distil-whisperであわよくば遊んでみる
概要
音声認識及び翻訳モデルで瞬足くらい速いやつがでたぞと巷(どこの)で噂になってたから触ってみた。
前提
定義
Whisper
OpenAI社が発表した音声認識モデルであり、多様な音声の大規模なデータセットでトレーニングしており、多言語音声認識、音声翻訳、言語識別を実行できるマルチタスクモデル。
Whisper is a general-purpose speech recognition model. It is trained on a large dataset of diverse audio and is also a multitasking model that can perform multilingual speech recognition, speech translation, and language identification.
githubはこちら:https://github.com/openai/whisper
このWhisperを用いてさらに高速化したのがこちら
Distil-Whisper
Whisperモデルを簡素化し、大きなモデルから作成された品質の良い疑似ラベルを用いて訓練することにより、Whisperより5.8倍速く、パラメータが51%少ないのに異なるテストデータに対しても同等の性能を示すモデルとなっている
Using a simple word error rate (WER) heuristic, we select only the highest quality pseudo-labels for training. The distilled model is 5.8 times faster with 51% fewer parameters, while performing to within 1% WER on out-of-distribution test data in a zero-shot transfer setting.
論文はこちら:https://arxiv.org/abs/2311.00430v1
githubはこちら:https://github.com/huggingface/distil-whisper
速くなったのに精度はほぼ同じっていうのはもはや排反やんと言いたいですね。
試す
https://huggingface.co/spaces/Xenova/whisper-web でまずはWhisperから試してみる。
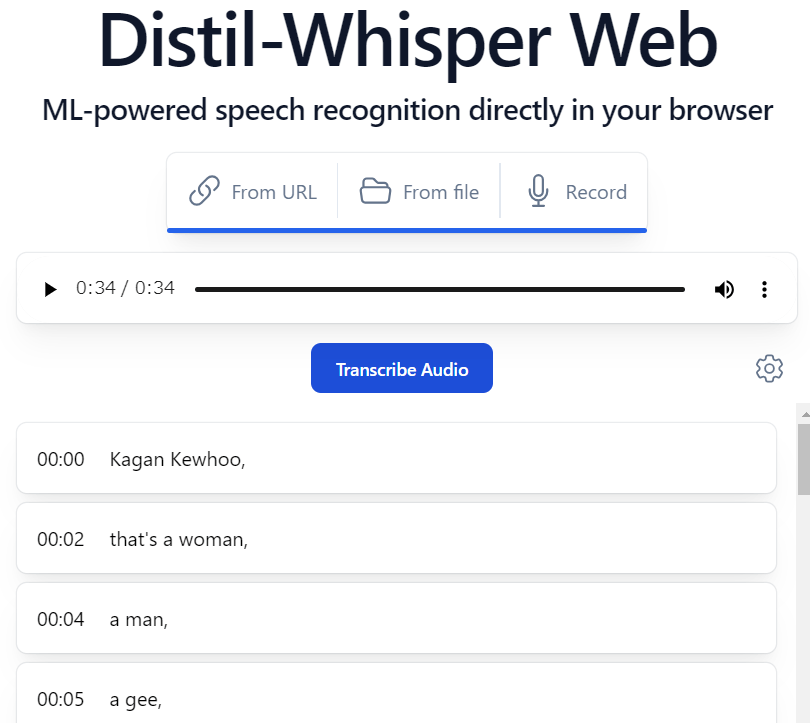
From URLのところをクリックするとどうやらサンプル音声URLがデフォルトで用意してくれていて、それをクリックすると以下のように音声が文字起こしされてくる。

カラダぐぅを試しに入力させてみたけれど正常に読み取ってくれへんかったけれど...

今度は
https://huggingface.co/spaces/Xenova/distil-whisper-web でDistil-Whisperを試す。
はやい、速すぎてホップしているぞって言いたかったんだがあんまり速くないぞ...
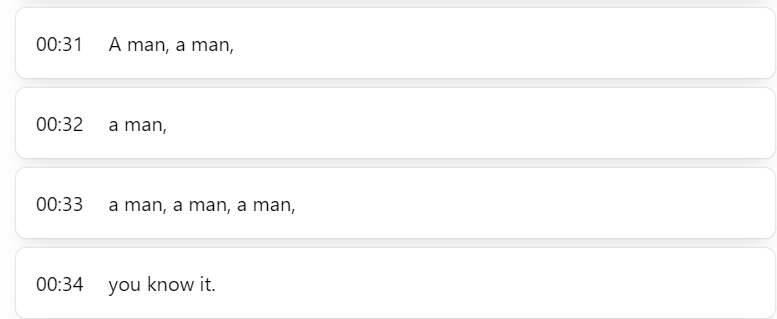
精度は変わらんが、皆試しすぎてWhisperの方は訓練しつくしてサンプル音声が速かったのかわからんので例のごとくDistil-Whisperにカラダぐぅを投入
なんと読み込まれたではないですか。
Karadaguxuuuuとなってほしかったところではあるが、Whisperではmusicとして読み込まれなかったのがモデルを小さくしたDistil-Whisperでは読み取られるのが面白いですね。
ただどちらにしよ遅いのはなぜだ?
結果
サンプルで試せるページで色々やってみたが、猛烈にDistil-Whisperの恩恵を感じれたといった結果は出ませんでした🙇
自分の試し方が悪かったかもなので後日またgithubのコードを自分で微調整して追記させていただきます...
(論文やドキュメント内容深掘りも含めて)
備考
自分で訓練させるときはからだぐぅを認識させるようにしたい。
あと日本語の歌も英語で翻訳するっぽくておもろい。
参考文献
Discussion