🤖
Deno Webサイトをスクレイピングする




denoでWebサイトをスクレイピングする基本的な方法をまとめました。
今回はこのサイトを対象にスクレイピングし、以下画像のボタン内テキストを取得してみます!
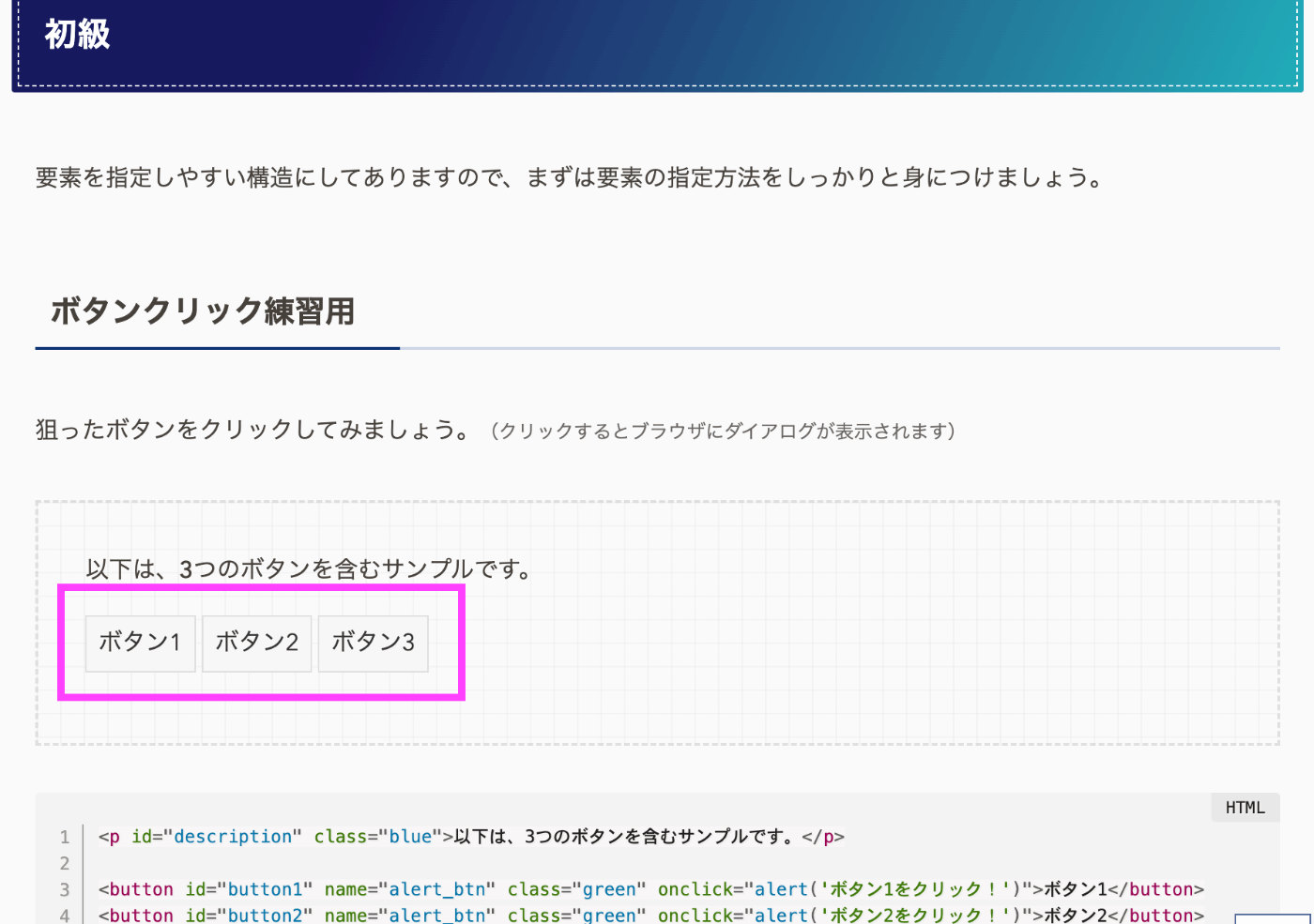
大まかな手順
- Webページの取得: fetch APIを使用してスクレイピング対象のWebページのHTMLを取得
- HTMLの解析: 取得したHTMLをDOMParserで解析し、DOMを構築
- データの抽出: 解析したDOMから、特定のセレクタを使用して必要なデータを含む要素を選択
- データの加工: 選択した要素から情報(テキストや属性値など)を抽出し、必要に応じて加工
実装
Webページの取得
まずスクレイピング用の関数を作成し、その中でfetch APIを使ってWebページを取得します。
そして、取得したレスポンス(res)からawait res.text()でテキスト(HTML)を非同期に抽出します。
async function scrape() {
const res = await fetch("https://appletools.blog/scraping-practice/");
const source = await res.text();
}
sourceをコンソールで確認すると、WebサイトのHTMLがテキスト形式で出力されます。
HTMLの解析
DOMParserのparseFromStringメソッドを使って、HTMLテキストからDOMを構築します。
import {
DOMParser
} from "https://deno.land/x/deno_dom/deno-dom-wasm.ts";
async function scrape() {
//...
const DOM = new DOMParser().parseFromString(source, "text/html");
データの抽出
querySelectorAllメソッドを使用して、特定の属性を持つ要素をすべて選択します。
今回は、name属性が"alert_btn"の要素を選択しています。
async function scrape() {
//...
const targets = DOM.querySelectorAll('[name="alert_btn"]');
データの加工
選択した要素から、今回はテキストを抽出してコンソールに結果を表示します。
各要素に対してループ処理を行い、innerTextプロパティを使用してテキスト内容を抽出します。
async function scrape() {
//...
const results: string[] = [];
targets.forEach(el => {
const text = el.innerText;
results.push(text);
});
console.log(results);
これで、以下のようにコンソールに出力されます。
[ "ボタン1", "ボタン2", "ボタン3" ]
エラー処理
最後にエラー処理を追加して終了です。
完成したコードは以下のようになります。
import {
DOMParser
} from "https://deno.land/x/deno_dom/deno-dom-wasm.ts";
async function scrape() {
try {
const res = await fetch("https://appletools.blog/scraping-practice/");
if (!res.ok) {
throw new Error(`HTTP error! status: ${res.status}`);
}
const source = await res.text();
const DOM = new DOMParser().parseFromString(source, "text/html");
const targets = DOM.querySelectorAll('[name="alert_btn"]');
const results: string[] = [];
targets.forEach(el => {
const text = el.innerText;
results.push(text);
});
console.log(results);
} catch (error) {
console.error("Scraping failed:", error.message);
}
}
scrape();
Discussion