この記事は Datadog Advent Calendar 2025 の 18 日目の記事です。
ジンズというアイウェアの会社で、エンジニアとしてパブリッククラウドとかオブザーバビリティとかコンテンツデリバリーネットワークとかと戯れています。(あえて全部カタカナで)
プラットフォームという言葉が入ったグループの所属にはなったのですが、やっている業務内容的に個人的にはまだ自身をプラットフォームエンジニアというのはなんとなく憚られています。
はじめに
ジンズでは約2年半ほど前に監視基盤をDatadogにお引越ししました。
最初は既存監視の移植から始まったのですが、新規システムの監視や既存システムの監視の改善なども行っています。
元々移植してきた既存の監視はインフラのメトリクス閾値監視がほとんどだったので、Anomaly Monitorで異常検知できるようにしたり、Synthetic Monitoringでサービス監視したりなど監視のモダナイズ的なことも進めています。
このようにDatadog Monitorを活用し数も増えていくと、その品質が課題になってきたりしていて、それに対処している(現在進行形の)話になります。
アラート疲れとオオカミ少年アラート
「あ、くそっ、問題発生だ」といったことが週に10回、1ヶ月間続いたら、長期間のアラート疲れを起こして、メンバーは燃え尽きてしまうでしょう。メンバーのレスポンス時間は遅くなり、アラートは無視されがちになり、睡眠時間に影響が出ます。
みんな大好き「入門 監視」からの一節です。 これとほぼ同じような事象が弊社でも起こっていました。
- 夜間にアラートが鳴るが、重大なエラーかそこまで優先度高くないエラーかが区別できていなく都度疲れてしまう
- いつも鳴っているアラートだから(=オオカミ少年アラート)と発報があっても無視してしまう
- そもそもアラート発報されていること、チケット切られていることも認識していない
オオカミ少年アラートの特定
どうやって上記のようなアラートを特定し、改善点を調査したかの記録です。
履歴のエクスポート
Datadogではモニターアラートの履歴をダウンロードできるAPIが提供されています。
まずはここで出力したcsvベースで頻発しているアラートの特定を行いました。
(せっかくなら出力結果の分析プロセスをDatadog Sheetsあたりで実施しておけば、もう1ネタくらい書けたかも?)
ダッシュボードの作成
エクスポートしたcsvベースで分析している途中で存在に気づき、以後はこれをベースに特定を進めているのですが、DatadogではプリセットでMonitor Notifications Overviewというダッシュボードが用意されています。
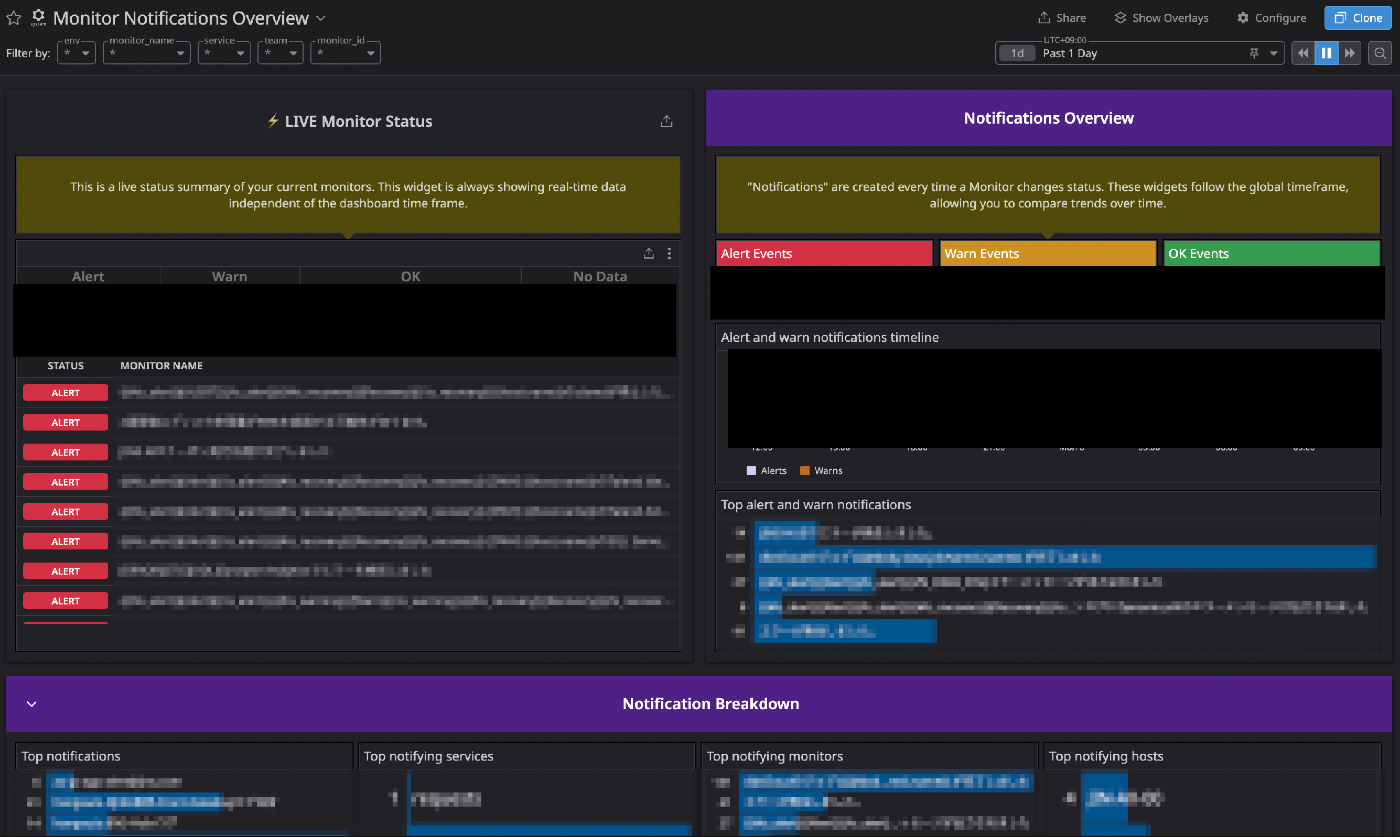
Monitor Notifications Overview
これを見れば、「その日に最も発報されていたアラート」「最も発報されていた通知先」「最も発報されていたホスト」など分析に必要な情報がサクッと出てきます。
私はこのプリセットのダッシュボードをクローンして、いくつかカスタマイズして活用しています。
プリセットのダッシュボードがすでにかなり完成度が高かったため、カスタマイズは以下のような最小限に留めています。
- INFOレベルとして使っているP5重要度のアラートは除外(後述)
- 使い勝手いいようにウィジェットの並べ替え
対応状況の調査
ここは地道にアラートの通知先、アラートの発報先に対してアラートの対応状況をヒアリングしました。
主に以下の観点です。
- 発報全てに対応しており、正直アラート疲れを感じるものか
- 発報は気づいているが無視しているか
- そもそも発報を認識してすらないか
ジンズでは、Monitorから発報されたアラートは「Google Chat」「Backlog」「Datadog On-Call」に通知されるものが大半なので、ヒアリングした結果も踏まえ
- Chatに通知されているが、何もコメントがついていないもの
- Backlogにチケット起票されているが、コメントもついてなくクローズもされていないもの
をターゲットに実際の対応状況、アラートの有無の確認、アラート条件の精査を進めました。
Datadog On-Callに関してはみなさんAcknowledgeはして対応の履歴は残してくれているので素敵。
(ちゃんとResolveまでしてもらえるようもう少し布教しないとと、On-Callのページを見て再認識はしました)
ヒアリングの際には私もなるべく「内なるAI」(同僚が書いている記事です)を意識しながら私も進めていました。
生成AI活用と内なるAI活用
当たり前ですが、「めっちゃ発報しているからこれ確認して〜」ではなく、「AAシステムのBB機能に関するアラートがとても鳴ってそうで、たぶんCCってエラーが異常に出力されてそうなんだけどこれって想定されている状況なんだっけ?」あたりまで整理して持っていくようには意識しました。
上記のようにアラートやエラー内容を「ちゃんと」調査するにあたって、以下あたりが悩ましいポイントでした。
- そもそもどのチームが管理すべきアラートなのかわからない
- 大量に発報されているけれど、そのアラートの緊急度がわからないから対応の優先度/温度感がわからない
両方とも、多くのアラートのDatadogへの移行は2年半前に私自身が実施し、それ以後も多くのアラートを私が作ってきたので大体は把握していたのですが、私以外がこれを実施しようとしたら結構きつそうだなと課題に感じ、この課題への対応も本案件の中で実施しました。
改善の実施
アラート条件、通知先の整理
ここはヒアリングの結果に基づいて、
- 不要なアラートの削除
- 発報条件の見直し
- 通知先の変更
などを粛々と実施しました。
発報条件の見直しは、Datadog側のアラートのクエリを改修することで改善するような事象が多かったですが、一部アプリケーション側のエラーハンドリングがおかしくなっているものも見つかり、アプリケーション側の改修に至るようなケースもありました。
チームの定義
どのチームが管理すべきかの情報の可視化のため、MonitorにTeamを定義しました。
以下のようにMetadataとして事前に作成済みのTeamを定義することができ、例えばこのMonitorであればデータ基盤チームのアラートと分かります。

Teamの設定
これでDatadogを管理している側もどのチームのMonitorなのか一目瞭然ですし、各チームも自身の管理しているMonitorを識別しやすくなります。
また、上記Monitorを管理しているデータ基盤チームは、自分たちでMonitorも仕掛けそれらのチューニング含めちゃんと管理してくれているのですが、チームによって技術的なレベル感やDatadogの習熟度も異なるので、底上げのためにスキトラを実施したりガイドラインを作成したりといったことも、少しずつ実施しています。
重要度の定義
上の方でINFOレベルは重要度P5を使っていると書きましたが、INFOレベル以外も重要度の定義を実施しました。
重要度P1は顧客影響が大きい(例えば納期遅延に繋がるエラー等)すぐにでも対応しないといけないエラーとしています。
また、このエラーのみDatadog On-Callを通知先としておき、「Datadogから電話がかかってきたらヤバめのエラーだから即対応しないと」というような状況にしています。
Datadog On-Callの導入で夜中でも叩き起こされるような状況になったのですが、顧客影響の大きいエラーだと電話がかかってくるから、電話がなければ安心して寝ていられるとのことで結構好評だったりしています。
P2 ~ P4については上のアラートのように設定しているものもあるのですが、まだ明確に定義しきれておらず、現在ちゃんと言語化してガイドライン化し始めているところです。
通知本文の見直し
合わせて、このタイミングで通知本文の記載内容の見直しも実施しました。
多くのアラートのメッセージは
検知日時: {{local_time 'last_triggered_at' 'Asia/Tokyo'}}
ホスト名: {{log.tags.name}}
メッセージ: XXでエラーが発生しました。エラーをご確認ください。
のようなものがほとんどで、これだとエラーが発生したことはわかるが、「で、どう対処すればいいんだっけ」がこれだけでは全くわからないです。
ここでもみんな大好き「入門 監視」です。
手順書(runbook)は、アラートが来た時にすばやく自分が進むべき方向を示すため素晴らしい方法です。環境が複雑になってくると、チームの誰もが各システムのことを知っているいる訳ではなくなり、手順書が知識を広める良い方法になります。
・・・
各アラートには、対象サービスの手順書へのリンクを入れましょう。誰かがアラートに応答した時、手順書を開くことで、何が起こっているか、アラートがどんな意味か、また修復の手順などを理解できるでしょう。
最終的には各アラートのRunbookがリポジトリ管理されててそこのリンクがアラートに貼られているが個人的に目指したいところではあるのですが、まずはファーストステップとしてアラートのメッセージ内に「発生している事象」「そのシステム面/ビジネス面での影響」「どのようにすれば復旧できるか」を記載することを実施し始めました。
環境が複雑化し、人員の増加やシステム担当者の変更により、アラートを受けるメンバーのシステム理解度(ひいてはアラート対応の品質)にばらつきが生じています。
そのため、このようなアラートを受けたらその対応も記載されている状況を作り、対応品質の底上げを図りたいと考えています。
まとめ
タイトルに改善「している」話と書きましたが、この対応はまだまだ現在進行形です。
調査時点でアラート疲れやオオカミ少年アラートになっていたMonitorについては大方「改善の実施」で書いた対応は実施しましたが、全てのMonitorに上記対応を実施できているわけではないです。
Monitor自体日々作成されたり不要なものは削除され、すなわち新たな「オオカミ少年アラート」や「アラート疲れ」も発生していくので、この活動自体が「ショット」ではなく継続して取り組んでいく(=私のミッションが変わらない限りライフワーク化)活動の気持ちでいます。
最終的には、私(=管理している側)がこういう活動を実施しなくとも、利用者側が自発的にor意識しなくともこういった営みを実施できる仕組みや環境を作ることが一番だとは思うので、そういった環境やガイドラインの整備も進めていきたいです。(そういった機能のリリースもDatadogさんに期待しつつ)
また、今回話したアラートへの対応品質の話はJDDUGのイベントで色んな方に相談させていただいて、他社でどう改善しているか聞いたりしたこともかなり参考になりました。
私自身JDDUGもそうですし他であればJAWSもそうだったのですが、オンラインでなく物理での参加は最初はなかなかの不安があったものですが、実際に物理参加してみるとみなさん暖かく迎え入れてくださって素敵なコミュニティなので興味ある人はぜひ参加してみてください(最後に宣伝)
参考にしたもの

Discussion