入門Raft
はじめに
月刊ラムダノート2025.vol5の三章にてRaftアルゴリズムが取り上げられていました。
Raftはおろか、分散合意や分散DB、分散システムについて全く知識がない状態だったので、上述のラムダノートを読んだ機会に自分なりにまとめてみました。
分散合意アルゴリズムとその進化
分散合意アルゴリズムとは
分散システムを作っていく上で考慮点となるのが、一貫性と可用性、分断耐性のバランスでしょう。俗にいうCAP定理というやつです。CAP定理についてはその定義と解釈の誤りなどネット上に大量の情報があるのでここでは割愛します。
分散システムで一貫性(C)を保証する際のアプローチとして、複数のノードが一つの値に合意する分散アルゴリズムというものがあります。
2PC、Paxos、Raft
分散合意アルゴリズム自体は古くから考えられており、数多のアルゴリズムが存在します。
代表的なものは2PC(2相コミットメント)でしょう。古来からある分散合意の仕組みで、調停者となるノードがその他のノードにコミット指示を伝搬させていく方法です。ph1で更新可否を問い合わせ、ph2で状態確定(Commit)を指示をします。
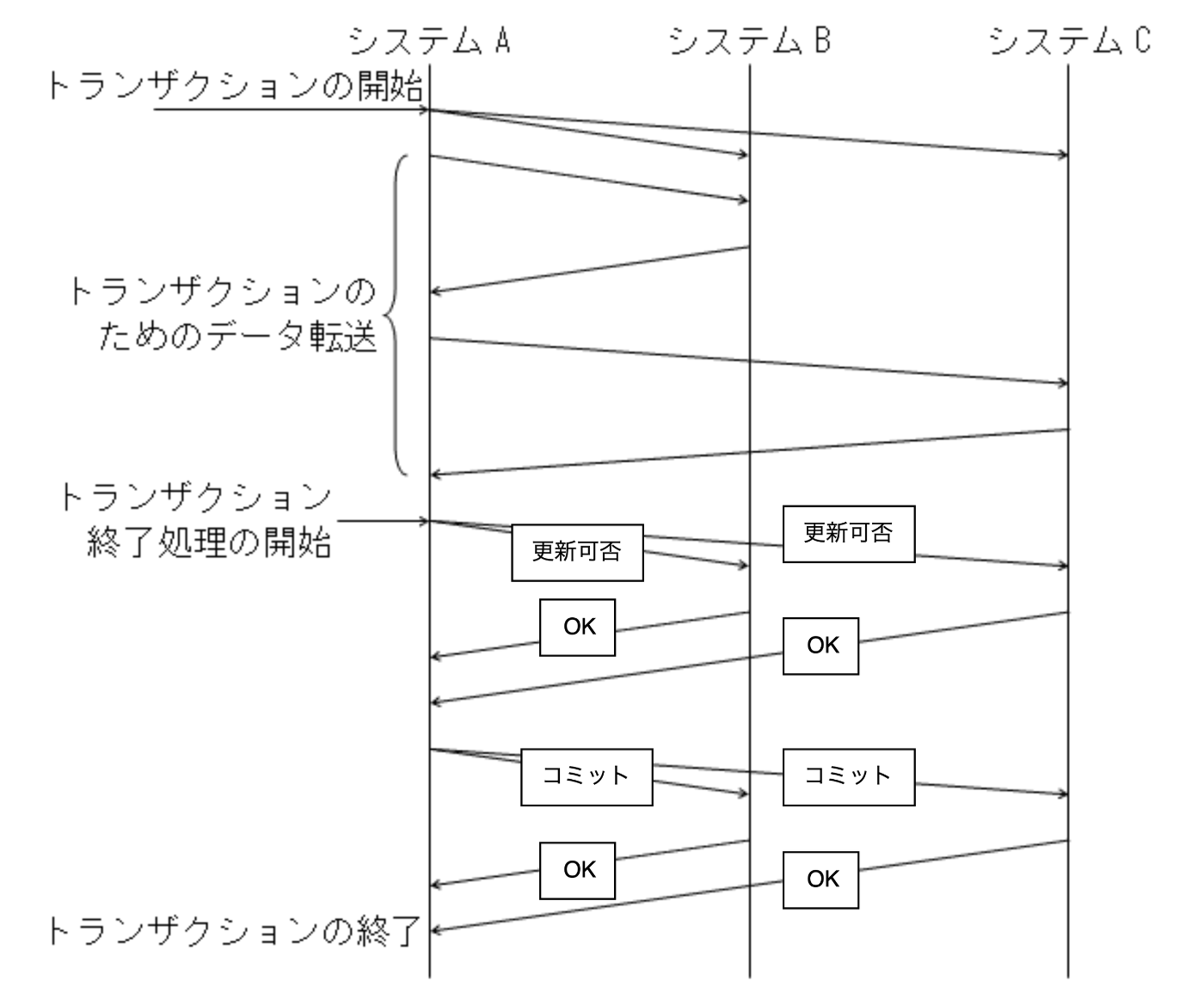 2相コミットの流れ(H26 データベーススペシャリストから引用)
2相コミットの流れ(H26 データベーススペシャリストから引用)
わかりやすいアルゴリズムなのですが、調停者が単一障害点となるなど改良版も含め故障耐性に欠点がありました。
安全性に問題のあった2PCを改良すべく生み出された合意アルゴリズムがPaxosで、単一のリーダーノードによる独裁的な決定ではなく、分散された複数のノードによる「合意」によって進めるアルゴリズムです。2PCに比べ安全性が高いものの理論と実装が複雑で難解であるという欠点がありました。
そこで2014年、Paxosと同等の性能をもちつつ、いくつかの制約を設ける代わりに理解を容易にしたアルゴリズムとしてRaftが登場しました。
Raft詳細
Raftアルゴリズムは”クラスターが合意した情報を各ノードがローカルでログとして保持し、その情報を使ってステートマシンとして動作するノードを冗長化(複製)する”という発想に基づいています。
Raftの特徴としては強い整合性が挙げられます。複数のクライアントから同時にリクエストが来た場合でも一貫性を保って順番に処理されます。また前述の通り理解、実装がしやすいということも特徴の一つです。
Raftアルゴリズムの流れ
基本の構成として、クラスター内のノードは一つのリーダーとリーダー以外のフォロワーに分かれます。また、後述のリーダー選出フェーズのみ候補者ノードという役割が発生します。
リーダーのノードが全ての長となり、クライアントからのリクエストを引き受け、フォロワーに取り次いでいきます。
リーダーが一つと言いましたが、初めは全てフォロワーの状態からスタートします。
Raftの流れとしては大まかに
- リーダー選出
- ログ複製
- メンバー変更
の三つがあります。順に説明します。
リーダー選出
全てがフォロワーの状態からノード間での選挙を行Rいリーダーを選出します。
各フォロワーノードにはある一定時間リーダーからメッセージを受信しなかったら候補者に名乗り出る値(エレクションタイムアウト)が設定されています。エレクションタイムアウトを超過し候補者となったノードは、自分の中で持っているタームという変数をインクリメントしたのち、そのタームとローカルログの最後のローカルログのインデックスとターム(後述)を含め、他のノードに対して投票を依頼するメッセージ(RequestVoteRPC)を送信します。
RequestVoteRPCのタームと自分のタームを比較し、前者の方が新しい場合には送信元の候補者に投票します。
 候補者の情報が新そうな場合に投票
候補者の情報が新そうな場合に投票
一方、同じタームですでに他の候補者に投票済みであった場合や、現行のリーダーが存在していると判断した場合にはRequestVoteRPCに応答しません。
候補者ノードは自分を含めた過半数のノードから投票を得られた時点でリーダーに移行します。
ログ複製
リーダーとなったノードはクライアントからのリクエストを受け付けます。リクエストを受け取った時に新しいエントリとしてコマンドをローカルログに追加します。その情報をAppendEntriesRPCというメッセージで全フォロワーにブロードキャストします。フォロワーは受信した情報を自分のローカルログに追記し、成功した場合はリーダーに応答します。
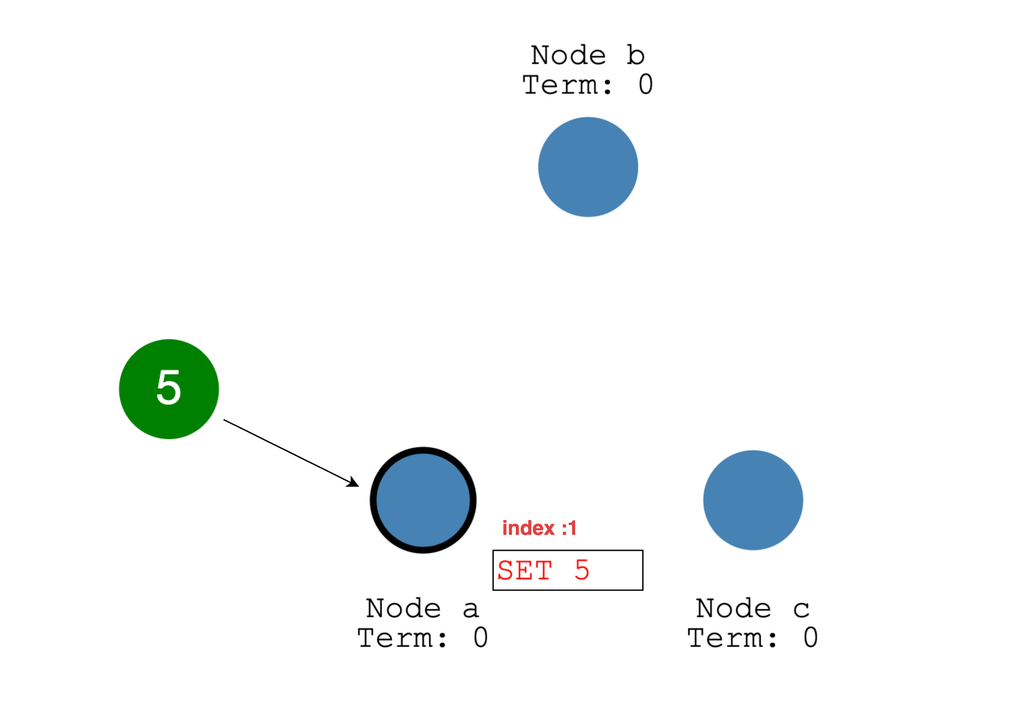 リーダーがローカルのログエントリに書き込み
リーダーがローカルのログエントリに書き込み
 フォロワーに対してAppendEntriesRPCを送信
フォロワーに対してAppendEntriesRPCを送信
リーダーは自分も含め過半数のノードでログの追記が完了した場合に、そのエントリを「クラスターに安全に保存された」(コミットされた)とみなします。
コミットされた操作はステートマシーンに適用できます。AppendEntriesRPCにリーダーがコミットした最新のエントリのインデックスが情報としてあるので、フォロワーはそれを参照しステートマシーンに適用していきます。
フォロワーがコミットするタイミングとリーダーがコミットするタイミングでずれがあるということですね。
異常系その1 〜フォロワーの出遅れ(同期遅延)
一部のノードが一時的にネットワークが分断されていたなどで、同期が遅延しているケースを考えます。フォロワーはAppendEntriesRPCに含まれている最新のprev_log_indexとprev_log_termが自分のログ内に存在しない場合に拒否応答をします。
拒否応答をうけとったリーダーは拒否したノードに対して、一つ前のログエントリの内容でAppendEntriesRPCを送信します。それでもNGだった場合はまた一つ前のログエントリでAppendEntriesRPCを送信、というように順に遡ることで同期ができていない地点を把握します。
把握できたらあとはそのログからまた順々にAppendEntriesRPCを送信していき、最終的にステートを同期させます。
異常系その2 〜リーダーの故障
エントリーを複製後、コミットするまでの間にリーダーがクラッシュしてしまった場合はどうでしょうか。次のようなケースを考えてみます。
S1がリーダーの状態からスタートし、2つ目のリクエストをフォロワーに送信中にクラッシュした状況を考えます。この時S2にのみリクエストが到達しており、ログエントリに書き込まれているとします。
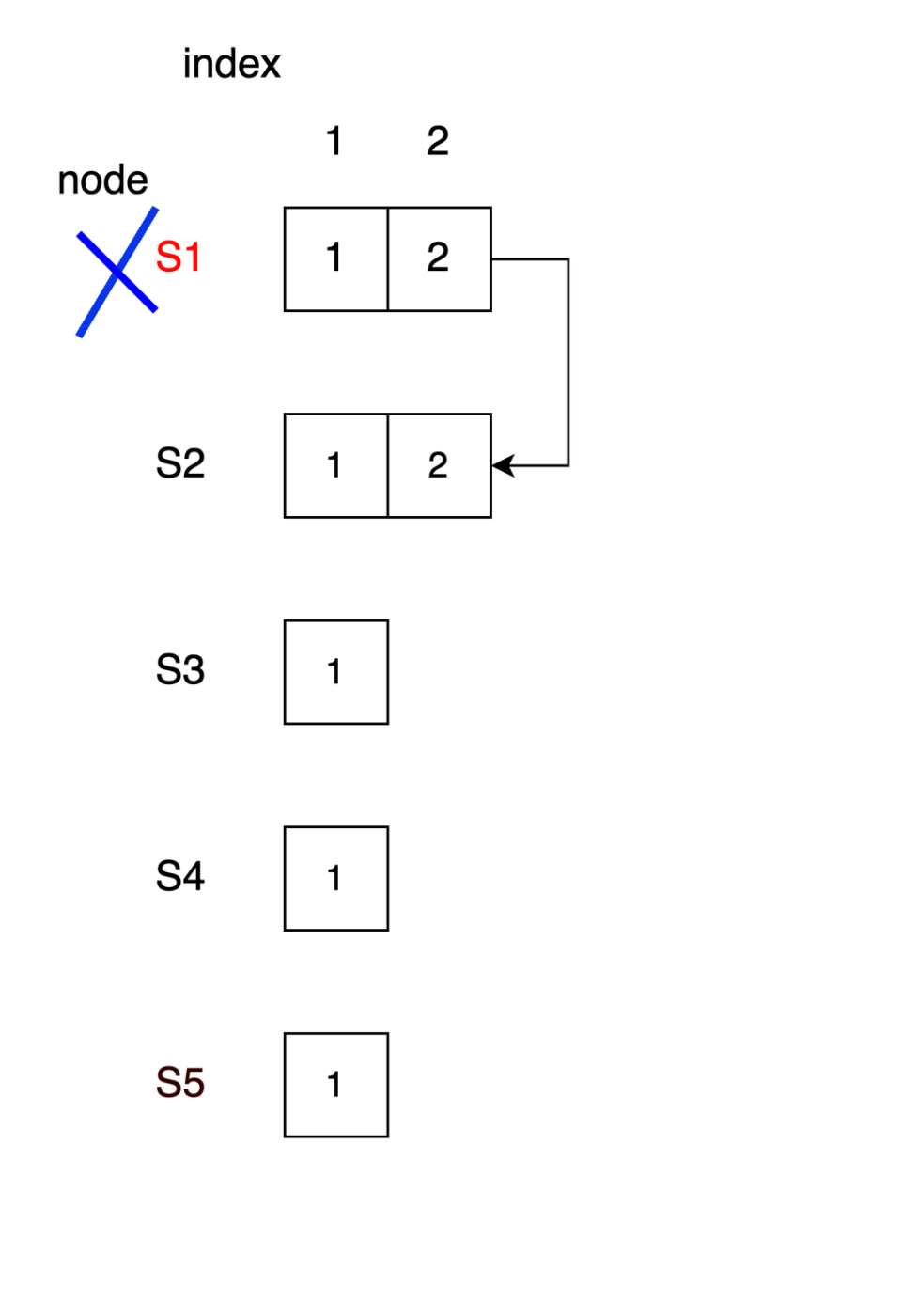 S1がターム2のリーダーで、index2のリクエストを待ち中にクラッシュ
S1がターム2のリーダーで、index2のリクエストを待ち中にクラッシュ
S1がクラッシュ後、S5が新たにリーダーとなりリクエストを受け付けたとします。S5にリクエストが来てローカルに書き込んだのですが、フォロワーにメッセージ送信する前にS5がクラッシュしてしまった場合、この時点ではS1~S5はすべてindex1しかコミットされていません。
 S5がターム3のリーダーで、index2のログを書き込み直後にクラッシュ
S5がターム3のリーダーで、index2のログを書き込み直後にクラッシュ
再度S1が当選しリーダーとなりました。S1は同期が取れていないindex2の情報をフォロワーに送信していきます。S3のノードから応答があった場合、index2はS1ノードでコミット可能となるのですが、ここでコミットしてよいのでしょうか?
 再度S1がリーダーとなり、S3にindex2のリクエストを送信
再度S1がリーダーとなり、S3にindex2のリクエストを送信
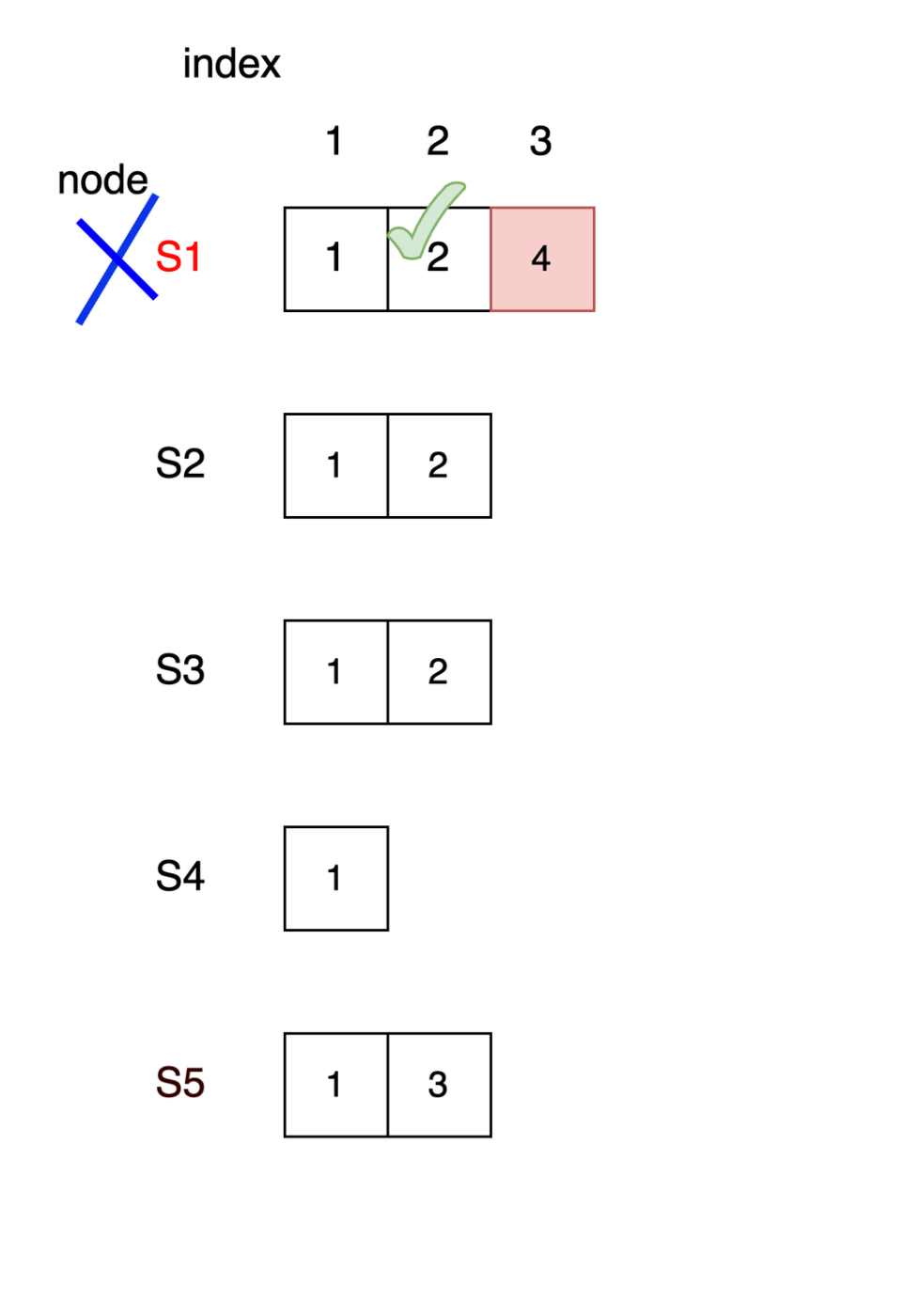 index2が過半数の賛同を得られたためindex2はコミット可能
index2が過半数の賛同を得られたためindex2はコミット可能
仮にコミットした場合に、その直後にS1が再度クラッシュしたとします。
この時点でS1はindex1、(term2の)index2が、S2~S5はindex1がコミットされています。
さて、S1クラッシュ後、またまたS5がリーダーとなったとします。S5はterm3でひとりログエントリーを抱えていましたから、そのエントリーをS1以外のノードに送信します。無事成功するとS2~S5のノードはindex1,(term3の)index2がコミットされていることになります。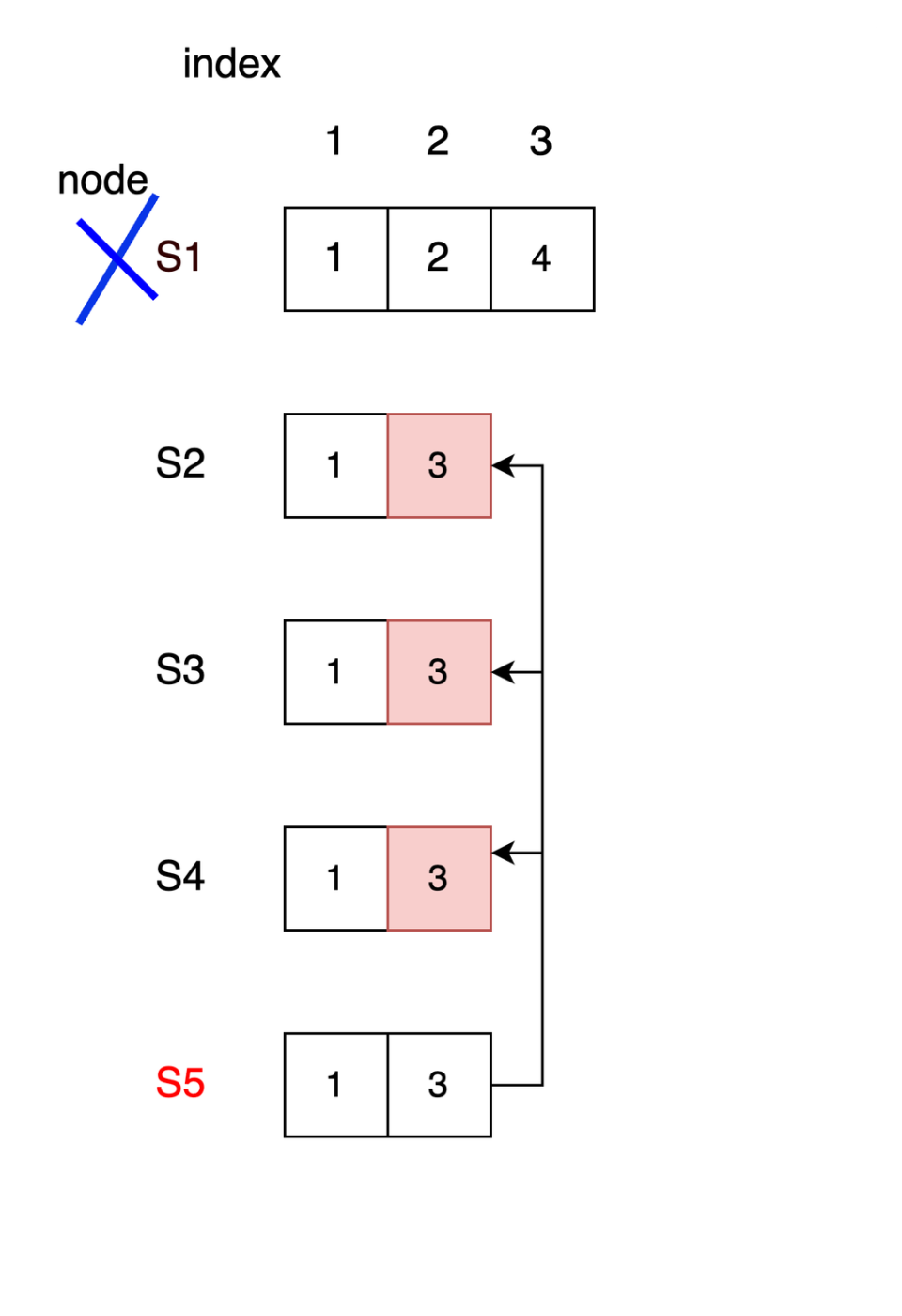 S1がindex2をコミット後クラッシュ
S1がindex2をコミット後クラッシュ
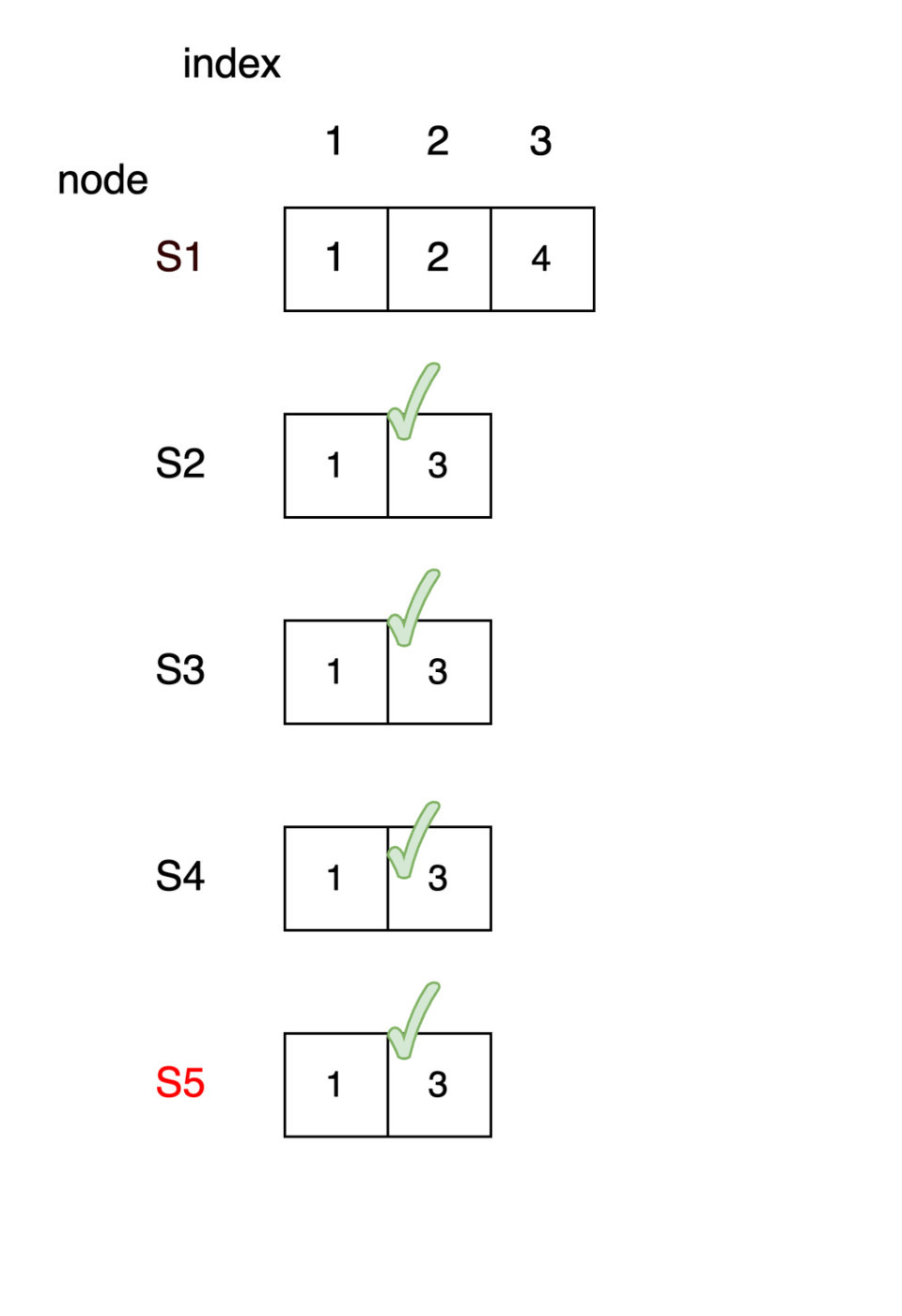 S1が復活後、S1は1,2がコミット、S2-5は1,3がコミットされている状態となり不整合が起きる
S1が復活後、S1は1,2がコミット、S2-5は1,3がコミットされている状態となり不整合が起きる
このままS1が復帰すると、S1とそれ以外のノードでログエントリの状態が不一致となってしまいます。
このような事態を避けるため、Raftでは現在のタームでコミット可能なエントリを作成した後にコミットしていく、というルールを設けています。
つまり、”タームの最初はエントリの複製からスタートする”という決まりです。
今回の場合であれば、ターム4で2をコミットする前に、ターム4で生成されたログエントリの複製をまずはじめに実施します。
このようにすることで、またしてもターム2のデータをコミットする前にS1がクラッシュしても次のタームのリーダーはターム4のデータを保持しているS2,S3のいずれかということになり、S5がリーダーとなるのを防ぐことができます。
ややこしいですね…
メンバー変更
ノードが何らかの理由で増減した場合の挙動について考えます。
メンバーの構成が変わった際にリーダーと認識されているノードが二つ以上存在するという事態は避けなければなりません。Raftでは移行を2フェーズに分けることで対策をしています。
-
ph1: 新旧混合構成
リーダーが構成変更リクエストを受け付けると、C_old、C_newの両方のノード一覧を含んだログエントリを新旧全てのノードに送信します。そのリクエストがC_old、C_newそれぞれの過半数から賛同された場合に構成変更リクエストがコミットされ、新旧混合構成に移行します。この状態のことを連結コンセンサスといいます。 -
ph2: 新環境への移行
連結コンセンサスへの移行が完了後、今度はC_newへの移行を知らせるエントリを送信します。具体的には新構成のノードの一覧を載せたエントリを送ります。コミットを待たずに自らのログに追記した時点から新構成のノードの過半数だけを使って判断ができるようになります。
もしリーダーが新構成に含まれない場合は、新構成移管のログをコミット後に自らフォロワーに降格し、新環境でまた選挙が行われます。
メンバー変更でもエッジケースがあり、クラスター外で無限に選挙→タイムアウトが繰り返すノードが発生しうるなど、いくつか未解決な問題があるようです。
ただ運用でカバーできる範囲であるためそこまで心配することはないみたいです。(要出典)
おまけ:Raftといえば分散DB
Raftアルゴリズムは多くのCockroachDBやTiDB、MongoDBなど分散DB(not only NewSQL)で利用されています。今回はTiDBを例にとり、Raftの使われ方を見ていきます。
TiDBではそのストレージエンジン製品であるTiKVのレプリケーションでRaftを使っています。
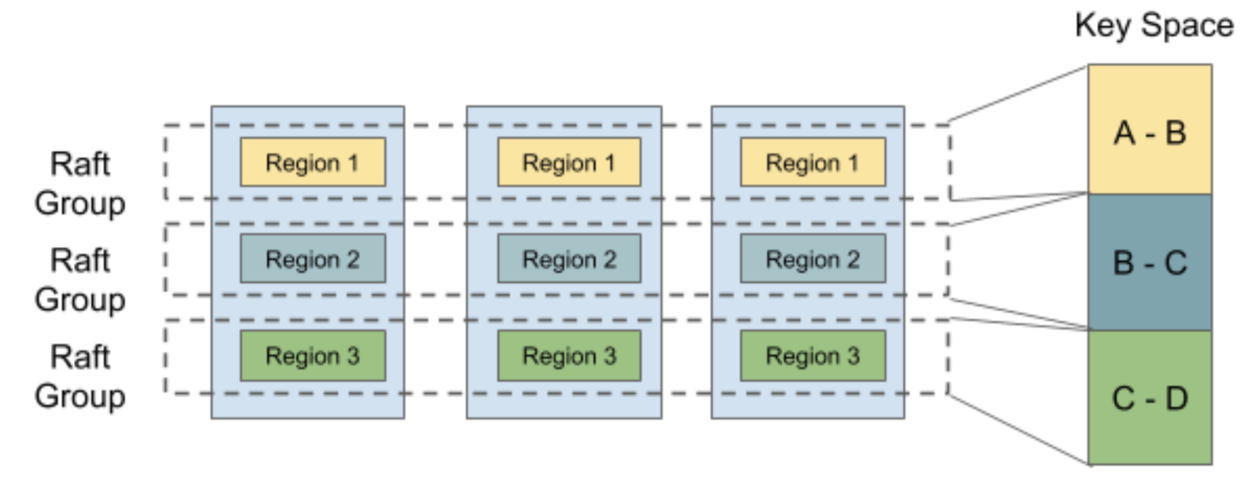
しかしこれまで見た通り、RaftそのものをDBに適用するだけでは書き込みも読み込みもリーダーに集中してしまい、分散しているとはいえなさそうです。TiDBではMulti Raftという手法を用い”分散”させているようです。
データはいくつかの単位で分割、つまりシャーディングされ、そのシャードの単位をリージョンと言います。また、リージョンごとのデータをレプリケーションしていき、そのクラスタをまとめてRaft Groupと言います。
このようにシャードに分けてRaftでレプリケーションするかたまりを複数作成することをMulti RaftとTiDBではよんでいます。Multi Raftとすることで書き込みはシャーディングでリーダー達の負荷を分散しつつ、一貫性を担保することができています。
ちなみに書き込みの負荷をもっと下げ、フォロワー達に負荷を分散させるべくFollow Readという方法があります。クライアントからの読み込みリクエストをフォロワーに直接送り、フォロワーは最新のログのインデックスをリーダーに問い合わせます。問い合わせた結果自分のローカルログと一致していたらそれを応答し、一致していなければ同期を待ち同期後に応答します。
(結局フォロワーから問い合わせがあるのならリーダーの負荷はあるのではという疑問が…)
まとめ
分散合意アルゴリズムと、その代表例であるRaftの仕組みを解説してみました。
細かい議論は端折っているので元論文を適宜参照してみてください。また、今回の記事は冒頭で記載の月刊ラムダノートの記事に触発されています。気になる方はこちらもぜひ読んでみてください。
参考
月刊ラムダノート 2025.vol5
Discussion