JINSで、アーキテクト/テックリードをしている佐藤(@Takuma3ato)です。
JINSでは、様々なインターフェース方式でデータ連携をしています。私のパートではしばらく、それらのパターンについてご紹介していこうと思います。その第一弾として今回は、システム間連携においては必須と言えるファイルデータのやりとりについてお話しします。
1.ファイル連携(ファイルの配置、ファイルの取得)
新しくデータ連携を検討するときにまずは最初に考えることになる方式です。

連携するデータ量
「少量から多く」まで幅広く対応できて設計は容易。しかし、1ファイルサイズの限界はあるのと、大きすぎるファイルでは、処理に展開に時間がかかるので限度は考えたい。
連携先システムへの反映速度
対向システム(データを送信する相手先のシステム)側のデータ取り込みのタイミングによるので、データ送信元のシステムではコントロールできない。
連携時のエラー処理
ファイルを特定のフォルダや所定の場所に置くだけの為、エラーハンドリングはし易い。しかし、対向システム側では「ファイルが置かれていない」ことについて、それが送り元システムのエラーによるものかの判別がつかない為、あるべきファイルが配置されていない場合の取り決めは必要。
他システムとの依存度合い
単なるファイル連携のため(ファイルを置く、置かれているファイルを取得する)、システム同士の依存性は低く保つことができる。
通信で使うネットワーク
ファイルを置く場所がネットワークのどこに存在しているのかに依るが、インターネット通信、社内ネットワーク通信どちらも可能。
2.JINSでのファイル連携
(1)環境
・Amazon S3を用いることが基本
・システム to システムのファイル連携で使用
・特定のシステムのみで利用するデータの保管にもAmazon S3を使うが、連携用とは別のバケットを使用する
・パブリック接続を許容するデータ(例:商品画像)は、別のAmazon S3バケットを使用する
(2)以前のファイル連携のやり方
概要

実際のPath構成
bucket/
├── SystemA/
│ └── yy/
│ └── mm/
│ └── dd/
│ └── file.csv
└── Data1/ #データそのものにフォーカスされたPathもあったりする
└── yy/
└── mm/
└── dd/
└── file.csv
なぜそのやり方だったか
基幹システムからデータエクスポートされるファイルをターゲットシステム側で利用することが、この連携方式の発端であったために、「いかに、基幹システム側の改修を少なく済ませるか」が主な考えであり、データソース側システムの権力が強い設計思想となっています。
よかったこと、課題
この方式で良かったこととしては、既出の通り基幹システム側での複雑な改修をしないで済ませられることでした。エクスポートされたファイルをどのように使うかは、利用システム側の自由としていました。
一方で課題としては、不特定のシステムでこのファイルを利用して良いために(もちろん、認証認可処理はあります)、データソース側システムで改修をかけようとした場合に、どのくらいのターゲットシステムがあって、そのデータをどのように利用しているのかを把握しきれず影響範囲が見えないことでした。
(3)今のファイル連携のやり方
概要
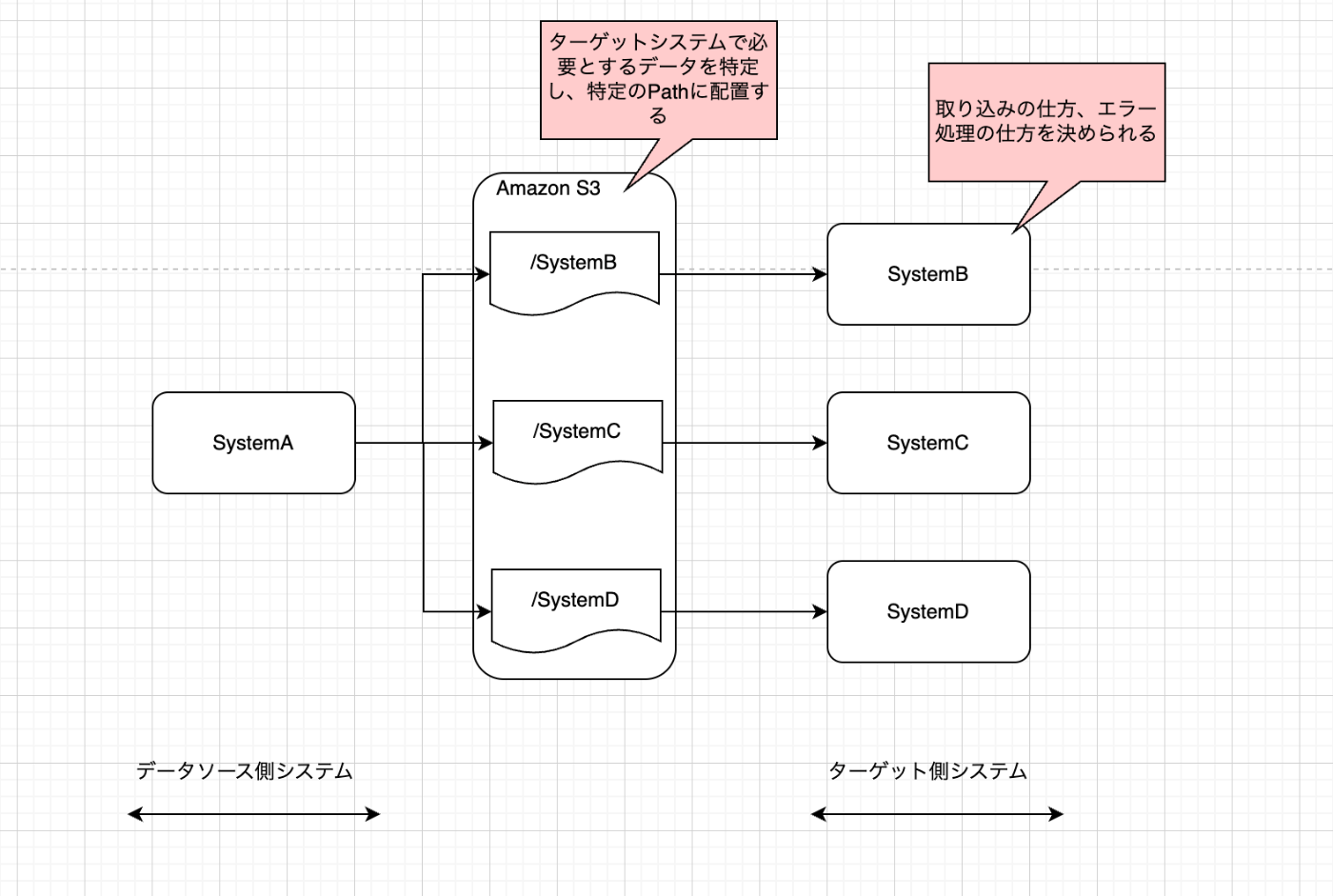
実際のPath構成
bucket/
└── tag/ #このpathは非必須
└── ターゲットシステム名/
└── ソースシステム名/
├── queued/ #ソースシステムがputする
│ └── file.csv
├── processed/ #正常処理後、ターゲットシステムがqueuedからmoveする
└── quarantined/ #取り込みエラー発生後、ターゲットシステムがqueuedからmoveする
なぜそのアーキか
端的に言えば、以前のファイル連携のやり方で出た課題を解決するためです。
データソース側システムが基幹システムだけはなく、様々なシステムが担うようになったことで、ターゲットシステム側の負荷を下げる形にシフトしました。データソース側が自分たちのデータはどの対向システムで利用されるのかをきちんと把握することで、自分たちがオーナーであるデータを変更する場合の影響範囲を把握できるようにしました。
よいこと、課題
ターゲット側システムでのデータ処理の状況に応じて、所定のPathにデータを移動させる仕様とすることで、人間が目視でファイルの場所を確認し、処理状況を一旦把握できるようになります。これは、トラブルシュート時の認知負荷を下げる効果があります。
一方で課題としては、データソース側システムの対応工数が上がることや、ターゲットシステム側で連携して欲しいデータ要件が曖昧なままだと(とりあえずまとめてデータください、加工処理はこちらで考えます的な)、その連携I/Fの仕様を元にデータソース側システムでデータ改修を検討する際に正確な影響範囲の洗い出しができなくなってしまうことが考えられるので、これは気をつけなければいけません。
(4)AWSサービスを用いてのファイル連携の良さ
クラウドネイティブというワードが出てくる以前のファイル連携においては、「ゼロファイル連携」が要件によく上がっていました。これは、連携するデータがない場合に「連携するデータはなかったよ」を表現するためのお作法です。ターゲットシステム側の障害によりデータ連携できなかった時と識別するためです。また、そのデータの取り込みも定期バッチ処理で行うことが基本でした。
Amazon S3を用いたファイル連携であれば、ファイルputされたイベントをトリガーに後続処理を開始できるので、こういった考慮が必須ではなくなることは地味にありがたい機能です。
メンバー募集!
JINSでは様々な仲間を募集しています。ヒトが扱う様々な道具の中で、ものすごく長い間身につけているメガネというプロダクトを扱っています。自分たちで企画・デザイン・製造し、お客様に直接販売している製造小売業の会社なのですが、これからはシステム開発においても自分たちでできることをもっと増やしていき、EyesTechのリーディングカンパニーになるべく挑戦しています。JINSのロゴマークにある「!」は、ワクワクや驚きを表しています。ぜひ一緒に「新しい当たりまえ」を生み出していきませんか?

Discussion