複数の生成AIを使ってプロンプトを最適化してみた
1. はじめに
プロンプトエンジニアリングは、AI活用の成否を左右する重要な要素となっています。しかし、効果的なプロンプトを設計することは容易ではありません。本記事では、ChatGPTとClaudeという二つの大規模言語モデル(LLM)を活用して、プロンプトを自動的に評価・改善するシステムを開発・検証した事例を紹介します。
2. プロンプト評価システムの概要
システムの目的
今回のシステムは以下の目的で開発しました。
- プロンプトの品質を客観的に評価する
- 複数のAIモデルによる多角的な評価を実現する
- 評価結果に基づいて自動的にプロンプトを改善する
- 一定の品質基準(スコア)に達するまで反復的に改善を行う
システムの構成
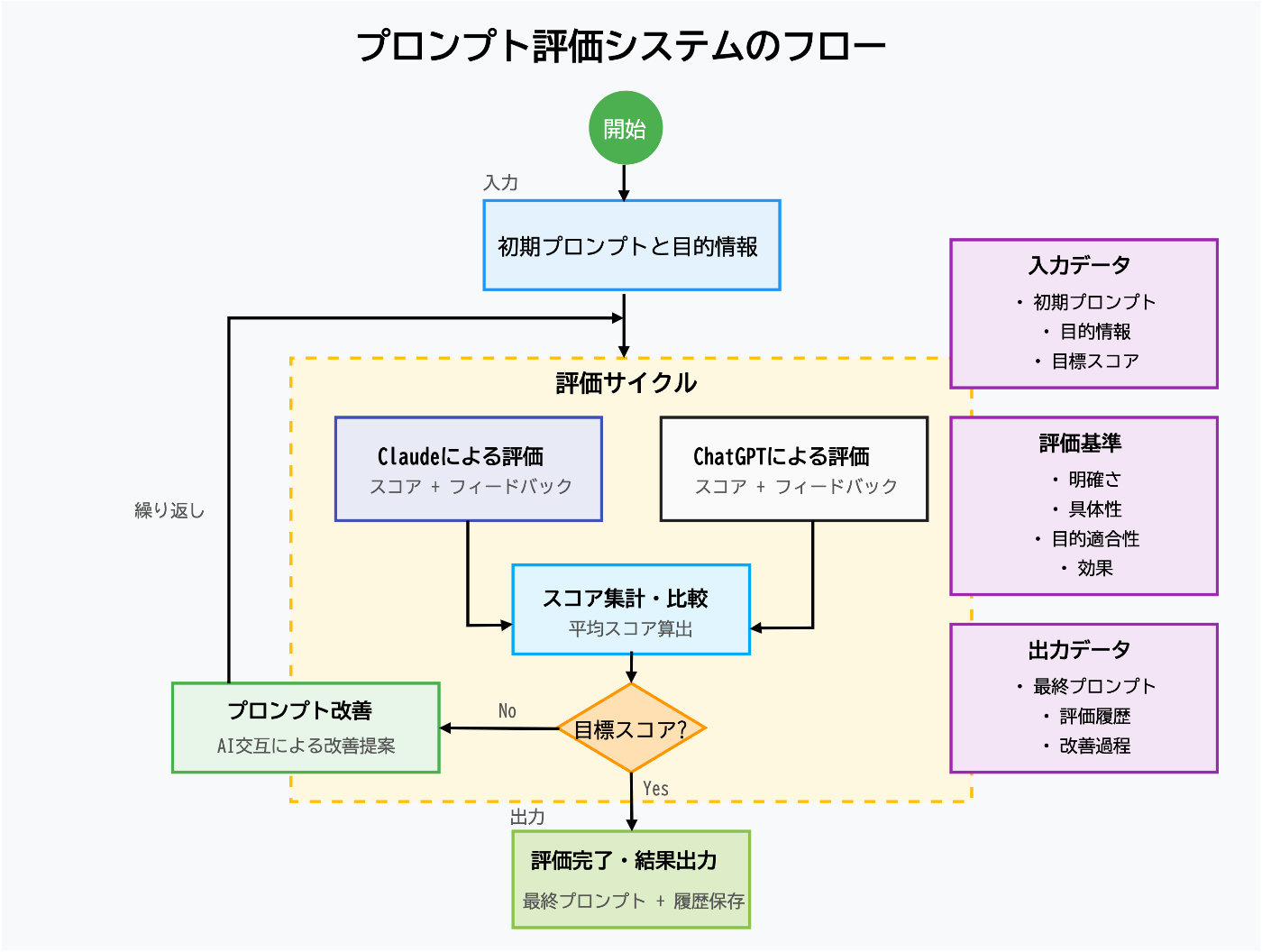
システムは大きく分けて以下のコンポーネントで構成しました。
- 初期入力:初期プロンプト、目的情報、目標スコア
- 評価モジュール:ClaudeとChatGPTによるプロンプト評価
- スコア集計:両AIからの評価スコアの平均値算出
- 改善モジュール:評価結果に基づくプロンプトの自動改善
- 出力:最終プロンプト、評価履歴、改善過程
評価基準
プロンプトは以下の基準に基づいて1〜10のスケールで評価します。
- 明確さ:プロンプトの指示が明確か
- 具体性:必要な詳細が十分に含まれているか
- 目的適合性:意図した目的に沿った内容か
- 効果:期待される結果を生み出す可能性があるか
3. システム実装
実装コード
システムは以下のPythonコードで実装しました(簡略化版)。
class PromptEvaluator:
def __init__(self, target_score=7.0):
self.target_score = target_score
# その他の初期化コード
def evaluate_with_claude(self, prompt, purpose):
# Claudeによる評価実装
def evaluate_with_chatgpt(self, prompt, purpose):
# ChatGPTによる評価実装
def extract_score(self, evaluation):
# 評価テキストからスコアを抽出する実装
def evaluate_prompt(self, prompt, purpose):
# 両モデルでの評価と集計
def iterative_improvement(self, initial_prompt, purpose):
# 目標スコアに達するまで反復的改善
全コード
import os
import time
import anthropic
import openai
from dotenv import load_dotenv
# 環境変数を読み込む
load_dotenv()
# APIクライアントの初期化
openai_client = openai.OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
claude_client = anthropic.Anthropic(api_key=os.getenv("ANTHROPIC_API_KEY"))
class PromptEvaluator:
def __init__(self, target_score=7.0):
self.target_score = target_score
self.current_prompt = ""
self.current_purpose = ""
self.current_score = 0
self.iteration = 0
self.history = []
def evaluate_with_claude(self, prompt, purpose):
"""Claudeを使ってプロンプトを評価する"""
evaluation_prompt = f"""
以下のプロンプトを評価してください。このプロンプトは特定の目的のために作成されています。
プロンプトの明確さ、具体性、目的への適合性、効果の観点から評価してください。
1〜10の評価スコアと簡潔な理由を提供してください。
プロンプトの目的:
{purpose}
評価するプロンプト:
{prompt}
回答は以下の形式でお願いします:
スコア: [1-10] ※分数表記は不要
理由: [あなたの分析]
改善提案: [改善方法]
"""
try:
response = claude_client.messages.create(
model="claude-3-5-sonnet-20240620",
max_tokens=1000,
messages=[{"role": "user", "content": evaluation_prompt}]
)
return response.content[0].text
except Exception as e:
print(f"Claude APIでエラーが発生しました: {e}")
return "エラー: Claudeからの評価を取得できませんでした"
def evaluate_with_chatgpt(self, prompt, purpose):
"""ChatGPTを使ってプロンプトを評価する"""
evaluation_prompt = f"""
以下のプロンプトを評価してください。このプロンプトは特定の目的のために作成されています。
プロンプトの明確さ、具体性、目的への適合性、効果の観点から評価してください。
1〜10の評価スコアと簡潔な理由を提供してください。
プロンプトの目的:
{purpose}
評価するプロンプト:
{prompt}
回答は以下の形式でお願いします:
スコア: [1-10] ※分数表記は不要
理由: [あなたの分析]
改善提案: [改善方法]
"""
try:
response = openai_client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": evaluation_prompt}]
)
return response.choices[0].message.content
except Exception as e:
print(f"OpenAI APIでエラーが発生しました: {e}")
return "エラー: ChatGPTからの評価を取得できませんでした"
def extract_score(self, evaluation):
"""評価テキストから数値スコアを抽出する"""
try:
# "スコア: X"のパターンを探す
if "スコア:" in evaluation:
score_line = [line for line in evaluation.split('\n') if "スコア:" in line][0]
score = float(score_line.split("スコア:")[1].strip().split()[0])
return score
# 英語の評価の場合
elif "Score:" in evaluation:
score_line = [line for line in evaluation.split('\n') if "Score:" in line][0]
score = float(score_line.split("Score:")[1].strip().split()[0])
return score
return 0.0
except Exception as e:
print(f"スコア抽出でエラーが発生しました: {e}")
print(f"評価: {evaluation}")
return 0.0
def evaluate_prompt(self, prompt, purpose):
"""両方のモデルでプロンプトを評価し、平均スコアを計算する"""
self.current_prompt = prompt
self.current_purpose = purpose
self.iteration += 1
print(f"\n--- イテレーション {self.iteration} ---")
print(f"目的: {purpose}")
print(f"評価するプロンプト: {prompt}")
# 評価を取得
claude_eval = self.evaluate_with_claude(prompt, purpose)
print("\nClaudeの評価:")
print(claude_eval)
chatgpt_eval = self.evaluate_with_chatgpt(prompt, purpose)
print("\nChatGPTの評価:")
print(chatgpt_eval)
# スコアを抽出
claude_score = self.extract_score(claude_eval)
chatgpt_score = self.extract_score(chatgpt_eval)
# 平均スコアを計算
avg_score = (claude_score + chatgpt_score) / 2
self.current_score = avg_score
# 評価結果を保存
evaluation_result = {
"iteration": self.iteration,
"prompt": prompt,
"purpose": purpose,
"claude_evaluation": claude_eval,
"chatgpt_evaluation": chatgpt_eval,
"claude_score": claude_score,
"chatgpt_score": chatgpt_score,
"average_score": avg_score
}
self.history.append(evaluation_result)
print(f"\nスコア - Claude: {claude_score}, ChatGPT: {chatgpt_score}")
print(f"平均スコア: {avg_score}")
print(f"目標スコア: {self.target_score}")
return avg_score >= self.target_score
def iterative_improvement(self, initial_prompt, purpose):
"""目標スコアに達するまでプロンプトを繰り返し改善する"""
prompt = initial_prompt
while True:
if self.evaluate_prompt(prompt, purpose):
print(f"\n✅ 目標スコアに達しました!最終スコア: {self.current_score}")
return prompt
# フィードバックに基づいて改善されたプロンプトを生成
improvement_prompt = f"""
以下のフィードバックに基づいて、このプロンプトを改善してください:
プロンプトの目的:
{purpose}
元のプロンプト:
{prompt}
CLAUDEのフィードバック:
{self.history[-1]['claude_evaluation']}
CHATGPTのフィードバック:
{self.history[-1]['chatgpt_evaluation']}
改善されたプロンプトのみを提供し、追加の説明は不要です。
"""
# 改善のためにモデルを交互に使用
if self.iteration % 2 == 0:
improver = "Claude"
response = claude_client.messages.create(
model="claude-3-5-sonnet-20240620",
max_tokens=1000,
messages=[{"role": "user", "content": improvement_prompt}]
)
improved_prompt = response.content[0].text
else:
improver = "ChatGPT"
response = openai_client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": improvement_prompt}]
)
improved_prompt = response.choices[0].message.content
print(f"\n改善されたプロンプト({improver}による):")
print(improved_prompt)
prompt = improved_prompt
time.sleep(1) # レート制限を回避
def save_history_to_file(self, filename="evaluation_history.txt"):
"""評価履歴をファイルに保存する"""
with open(filename, "w", encoding="utf-8") as f:
f.write(f"プロンプト評価履歴\n")
f.write(f"目的: {self.current_purpose}\n")
f.write(f"目標スコア: {self.target_score}\n\n")
for i, result in enumerate(self.history):
f.write(f"=== イテレーション {i+1} ===\n")
f.write(f"プロンプト: {result['prompt']}\n\n")
f.write("Claudeの評価:\n")
f.write(f"{result['claude_evaluation']}\n\n")
f.write("ChatGPTの評価:\n")
f.write(f"{result['chatgpt_evaluation']}\n\n")
f.write(f"Claude スコア: {result['claude_score']}\n")
f.write(f"ChatGPT スコア: {result['chatgpt_score']}\n")
f.write(f"平均スコア: {result['average_score']}\n")
f.write("="*50 + "\n\n")
f.write(f"最終スコア: {self.current_score}\n")
f.write(f"最終プロンプト: {self.current_prompt}\n")
print(f"\n評価履歴が {filename} に保存されました。")
# 使用例
if __name__ == "__main__":
evaluator = PromptEvaluator(target_score=8.0)
initial_prompt = "小説の登場人物を作成してください"
purpose = "小説の執筆において、複雑で魅力的な主人公を作成するためのプロンプト。キャラクターの背景、性格、動機、内的葛藤を含める必要がある。"
final_prompt = evaluator.iterative_improvement(initial_prompt, purpose)
# 評価履歴を保存
evaluator.save_history_to_file()
print("\n--- 評価履歴の概要 ---")
for i, result in enumerate(evaluator.history):
print(f"\nイテレーション {i+1}:")
print(f"プロンプト: {result['prompt']}")
print(f"平均スコア: {result['average_score']}")
システムの特徴
- デュアルAI評価:2つの異なるAIモデルを使用することで、より客観的な評価が可能
- 目的情報の活用:プロンプトの意図された目的を明示し、それに基づいた評価を実施
- 反復的改善:両AIが交互にプロンプトを改善し、各イテレーションで品質が向上
- 評価履歴の追跡:全プロセスを記録することで、プロンプト改善の経緯を分析可能
4. 実装事例:小説キャラクター作成プロンプト
初期状態
目的:小説の執筆において、複雑で魅力的な主人公を作成するためのプロンプト。キャラクターの背景、性格、動機、内的葛藤を含める必要がある。
初期プロンプト:「小説の登場人物を作成してください」
初期評価:
- Claudeスコア:2.0
- ChatGPTスコア:3.0
- 平均スコア:2.5
改善後
改善されたプロンプト:
以下の指示に従い、複雑で魅力的な小説の主人公を作成してください。
1. 基本情報:名前、年齢、性別、外見的特徴
2. 詳細な背景:生い立ち、家族関係、教育、職業、重要な過去の出来事
3. 性格:主要な性格特性(長所と短所)、行動パターン、他者との関わり方
4. 深い動機:キャラクターの根本的な欲求や目標、恐れ
5. 内的葛藤:抱える矛盾や道徳的ジレンマ、解決すべき内面的課題
6. 成長の可能性:物語を通じて変化し得る側面や課題
7. 小説のジャンル:心理サスペンス
8. 舞台設定:現代の都市部
9. 中心テーマ:アイデンティティの探求と過去との和解
光と影の両面を持つ人間らしさを重視し、単なる善人や悪人ではなく、内面の葛藤がドラマを生み出すような主人公像を提示してください。
最終評価:
- Claudeスコア:9.0
- ChatGPTスコア:9.0
- 平均スコア:9.0
改善のポイント分析
- 具体的な構造化:単純な一文から、9つの明確な項目を持つ構造化されたプロンプトへ
- コンテキストの追加:ジャンル、舞台設定、テーマなど、作品の背景情報を追加
- 期待する出力の明確化:「光と影の両面を持つ人間らしさ」という質的指針の提供
- 包括性の向上:キャラクターの外面・内面の両方をカバーする要素の網羅
わずか1回の改善イテレーションで、スコアが2.5から9.0へと大幅に向上しました。この結果は、適切な構造とコンテキストを持つプロンプトが、AIからより質の高い出力を引き出せることを示しています。
5. 今後のプロンプトエンジニアリングへの示唆
1. 構造化の重要性
プロンプトを構造化し、必要な要素を明示的に列挙することで、AIの応答品質が大幅に向上します。特に複雑なタスクでは、出力に含めるべき情報を項目として整理することが効果的です。
2. コンテキストの提供
単に「何を」作るかだけでなく、「なぜ」「どのような環境で」「どのような目的で」といったコンテキスト情報を含めることで、AIはより適切な出力を生成できます。
3. デュアルAI評価の有効性
異なるAIモデルによる複数の視点からの評価は、より客観的で包括的なフィードバックを提供します。各モデルの得意・不得意分野が異なるため、多角的な評価が可能になります。
4. 自動改善プロセスの実用性
AIによる自動プロンプト改善は、人間がプロンプトエンジニアリングを行う際の時間と労力を大幅に削減できます。特に初期プロンプトから出発して段階的に改善する際に効果的です。
6. 今後の展望
このシステムの活用方法は様々考えられます。
- 企業向けプロンプトライブラリの最適化:組織内で共有されるプロンプトの品質向上
- 業界特化型プロンプトの開発:医療、法律、金融など特定分野向けの高品質プロンプト作成
- 教育用途:プロンプトエンジニアリングの教育ツールとしての活用
- APIの評価改善:企業のAI APIに使用されるプロンプトの継続的な評価と改善
7. まとめ
プロンプトエンジニアリングは、AIツールの効果的な活用において重要な役割を果たします。本記事で紹介したプロンプト評価システムは、AIモデル自身を活用してプロンプトの品質を評価・改善するという、メタAI的なアプローチを実現しています。
単純なプロンプトから始めて、わずか1回の改善サイクルで目標スコアを大幅に超える高品質プロンプトを生成できることが実証されました。この技術は、企業や個人がAIツールをより効果的に活用するための重要な支援ツールになるのではないでしょうか。
プロンプトは単なる「AIへの指示」ではなく、「AIとの対話デザイン」です。今回のシステムを活用することで、より効果的なAIとの対話を実現し、革新的なソリューションを生み出す可能性が広がります。
Discussion