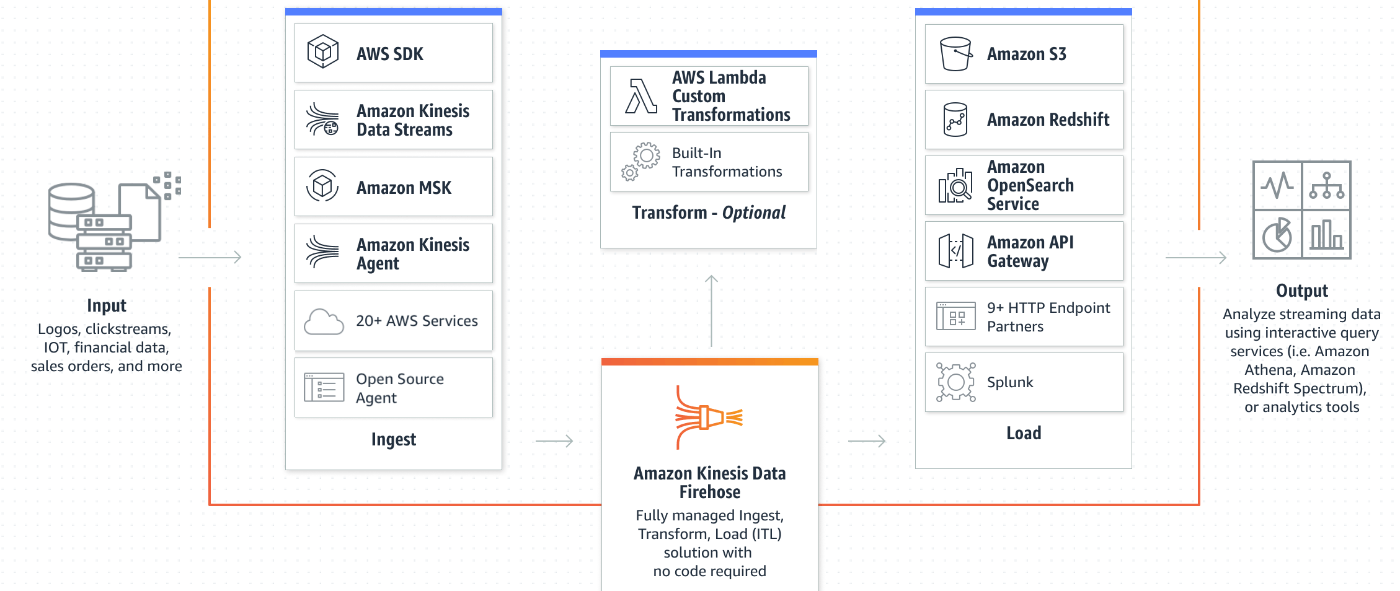
Data streamに関する例
を拝借。
概要を言うとdata lakeからs3にデータが保存されたら、AWS Database Migration Serviceを経由して Kinesis Data firehoseで大量のデータを捌く構成となっている。
送信先はlambdaだったり、firehoseだったり様々な選択肢が書かれている。
データレイクもしくはthird party applicationという様々なデータをs3に一元的に集めてそこからkinesis data stramに流すことによって、
データ統合もデータの利用の幅も広がりやすくなっている。
(様々なデータをdata streamから特定のtargetに送ることもできるし、送るのをこまめに指定することもできる。)
ちなみにfirehoseにストリーミングデータを送信する際は、リアルタイムにストリーミングとはいってもリクエスト、レスポンスのような速度でストリーミングされる決まりではなく、kinesis fire hoseにてユーザー側で設定できるbuffer sizeもしくはbiffer 間隔によって送信間隔が設定できるようになっている。
この設定によって一つ一つのデータが少量だった場合にある程度まとめて送信したいなどの王権も満たすことができる。
パーティションキーなどの設定の仕方によって,ストリーム内のデータレコードの一意に識別されたグループを示すシャードのどこに送信するかが設定できるようになっている(自分も理解あやふや)
シャード:シャードは、ストリーム内の一意に識別されたデータレコードのシーケンスです。ストリームは複数のシャードで構成され、各シャードが容量の 1 単位になります。各シャードは、読み取りに対して最大 5 つのトランザクションをサポートできます。最大総データ読み取りレートは 2 MB /秒、書き込みの場合は最大 1,000 レコード/秒、最大 1 MB /秒(パーティションキーを含む)のデータ書き込みレート(パーティションキーを含む)です。ストリームのデータ容量は、ストリームに指定したシャードの数によって決まります。ストリームの総容量はシャードの容量の合計です。
パーティションキー:あるパーティションキーは、ストリーム内のデータをシャード単位でグループ化するために使用されます。Kinesis Data Streams は、ストリームに属するデータレコードを複数のシャードに配分します。
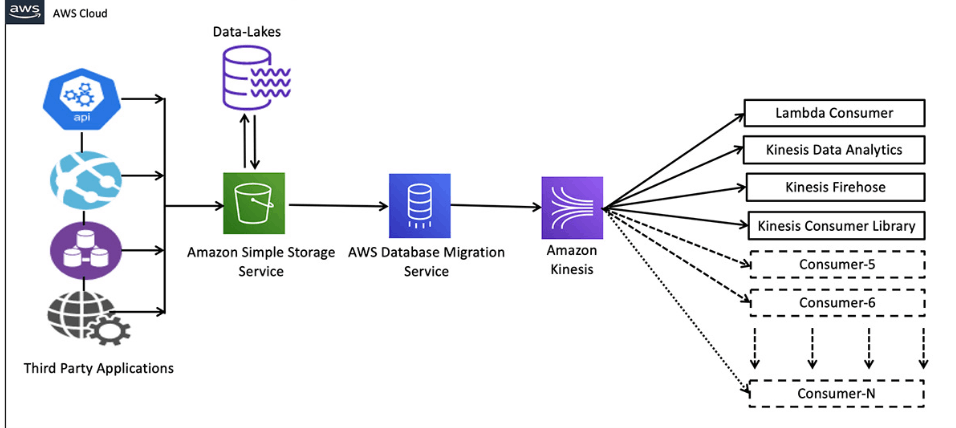
Data stream
Fire hoseに関する例
こちらを拝借させていただきました。
今度はfirehoseからs3に送信するケースで、firehoseが受け取ったデータをs3に保存するような構成となっている。
firehoseはs3に保存する際にpartitionなどを自動で切ってくれたり、特定のバケットの特定のフォルダ配下にデータを入れるなどの指定もできたりするので、
firehoseからs3にデータを保存する際にデータの管理がしずらかったりは恐らく生じないようになっており、至れり尽くせり。
最後に(これからも)
使っていながら全然理解できてない箇所も多かったし、今もそうだから継続的にこの記事の情報は更新していきたい。
(なんならetlツールとしてfire hoseを利用していなかったし笑)
駄文失礼いたしました。
参考文献
Discussion