AirtableでNode-REDの使いどころ: 生産管理編
前回の続きです。
生産計画の自動スケジューリング時に休日を考慮して製造日数を割り出したい、外注も同じ...
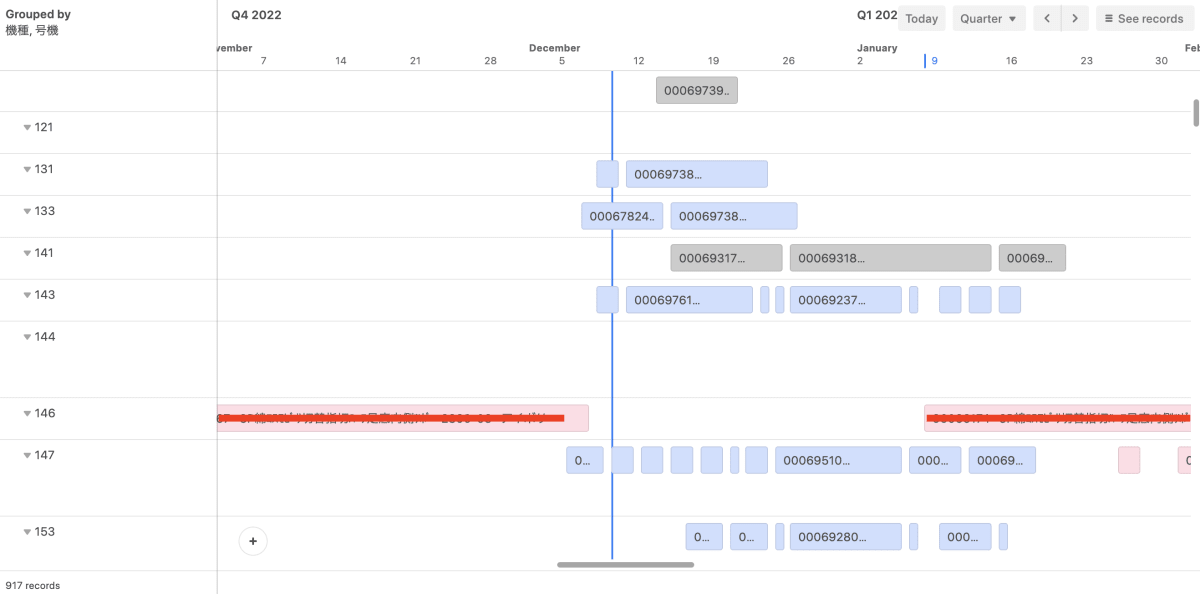
生産管理の中でも非常に需要が高いのが製造スケジュールの作成です。AirtableにはTimeline Viewという便利なビューがあって、以下の画像のように製造装置毎に製造計画を解りやすく俯瞰できます。
更にコレ、以前の記事で紹介した既存システムから吐き出されるCSVファイルを解析してアラート飛ばす事例を発展させ、既存システムのそばに配置したPCをenebularのエージェント実行環境にして以下のNode-REDフローを毎晩実行しています。
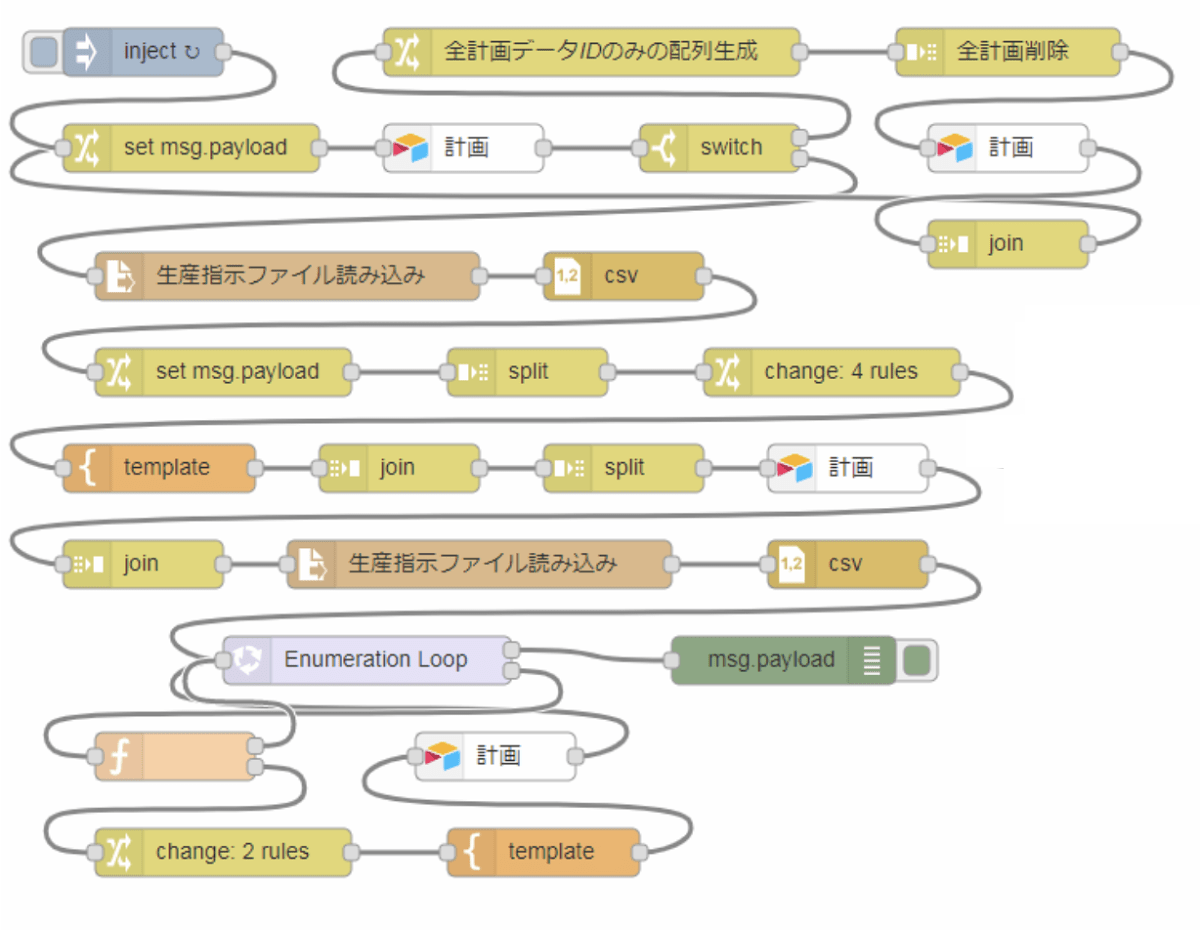
このNode-REDフローにより、Airtable側の生産管理baseの計画テーブルへオフィスのPCから日次で1,200レコードほどデータが投入されています。しかし、このデータは装置の号機名と製造開始日時・終了日時がブランクになっていますので、このままでは上の画像のようなTimeline Viewは表示されません(開始日と終了日があって初めてバーが表示されますし、号機がなければ画像のように号機でグルーピング表示もできません)
なぜブランクになっているかと言うと、ここが改善点なのですが、これまで既存システムで人が紙やファイルなど色々な媒体の情報を見ながら頭を捻って装置の号機名と製造開始日時・終了日時を手入力していたそうなんです。
1日1,200件...
もちろん、分担してやっていましたが、本来人間がやるべき仕事は他にあるだろうと、まさにDXを目指した結果、既存システムからは肝心の号機や製造開始日・終了日はブランクのままAirtableにデータ投入して、データが作成されたタイミングで自動的に最適な号機や製造開始日・終了日を導き出すenebularのクラウド実行環境にデプロイされたNode-REDフローに丸投げしようという形になったわけです。
以下がデータ投入されたタイミングで今度はenebularのクラウド実行環境を呼び出すAirtableのAutomationsです。

でもなんで既存システムのそばにあるPCで最適な号機や製造開始日・終了日を導き出す処理も実行しないんでしょうか?
それは、1台のコンピュータで最適化の処理を1,200回安全に回すには同期的に処理する必要があり、そううすると24時間で全ての処理が終わらないという計算になったためです。
つまり、号機や製造開始日・終了日がブランクなCSVデータをそのまま投入するだけのローカルの処理と、以下のAirtableとenebularのクラウド実行環境で実現される並列処理に分けることで、全体の処理を3時間で終わらせることができました(この辺の並列処理は10年前なら自分で頭捻って実装してましたがサービスに丸投げできる良い時代になりました)

では、また次回!
Discussion