有価証券報告書をベクトル化して散布図にプロット
概要
有価証券報告書から作成されたデータセットchABSA-datasetを使用して、文書をベクトル化します。
ベクトルをUMAPで次元圧縮し、Plotlyで可視化します。
可視化する内容は文章を単純にベクトル化したものと、tf-idfで特徴的な単語を抜き出した文章をベクトル化したものの2種類を使用し、tf-idfを使用した場合の方が業種区分ごとにまとまって出力されるかを確認します。
結果は目視でなんとなく確認し、どれぐらいの精度が出ているか定量的な評価はしていません。
環境
Google Colabを使用します。
データセット
以下で紹介されていたchABSA-datasetを使用します。
chABSA-datasetは、230社の有価証券報告書をデータ化してくれているものです。
このデータから以下を取得し、文書から作成したベクトルで散布図を描いた時に企業の17業種区分で分けられるか確認します。
- 企業名
- 企業の33業種区分
- 企業の17業種区分
- 文書
可視化までの流れ
chABSA-datasetのダウンロード
chABSA-datasetをダウンロードして展開します。
展開後は以下のようになっています。
!ls -ld /content/drive/MyDrive/nlp/data/chABSA-dataset
!ls -l /content/drive/MyDrive/nlp/data/chABSA-dataset | head -n 5
drwx------ 2 root root 4096 Oct 28 13:00 /content/drive/MyDrive/nlp/data/chABSA-dataset
total 3061
-rw------- 1 root root 15567 Jan 23 2018 e00008_ann.json
-rw------- 1 root root 11383 Jan 23 2018 e00017_ann.json
-rw------- 1 root root 28708 Jan 23 2018 e00024_ann.json
-rw------- 1 root root 11697 Jan 23 2018 e00026_ann.json
ライブラリのインストール
!pip install jaconv==0.3
!pip install ginza==5.1.2 ja_ginza==5.1.2
!pip install https://github.com/megagonlabs/UD_Japanese-GSD/releases/download/r2.9-NE/ja_gsdluw-3.2.0-py3-none-any.whl
!pip install plotly==5.5.0
!pip install umap-learn==0.5.3
ライブラリのインストール後、Google Colabのランタイム再起動をしなくても済むように以下を実施します。
import pkg_resources, imp
imp.reload(pkg_resources)
データセットの読み込み
データセットから以下を読み込みDataFrameに格納します。
- 企業名
- 企業の33業種区分
- 企業の17業種区分
- 文書
文書は簡単な前処理をしてからDataFrameに格納しています。
DataFrameのlemmaとvectorカラムはこの後でデータを格納します。
import glob
import jaconv
import json
import numpy as np
import pandas as pd
import re
import unicodedata
def read_data_file(dataset):
file_list = glob.glob('/content/drive/MyDrive/nlp/data/chABSA-dataset/*.json')
for file_name in file_list:
data = pd.DataFrame(columns=['name', 'cate33', 'cate17', 'sentence', 'lemma', 'vector'])
with open(file_name, 'r') as tmp_file:
tmp_json_file = json.load(tmp_file)
sentence = ''
for k in tmp_json_file['sentences']:
sentence += k['sentence']
sentence += ' '
sentence = sentence.lower()
sentence = jaconv.h2z(sentence, kana=True, digit=True, ascii=True)
sentence = unicodedata.normalize("NFKC", sentence)
sentence = re.sub(r'\d{1,3}(,\d{3})*', '0', sentence)
sentence = re.sub(r'[0-9]+', "0", sentence)
data['sentence'] = [sentence]
data['name'] = tmp_json_file['header']['document_name']
data['cate17'] = tmp_json_file['header']['category17']
data['cate33'] = tmp_json_file['header']['category33']
dataset = pd.concat([dataset, data])
return dataset
dataset = pd.DataFrame(columns=['name', 'cate33', 'cate17', 'sentence', 'lemma', 'vector'])
dataset = read_data_file(dataset)
データセットの業種ごとの出現頻度確認
dataset['cate17'].describe()
for index, value in dataset['cate17'].value_counts().iteritems():
print(index, ': ', value)
情報通信・サービスその他 : 44
電機・精密 : 23
建設・資材 : 23
素材・化学 : 22
商社・卸売 : 22
機械 : 17
小売 : 13
運輸・物流 : 11
食品 : 9
自動車・輸送機 : 9
銀行 : 8
金融(除く銀行) : 8
鉄鋼・非鉄 : 7
不動産 : 6
医薬品 : 4
エネルギー資源 : 2
電力・ガス : 2
今回は出現頻度の上位3業種に絞ります。
また、この段階ではインデックスがすべて0になっているのでインデックスをふり直します。
dataset = dataset.query("cate17 == '情報通信・サービスその他' or cate17 =='電機・精密' or cate17 == '建設・資材'")
dataset = dataset.reset_index().drop(['index'], axis=1)
単語のレンマ化
文を単語に分割しレンマ化します。
単語の分割には国語研長単位モデルを使用します。
import spacy
nlp_lemma = spacy.load('ja_gsdluw')
stop_words = nlp_lemma.Defaults.stop_words
def get_lemma(x):
tmp_list = []
doc_lemma = nlp_lemma(x)
for sent_lemma in doc_lemma.sents:
for token_lemma in sent_lemma:
if not token_lemma.lemma_ in stop_words:
tmp_list.append(token_lemma.lemma_)
tmp_text = " ".join(tmp_list)
return tmp_text
dataset['lemma'] = dataset['sentence'].apply(get_lemma)
tf-idfで特徴的な単語の抽出
有価証券報告書は似たような文章になりがちなので、TfidfVectorizerのmin_df=0で出現頻度の低い単語も拾うようにし、max_df=0.5で出現頻度が高い単語は切り捨てます。
tf-idfで重要と判定された単語の取得方法は、下記のサイトを参考にさせていただきました。
今回は重要と判定された単語のトップ20を使うこととしました。
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(min_df=0, max_df=0.5)
X = vectorizer.fit_transform(dataset['lemma'].to_list())
X_list = X.toarray()
index = X_list.argsort(axis=1)[:,::-1]
feature_names = np.array(vectorizer.get_feature_names())
feature_words = feature_names[index]
data_num = feature_words.shape[0]
X_df = pd.DataFrame(columns=['tfidf'])
for i in range(data_num):
feature_str = " ".join(feature_words[i, :20].tolist())
X_df_tmp = pd.Series([feature_str], name='tfidf')
X_df = pd.concat([X_df, X_df_tmp])
X_df = X_df.reset_index().drop(['index', 'tfidf'], axis=1).rename(columns={0: 'tfidf'})
dataset = pd.concat([dataset, X_df], axis=1)
ベクトルの作成
文章をレンマ化した結果とtf-idfで取得した結果のそれぞれからベクトルを作成します。
nlp_vec = spacy.load('ja_ginza')
def get_vec(x):
doc_vec = nlp_vec(x)
return doc_vec.vector
dataset['vector'] = dataset['tfidf'].apply(get_vec)
dataset['lemma_vector'] = dataset['lemma'].apply(get_vec)
UMAPで次元圧縮
取得したベクトルは300次元あり、そのままでは比較が難しいのでUMAPで2次元に圧縮します。
dataset['vector'][0].shape
(300,)
import umap
umap = umap.UMAP(n_components=2, random_state=0)
X_reduced_umap = umap.fit_transform(dataset['vector'].to_list())
X_reduced_umap_lemma = umap.fit_transform(dataset['lemma_vector'].to_list())
df = pd.DataFrame(X_reduced_umap, columns=['X', 'Y'])
dataset = pd.concat([dataset, df], axis=1)
df_lemma = pd.DataFrame(X_reduced_umap_lemma, columns=['X_lemma', 'Y_lemma'])
dataset = pd.concat([dataset, df_lemma], axis=1)
plotlyで散布図作成
レンマ化した結果から作成
import plotly.express as px
fig = px.scatter(dataset, x="X_lemma", y="Y_lemma", hover_data=['name'], color='cate17', symbol='cate33')
fig.show()
tf-idfの結果から作成
fig = px.scatter(dataset, x="X", y="Y", hover_data=['name'], color='cate17', symbol='cate33')
fig.show()
出力された散布図の比較
上がレンマ化した結果から作成した散布図で、下がtf-idfの結果から作成した散布図です。
tf-idfの結果の方が17業種区分でうまく分類されているような気もしますが、評価しないと微妙な感じですね。。。
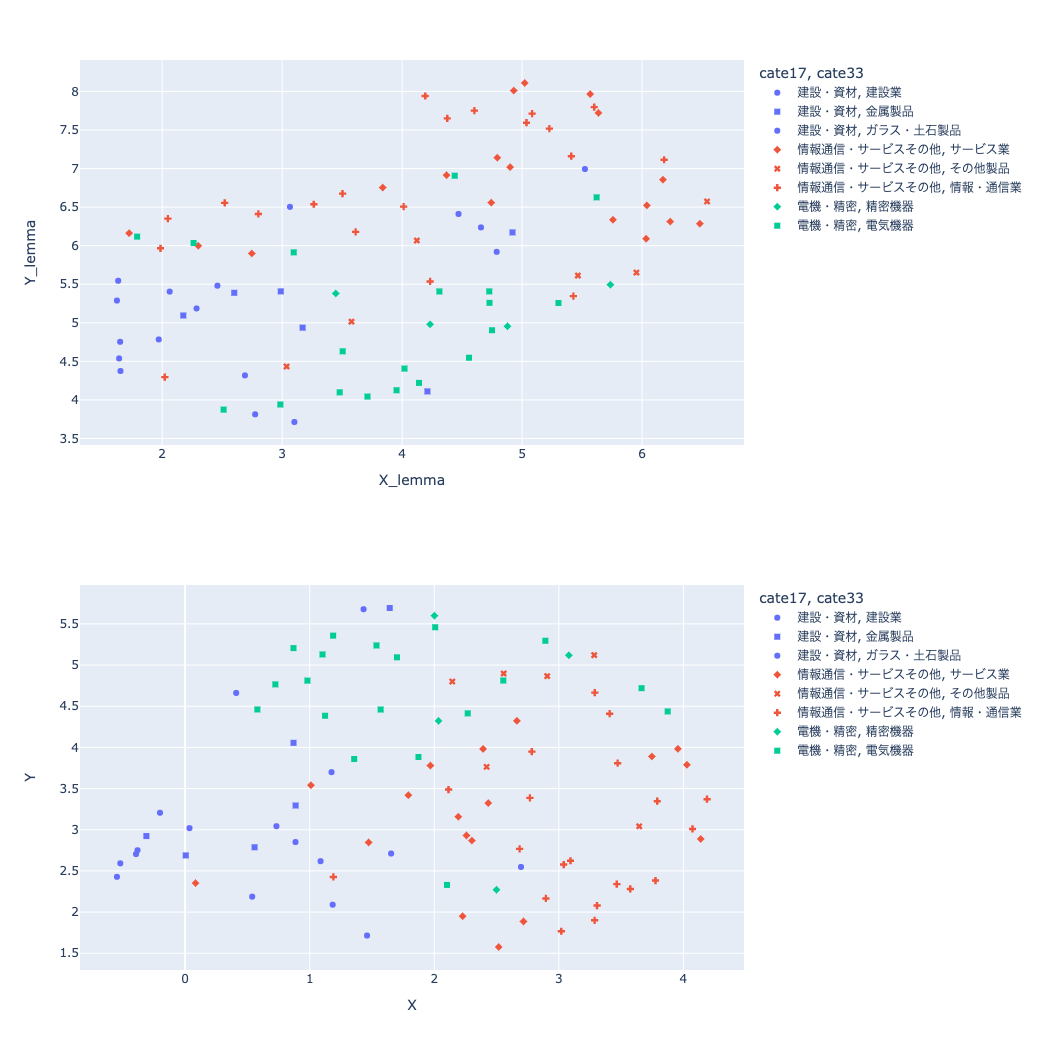
同じ色の中でマークが違うのが33業種区分ですが、こちらは全然うまく分類されてなく難しい。
参考
Discussion