はじめに
最近ChatGPTを始めとした生成AIの応用事例が増えているので、流行に乗っかる形で、社内でいままで手作業で行われていたタスクであるissueチケット登録作業を自動化した話をします。
本記事の要約
- 従来から運用していたIssueのチケット管理にて、登録されたメッセージから説明文を作成しGitHub issueへ登録するプロセスを手作業で行っており、かなり時間がかかっていました。
- このため、Azure OpenAI Service を中心に、Slack API + GitHub REST APIを使うことで上の作業を全て自動化しました。
Issueチケット管理
背景
顧客からのバグ報告の他に、開発、実装を行う過程で不具合に気づいたときや、ふと改善案を思いついた際に、
- 「今時間がないから後でissueに登録しておこう」
- 「事象があまり具体的ではないから、とりあえずslackには投稿しておいて、後で整理しておこう」
といった理由でチケットに乗りそびれてしまうケースが多く発生していました。
このため、より気軽にチケットを切れるように社内で次のワークフローを運用することにしました。
ワークフロー
-
slackに投稿された内容に「BUG」スタンプをつける

-
「BUG」スタンプがついた投稿がslack上のbug ticketチャンネルに転送される

- 週に一度、bug ticketチャンネルに投稿されたメッセージ一覧を、GitHub上にIssueとして登録。その後各IssueをPull Request等と紐付け、対処が完了したのであればstatusをcompletedにする。
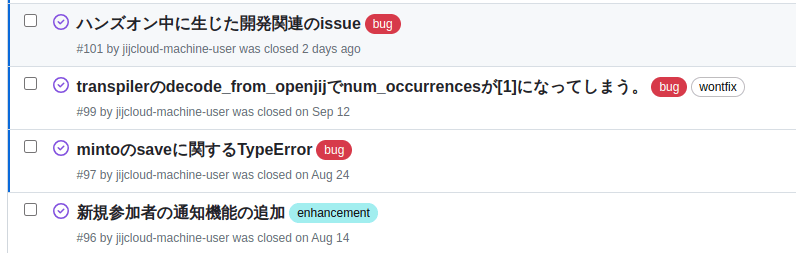
これにより、以前に比べてより些細なバグ、改善案までチケットとして拾うことができるようになりました。
この手順の問題点
実際に運用してみると、上の手順の3番目であるGitHub上に登録する手順について、
- 対応するメッセージへのリンクを貼る
- 一目で分かるような説明文を記述する
- チケットがバグ報告 (bug) なのか、改善案 (enhancement) なのかのラベルをつける
を全てのチケットに対して行う必要があるので予想以上に時間がかかり、長いときには全部のチケットを処理するのに2時間ほどかかっていたケースもありました。
このような背景もあり何とか自動化できないかと考えていたものの、特に「一目で分かるような説明文を記述する」の自動化が難しそうと考えていた手前、ちょうどこの頃 (2023/08) に生成AIがブームになっていた時期だったので、上の手順を自動化させてみました。
Issueチケット管理の自動化
OpenAI API (Azure OpenAI Service) の利用方法
生成AIを使う手法として、ChatGPTにアクセスしてプロンプトを入力するケースが多いですが、API経由で利用することも可能です。
今回はセキュリティの観点から、モデルの再トレーニングに入力データを使わない旨が明記されている Azure OpenAI Service を使用したので、こちらの方法を紹介します。
使い始めるまでのフローは以下のようになります。
1. リソースの作成 & モデルのデプロイ
こちら を参考に、Azure OpenAI Serviceでリソースの作成と、モデルのデプロイを行います。
上手く行くと次のようにデプロイを作成することができます。

この手順で取得できる以下の情報が次のステップで必要となります。
| 変数名 | 説明 |
|---|---|
OPENAI_AZURE_ENDPOINT |
Azure OpenAIのエンドポイント |
OPENAI_API_KEY |
OpenAIのAPIを利用するためのAPIキー |
OPENAI_AZURE_ENGINE |
Azure OpenAIのデプロイ名 (ここでは IssueTitleGenerator ) |
2. 試しに会話してみる
OpenAIのChatCompletion APIを使って、以下のようにリクエストを送ります。
上の変数は環境変数としてセットします。
import os
import openai
OPENAI_AZURE_ENDPOINT = os.environ["OPENAI_AZURE_ENDPOINT"]
OPENAI_API_KEY = os.environ["OPENAI_API_KEY"]
OPENAI_AZURE_ENGINE = os.environ["OPENAI_AZURE_ENGINE"]
openai.api_type = "azure"
openai.api_base = OPENAI_AZURE_ENDPOINT
openai.api_version = "2023-03-15-preview"
openai.api_key = OPENAI_API_KEY
response = openai.ChatCompletion.create(
engine=OPENAI_AZURE_ENGINE,
messages=[
{
"role": "system",
"content": "The reply form is '[<Your name>] <Text>'",
},
{
"role": "user",
"content": "Hello!",
},
],
temperature=0.7,
max_tokens=800,
top_p=0.95,
frequency_penalty=0,
presence_penalty=0,
stop=None,
)
print(response)
ここで、messagesにて、
{
"role": "system",
"content": "The reply form is '[<Your name>] <Text>'",
},
のように "role": "system"を指定すると、返答の形式等をリクエストすることができます。上の例では [相手の名前] 本文 の形式にするようにプロンプトしています。
"role": "user"に会話したい内容を送信します。
実行すると次のように結果が返ってきます。
{
"id": "chatcmpl-8Fu067P5fcPCGAHHSX63XP28zEWe9",
"object": "chat.completion",
"created": 1698800878,
"model": "gpt-35-turbo",
"choices": [
{
"index": 0,
"finish_reason": "stop",
"message": {
"role": "assistant",
"content": "[AI] Hello! How can I assist you today?"
}
}
],
"usage": {
"prompt_tokens": 27,
"completion_tokens": 12,
"total_tokens": 39
}
}
[AI] Hello! How can I assist you today? のように、"role": "system"で指定した形式で返答が返ってきていることがわかります。
Issue説明文およびGitHub Issueの自動生成
以下の手順を実行するスクリプトを組みました。
- Slack APIを利用し、bug ticketチャンネルにあるメッセージを過去1週間分取得する。
- 各slackメッセージを次の
generate_issue_title_sentence_via_gpt関数に渡す。- メッセージの内容がバグ報告に近いのであればslackメッセージから
BUG: [issueのタイトル] [issueの説明文]を、改善案に近いのであればENHANCEMENT: [issueのタイトル] [issueの説明文]といった出力を日本語で生成する。
- メッセージの内容がバグ報告に近いのであればslackメッセージから
def generate_issue_title_sentence_via_gpt(text: str) -> str:
"""Generate an issue title using GPT model."""
try:
response = openai.ChatCompletion.create(
engine=OPENAI_AZURE_ENGINE,
messages=[
{
"role": "system",
"content": "Your task is only to receive the request and return a sentence (issue or technical discussion) in Japanese with the following form: '<BUG or ENHANCEMENT>: [<title>] [<detailed sentence>]' where the character '[' and ']' must not be included in both title and detailed sentence. Examples of the form are 'BUG: [ソフトウェアのアクセストークンが無効になっている] [ソフトウェアを実行するのに必要なアクセストークンが無効になっており、本番環境が動作していない。] ' and 'ENHANCEMENT: [ユーザーフレンドリーなインターフェースの追加] [現在のJijZeptポータルサイトのインターフェースでは、ユーザーがメンバーを登録しようとしたときの次のアクションが明示されておらず、ユーザーに親切な設計ではないため、例えば次のアクションをポップアップメッセージで出すなどの改善が必要である。]'. If you cannot find a good sentence, you can only return a string 'ENHANCEMENT: [] []' without any additional notes.",
},
{
"role": "user",
"content": f"Summarize the following message into a short title and a detailed sentence:\n\n{text}",
},
],
temperature=0.7,
max_tokens=800,
top_p=0.95,
frequency_penalty=0,
presence_penalty=0,
stop=None,
)
print(response)
return response["choices"][0]["message"]["content"]
except:
import traceback
print(traceback.format_exc())
# If there's an API failure, return a default title
return "REPORTED ISSUE: [] []"
- 出力された形式を元に、GitHub REST APIを使い、生成したissueのタイトル、説明文のissueを生成し、BUG、もしくはENHANCEMENTのラベルを貼る。
全体のPythonスクリプトは以下となります。
ticketchecker/checker.py
import os
import re
from datetime import datetime, timedelta
import openai
import requests
# 設定
SLACK_TOKEN = os.environ["SLACK_TOKEN"]
SLACK_ISSUE_CHANNEL_ID = os.environ["SLACK_ISSUE_CHANNEL_ID"]
SLACK_POST_CHANNEL_ID = os.environ["SLACK_POST_CHANNEL_ID"]
GITHUB_TOKEN = os.environ["GITHUB_TOKEN"]
GITHUB_REPO = os.environ["GITHUB_REPO"]
OPENAI_AZURE_ENDPOINT = os.environ["OPENAI_AZURE_ENDPOINT"]
OPENAI_API_KEY = os.environ["OPENAI_API_KEY"]
OPENAI_AZURE_ENGINE = os.environ["OPENAI_AZURE_ENGINE"]
openai.api_type = "azure"
openai.api_base = OPENAI_AZURE_ENDPOINT
openai.api_version = "2023-03-15-preview"
openai.api_key = OPENAI_API_KEY
def extract_text_from_attachments(attachments):
text_chunks = []
for attachment in attachments:
if "message_blocks" in attachment:
blocks = attachment["message_blocks"]
for block in blocks:
if "message" in block:
text_chunks.append(str(block["message"]))
return "\n".join(text_chunks)
def has_zumi_reaction(reactions):
"""Check if a message has a :zumi: reaction."""
for reaction in reactions:
if reaction["name"] == "zumi":
return True
return False
def fetch_slack_messages() -> list:
endpoint = f"https://slack.com/api/conversations.history"
headers = {
"Authorization": f"Bearer {SLACK_TOKEN}",
"Content-Type": "application/json",
}
# Calculate timestamp for 1 week ago
one_week_ago = datetime.now() - timedelta(days=7)
oldest_timestamp = str(int(one_week_ago.timestamp()))
payload = {
"channel": SLACK_ISSUE_CHANNEL_ID,
"oldest": oldest_timestamp,
"inclusive": True,
"limit": 100, # Maximum messages to fetch, can be adjusted
}
response = requests.get(endpoint, headers=headers, params=payload)
messages = response.json().get("messages", [])
messages_with_replies = []
for message in messages:
# message_data data structure
# {
# "text": ["Message text", "Message text for prompt input"],
# "replies": ["Reply 1", "Reply 2", ...]
# }
# Skip messages with reactions :zumi:
if "reactions" in message and has_zumi_reaction(message["reactions"]):
continue
message_data = {"text": [message["text"], message["text"]], "replies": []}
# Extract text from blocks if they exist
if "attachments" in message:
message_data["text"][1] += "\n" + extract_text_from_attachments(
message["attachments"]
)
if "reply_users_count" in message and message["reply_users_count"] > 0:
thread_endpoint = f"https://slack.com/api/conversations.replies"
thread_payload = {"channel": SLACK_ISSUE_CHANNEL_ID, "ts": message["ts"]}
thread_response = requests.get(
thread_endpoint, headers=headers, params=thread_payload
)
thread_messages = thread_response.json().get("messages", [])
for reply_msg in thread_messages[1:]: # Excluding the parent message
reply_data = reply_msg["text"]
message_data["replies"].append(reply_data)
messages_with_replies.append(message_data)
return messages_with_replies
def fetch_slack_replies(ts: str) -> list:
endpoint = "https://slack.com/api/conversations.replies"
headers = {
"Authorization": f"Bearer {SLACK_TOKEN}",
"Content-Type": "application/x-www-form-urlencoded",
}
payload = {"channel": SLACK_ISSUE_CHANNEL_ID, "ts": ts}
response = requests.get(endpoint, headers=headers, params=payload)
data = response.json()
return [reply["text"] for reply in data["messages"][1:]]
def determine_labels(title: str) -> list:
labels = []
if title.startswith("BUG"):
labels.append("bug")
elif title.startswith("ENHANCEMENT"):
labels.append("enhancement")
return labels
def extract_title_and_body(text: str) -> tuple:
matches = re.findall(r"\[([^\]]+)\]", text)
if len(matches) == 2:
pattern = tuple(match for match in matches)
return pattern
else:
return ("", "")
# GitHubにIssueおよびコメントを作成
def create_github_issue(title: str, body: str, abstract: str, labels: list[str]) -> str:
endpoint = f"https://api.github.com/repos/{GITHUB_REPO}/issues"
headers = {
"Authorization": f"token {GITHUB_TOKEN}",
"Accept": "application/vnd.github.v3+json",
}
issue_title = "REPORTED ISSUE" if title == "" else title
issue_body = body + "\n\n" + "## Abstract " + "\n" + abstract
payload = {"title": issue_title, "body": issue_body, "labels": labels}
response = requests.post(endpoint, headers=headers, json=payload)
data = response.json()
if response.status_code == 201:
return data["html_url"]
return None
def create_github_comment(issue_number: str, body: str) -> bool:
endpoint = (
f"https://api.github.com/repos/{GITHUB_REPO}/issues/{issue_number}/comments"
)
headers = {
"Authorization": f"token {GITHUB_TOKEN}",
"Accept": "application/vnd.github.v3+json",
}
payload = {"body": body}
response = requests.post(endpoint, headers=headers, json=payload)
return response.status_code == 201
# Slackチャンネルにメッセージを投稿
def post_to_slack_channel(message: str) -> bool:
endpoint = "https://slack.com/api/chat.postMessage"
headers = {
"Authorization": f"Bearer {SLACK_TOKEN}",
"Content-Type": "application/json",
}
payload = {"channel": SLACK_POST_CHANNEL_ID, "text": message}
response = requests.post(endpoint, headers=headers, json=payload)
return response.status_code == 200
def generate_issue_title_sentence_via_gpt(text: str) -> str:
"""Generate an issue title using GPT model."""
try:
response = openai.ChatCompletion.create(
engine=OPENAI_AZURE_ENGINE,
messages=[
{
"role": "system",
"content": "Your task is only to receive the request and return a sentence (issue or technical discussion) in Japanese with the following form: '<BUG or ENHANCEMENT>: [<title>] [<detailed sentence>]' where the character '[' and ']' must not be included in both title and detailed sentence. Examples of the form are 'BUG: [ソフトウェアのアクセストークンが無効になっている] [ソフトウェアを実行するのに必要なアクセストークンが無効になっており、本番環境が動作していない。] ' and 'ENHANCEMENT: [ユーザーフレンドリーなインターフェースの追加] [現在のJijZeptポータルサイトのインターフェースでは、ユーザーがメンバーを登録しようとしたときの次のアクションが明示されておらず、ユーザーに親切な設計ではないため、例えば次のアクションをポップアップメッセージで出すなどの改善が必要である。]'. If you cannot find a good sentence, you can only return a string 'ENHANCEMENT: [] []' without any additional notes.",
},
{
"role": "user",
"content": f"Summarize the following message into a short title and a detailed sentence:\n\n{text}",
},
],
temperature=0.7,
max_tokens=800,
top_p=0.95,
frequency_penalty=0,
presence_penalty=0,
stop=None,
)
print(response)
return response["choices"][0]["message"]["content"]
except:
import traceback
print(traceback.format_exc())
# If there's an API failure, return a default title
return "REPORTED ISSUE: [] []"
def main():
messages_with_replies = fetch_slack_messages()
print(messages_with_replies)
issue_links = []
# メッセージを古い順に処理する
for message_data in reversed(messages_with_replies):
issue_content = generate_issue_title_sentence_via_gpt(message_data["text"][1])
issue_label = determine_labels(issue_content)
issue_title, issue_body = extract_title_and_body(issue_content)
issue_link = create_github_issue(
issue_title, message_data["text"][0], issue_body, issue_label
)
if issue_link:
issue_links.append(issue_link)
issue_number = issue_link.split("/")[
-1
] # Get the last part of the link, which is the issue number
for reply in message_data["replies"]:
create_github_comment(issue_number, reply)
links_str = "\n".join(issue_links)
post_to_slack_channel(f"1週間分のticketを収集し、issueに登録しました:\n{links_str}")
if __name__ == "__main__":
main()
スクリプト中の変数の定義は以下の通りです。
| 変数名 | 説明 |
|---|---|
SLACK_TOKEN |
SlackのAPIを利用するためのOAuthアクセストークン。 |
SLACK_ISSUE_CHANNEL_ID |
issueを収集したいSlackチャンネルのID。 |
SLACK_POST_CHANNEL_ID |
メッセージを投稿したいSlackチャンネルのID。 |
GITHUB_TOKEN |
GitHubのAPIを利用するためのPersonal Access Token。 |
OPENAI_AZURE_ENDPOINT |
Azure OpenAIのエンドポイント。 |
GITHUB_REPO |
Issueを作成したいGitHubリポジトリの名前。'ユーザ名/リポジトリ名'の形式。 |
OPENAI_API_KEY |
OpenAIのAPIを利用するためのAPIキー。 |
OPENAI_AZURE_ENGINE |
Azure OpenAIのデプロイしたモデル名。 |
GitHub Actions ワークフローを使ったジョブの定期実行
以下のGitHub Actionsのyamlファイルを作成し、リポジトリ内の.github/workflows/run.ymlに配置すると、1週間に1度ジョブを実行することができます。
run.yml
name: Python Run
on:
workflow_dispatch:
schedule:
- cron: '0 1 * * 1'
jobs:
test_python:
name: python3.9-x64 ubuntu-latest
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v3
- name: Setup Python
uses: actions/setup-python@v4
with:
python-version: '3.9'
cache: 'pip'
- name: Setup virtual environment
run: |
set -eux
python -m venv venv
. venv/bin/activate
- name: Install Dependencies
run: |
set -eux
. venv/bin/activate
pip install --upgrade pip
pip install pip-tools
pip-compile requirements.in
pip-sync requirements.txt
- name: Run Code
env:
SLACK_TOKEN: ${{ secrets.SLACK_TOKEN }}
SLACK_ISSUE_CHANNEL_ID: ${{ secrets.SLACK_ISSUE_CHANNEL_ID }}
SLACK_POST_CHANNEL_ID: ${{ secrets.SLACK_POST_CHANNEL_ID }}
GITHUB_TOKEN: ${{ secrets.GIT_HUB_TOKEN }}
OPENAI_AZURE_ENDPOINT: ${{ secrets.OPENAI_AZURE_ENDPOINT }}
GITHUB_REPO: ${{ secrets.GIT_HUB_REPO }}
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
OPENAI_AZURE_ENGINE: ${{ secrets.OPENAI_AZURE_ENGINE }}
run: |
. venv/bin/activate
python ticketchecker/checker.py
実際に動かしてみた
次のようなバグ報告 (ポータルサイトのレイアウトずれ)に対して、
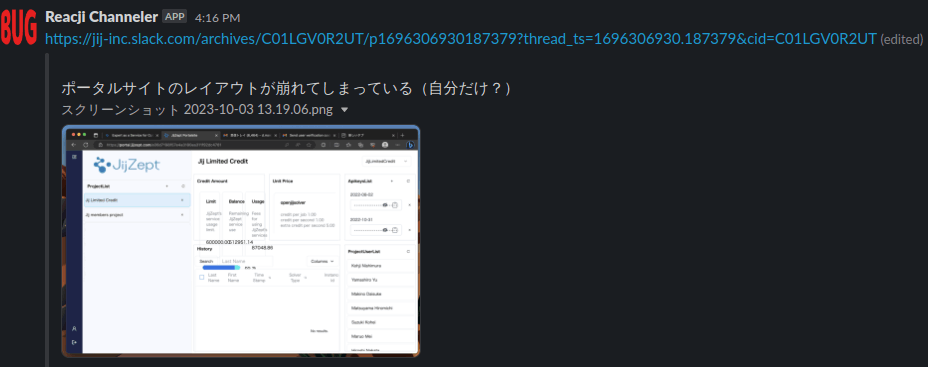
次のようなissueタイトル、issue本文を生成します。このissueの内容はバグ報告に相当するので、BUG ラベルも自動で設定されています。

また、次のような改善案に相当するメッセージは、

以下のようなissue文になります。この時は改善案を示すENHANCEMENTラベルが設定されます。

これにより、今まで長時間手動で行っていたGitHubへのissue登録が全て自動で行えるようになりました。
その他
たまにプロンプトに対して反抗してくるようで、"role": "system"にて指定したフォーマットをガン無視するケースがちょくちょくあるみたいです。
画像が小さいですが、以下の例は指定したフォーマットを無視して 「これはバグ報告でも改善案でもなく、ただの結果の報告にすぎないからissueとして扱う必要はないはずだ」 というメッセージが返されてしまっています。

こういうところは割と人間味があって面白いですね。
まとめ
生成AIを用いたアプリケーションを初めて作ってみましたが、今まで手作業で行っていた面倒くさい作業が自動化でき、さらにコストもかなり少ないので (1週間分のissue作成に3円程度)実用に耐えうるものになりました。
APIを叩くのは極めて簡単にできるので、もし皆さんの業務の中で時間のかかっている処理があれば、利用を検討してみるのはいかがでしょうか?
また、JijのXのフォローもよろしくお願いします!

Discussion