この記事はjig.jp Advent Calendar 2024の12日目の記事です。
最近業務でFlaxを使った機械学習のコードを書く機会があったので、Flaxについて紹介します。
Flaxとは?
FlaxとはGoogleが開発している機械学習のライブラリです。同じくGoogleが開発している数値計算ライブラリであるJAXの上に構築されているため、両者をまとめてJAX/Flaxと呼ばれることもあります。
同じく機械学習のライブラリであるTensorFlowやPyTorchと比較して、以下のような特徴があると言われています。
- 高速: GPUやTPUを用いた計算に最適された数値計算ライブラリであるJAXの上に構築されているため高速
- 再現性: 乱数が関係する関数はすべて乱数生成ためのキーを明示的に受け取るため再現性を担保
- 関数型: モデルもオプティマイザも内部に状態を持たない
・・・いいえ、 言われていました。 私もFlaxを使い始めるまでは上記のような評判を聞いていたのですが、実際触ってみると3番目の 関数型 に関しては今年に入ってから様相が随分と変わっており、モデルもオプティマイザもガッツリ内部に状態を持つようになっていました。
関数型でなくなったFlaxについての情報は本記事執筆時点ではQiitaにもZennにもほとんどありません。Flaxに関する日本語の書籍も私が知る限り1冊だけ存在しますが昨年出版された本なのでまだバリバリ関数型です。
これはもしかして、関数型でなくなったFlaxの本格的な紹介記事を一番乗りで公開するチャンス!?
ということで、Flaxについて紹介していこうと思います。
本記事執筆時点でのFlaxの最新バージョンは・・・
%pip install --upgrade -q flax
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 424.2/424.2 kB 11.1 MB/s eta 0:00:0000:01
import flax
flax.__version__
'0.10.2'
です。
(この記事はGoogle Colaboratoryで執筆したものをZennに転記しています。もとのipynbファイルはこちらからご覧いただけます)
Flax Linen(今までの関数型Flax)
まずは、以前から存在している関数型のAPIであるFlax Linenを用いたコードを紹介します。Flax公式サイトのトップページでも新しく追加された関数型でないAPIである NNX が推されていますが、Linenもまだまだ現役です。
以下のコードは、Linenを用いて書かれた画像分類を行うネットワークの例です。setup メソッドの中でレイヤーを作成し、 __call__ メソッドの中で順伝播を定義しています。一見PyTorchによく似ていますが、例えば以下のような違いがあります。
-
レイヤー作成のメソッドが
__init__ではなくsetup: このため、モデルのインスタンスを作った直後はフィールドが存在していない(model = LinenModel(10); print(model.conv1)のようなコードはAttributeError)という点には少し注意が必要です -
レイヤー作成時に指定するテンソルのサイズが出力だけ: PyTorchでは
nn.Linear(in_features=4096, out_features=128)のように入力と出力のサイズを渡す必要がありますが、Linenではnn.Dense(features=128)のように出力だけ指定すればいいので少し楽です -
順伝播のメソッドにモードを表すフラグを渡さないといけない場合がある: BatchNormやDropoutのように学習時と推論時で異なるレイヤーに対応するために、PyTorchにはモデルのモードを切り替える
trainとevalメソッドがありますが、Linenのモデルは状態を持たないため外部からモードを表すフラグを渡す必要があります
import jax
import jax.numpy as jnp
import numpy as np
from flax import linen as nn
ArrayLike = jax.Array | np.ndarray
class LinenModel(nn.Module):
num_classes: int
dropout_rate: float = 0.5
def setup(self) -> None:
self.conv1 = nn.Conv(features=32, kernel_size=(3, 3))
self.bn1 = nn.BatchNorm()
self.conv2 = nn.Conv(features=64, kernel_size=(3, 3))
self.bn2 = nn.BatchNorm()
self.linear1 = nn.Dense(features=128)
self.dropout = nn.Dropout(rate=self.dropout_rate)
self.linear2 = nn.Dense(features=self.num_classes)
def __call__(self, x: ArrayLike, train: bool = True) -> jax.Array:
x = self.conv1(x)
x = nn.relu(x)
x = self.bn1(x, use_running_average=not train)
x = nn.max_pool(x, window_shape=(2, 2), strides=(2, 2))
x = self.conv2(x)
x = nn.relu(x)
x = self.bn2(x, use_running_average=not train)
x = nn.max_pool(x, window_shape=(2, 2), strides=(2, 2))
x = x.reshape((x.shape[0], -1))
x = self.linear1(x)
x = nn.relu(x)
x = self.dropout(x, deterministic=not train)
x = self.linear2(x)
return x
Linenのモデルは内部に状態を持たないため、代わりに状態を管理するためのTrainStateクラスのインスタンスを使います。BatchNormやDropoutを用いる場合は、それらの情報もTrainStateに含める必要があります。以下のコードがTrainStateを作る関数です。
オプティマイザとしては、OptaxというライブラリにあるAdamWを使っています。JAX/Flaxを使うときは大抵Optaxもセットになりますが、JAX/Flax/Optaxのような呼ばれ方はあまりしない気がします。
from typing import Any
import optax
from flax.training import train_state
IMG_SIZE = 32
IMG_CHANNELS = 3
class TrainState(train_state.TrainState):
batch_stats: Any
dropout_key: jax.Array
def create_train_state(
model: nn.Module,
learning_rate: float,
weight_decay: float
) -> TrainState:
# パラメータ初期化用とDropout用の乱数キーを作る
root_key = jax.random.key(seed=0)
params_key, dropout_key = jax.random.split(key=root_key, num=2)
# パラメータの初期化。
# `model.init` は初期化されたパラメータを返すだけで、modelは状態を持たない
variables = model.init(
params_key,
jnp.ones([1, IMG_SIZE, IMG_SIZE, IMG_CHANNELS]),
train=False
)
# オプティマイザとしてAdamWを使う
tx = optax.adamw(learning_rate, weight_decay=weight_decay)
# TrainStateのインスタンスを作る
params = variables["params"]
batch_stats = variables["batch_stats"]
return TrainState.create(
apply_fn=model.apply,
params=params, # パラメータ
batch_stats=batch_stats, # BatchNormの状態
dropout_key=dropout_key, # Dropoutのキー
tx=tx # オプティマイザ
)
以下が状態を更新する関数です。Linenを使った機械学習コードのうち、ここが一番Linenらしい部分だと思います。コードをよく読むとわかりますが、この関数は状態を受け取って新しい状態を返すだけの純粋関数になっています。そして、純粋関数は @jax.jit デコレータを付けることでGPU用にJITコンパイルされるようになり、より高速な実行が可能になります。
BatchNormやDropoutを使う場合、モデルの新しい状態を計算する state.apply_fn 関数にBatchNormの状態 state.batch_stats やステップごとに生成したDropoutの乱数キー dropout_train_key を明示的に渡す必要があります。
@jax.jit
def train_step_linen(
state: TrainState,
batch: tuple[ArrayLike, ArrayLike]
) -> tuple[TrainState, jax.Array, jax.Array]:
"""
学習ステップ
"""
(images, labels) = batch
dropout_train_key = jax.random.fold_in(key=state.dropout_key, data=state.step)
def loss_fn(
params: dict[str, Any]
) -> tuple[jax.Array, tuple[jax.Array, jax.Array]]:
# 損失とモデルの新しい状態を計算する
(logits, updates) = state.apply_fn(
{"params": params, "batch_stats": state.batch_stats},
images,
train=True,
mutable=["batch_stats"],
rngs={"dropout": dropout_train_key}
)
loss = cross_entropy_loss(logits, labels)
return (loss, (logits, updates))
# 勾配などを計算する
grad_fn = jax.value_and_grad(loss_fn, has_aux=True)
((loss, (logits, updates)), grads) = grad_fn(state.params)
# 状態を更新する
state = state.apply_gradients(grads=grads)
state = state.replace(batch_stats=updates["batch_stats"])
accuracy = compute_accuracy(logits, labels)
return (state, loss, accuracy)
def cross_entropy_loss(logits: ArrayLike, labels: ArrayLike) -> jax.Array:
"""損失関数"""
return optax.softmax_cross_entropy_with_integer_labels(logits, labels).mean()
def compute_accuracy(logits: ArrayLike, labels: ArrayLike) -> jax.Array:
"""正解率を計算する"""
predictions = jnp.argmax(logits, axis=-1)
return jnp.mean(predictions == labels)
以上のように状態を明示的に引数や戻り値として扱うのは分かりやすくはあるのですが、状態の種類が増えると修正が煩雑になることがあります。事実、BatchNormとDropoutを使っているここまでのコードも若干煩雑になっています。Flax公式サイトのWhy Flax NNXのページ でもまさにこのBatchNormとDropoutを例に挙げてLinenの煩雑さを指摘しています。
それはともかく、Linenを使ったコードの例を最後まで見てみましょう。 10種類のラベルが付いた32px * 32pxの小さなカラー画像のデータセットであるCIFAR-10を読み込み、画像の分類を学習するコードです。
import time
from typing import TypedDict
from tqdm import tqdm
import pandas as pd
import plotly.express as px
import tensorflow as tf
import tensorflow_datasets as tfds
def get_datasets(batch_size: int) -> tuple[tf.data.Dataset, tf.data.Dataset]:
"""
CIFAR-10データセットの画像をダウンロードし、学習用に加工する
"""
def preprocess(example: dict[str, tf.Tensor]) -> tuple[tf.Tensor, tf.Tensor]:
image = example["image"]
label = example["label"]
image = tf.cast(image, tf.float32) / 255.0
image = tf.image.resize(image, (IMG_SIZE, IMG_SIZE))
return (image, label)
ds_builder = tfds.builder("cifar10")
ds_builder.download_and_prepare()
train_ds = ds_builder.as_dataset(split="train")
test_ds = ds_builder.as_dataset(split="test")
train_ds = train_ds.map(preprocess, num_parallel_calls=tf.data.AUTOTUNE)
train_ds = train_ds.shuffle(1024, seed=42).batch(batch_size).prefetch(tf.data.AUTOTUNE)
test_ds = test_ds.map(preprocess, num_parallel_calls=tf.data.AUTOTUNE)
test_ds = test_ds.batch(batch_size).prefetch(tf.data.AUTOTUNE)
return (train_ds, test_ds)
@jax.jit
def eval_step_linen(
state: TrainState,
batch: tuple[ArrayLike, ArrayLike]
) -> tuple[jax.Array, jax.Array]:
"""
評価ステップ
"""
(images, labels) = batch
logits = state.apply_fn(
{"params": state.params, "batch_stats": state.batch_stats},
images,
train=False
)
loss = cross_entropy_loss(logits, labels)
accuracy = compute_accuracy(logits, labels)
return (loss, accuracy)
class HyperParams(TypedDict):
"""
ハイパーパラメータ
"""
num_classes: int
num_epochs: int
batch_size: int
dropout_rate: float
learning_rate: float
weight_decay: float
def main_linen(
hyperparams: HyperParams
) -> tuple[TrainState, list[float], list[float], list[float], list[float]]:
"""
Linenの画像分類モデルの学習を行う
"""
# データセットの取得
(train_ds, test_ds) = get_datasets(hyperparams["batch_size"])
# モデルとトレーニングステートの初期化
model = LinenModel(
num_classes=hyperparams["num_classes"],
dropout_rate=hyperparams["dropout_rate"]
)
state = create_train_state(model, hyperparams["learning_rate"], hyperparams["weight_decay"])
# 学習ループ
train_losses: list[float] = []
test_losses: list[float] = []
train_accs: list[float] = []
test_accs: list[float] = []
for epoch in tqdm(range(1, hyperparams["num_epochs"] + 1)):
# 学習
train_loss = 0.0
train_acc = 0.0
num_train_batches = 0
for batch in tfds.as_numpy(train_ds):
(state, loss, acc) = train_step_linen(state, batch)
train_loss += loss
train_acc += acc
num_train_batches += 1
train_loss /= num_train_batches
train_acc /= num_train_batches
# 評価
test_loss = 0.0
test_acc = 0.0
num_test_batches = 0
for batch in tfds.as_numpy(test_ds):
(loss, acc) = eval_step_linen(state, batch)
test_loss += loss
test_acc += acc
num_test_batches += 1
test_loss /= num_test_batches
test_acc /= num_test_batches
train_losses.append(train_loss.item())
test_losses.append(test_loss.item())
train_accs.append(train_acc.item())
test_accs.append(test_acc.item())
return (state, train_losses, test_losses, train_accs, test_accs)
Flaxに限ったことではないのですが、GPUを使った機械学習をすると乱数を固定していても毎回結果が違ってくる場合があります。それが困る場合、JAX/Flaxでは以下の環境変数を設定することで多少のパフォーマンス低下と引き換えに結果を固定できるそうです。
ただし、今回記事の執筆に利用しているColaboratoryの無料GPU(T4)では学習時に XlaRuntimeError: UNIMPLEMENTED: HLO instruction select-and-scatter.1050.0 does not have a deterministic implementation, but run-to-run determinism is required. というエラーが出たので、今回は設定せずに学習を走らせます。
# %env XLA_FLAGS=--xla_gpu_deterministic_ops=true
# %env TF_DETERMINISTIC_OPS=1
では学習を走らせてみます。
# ハイパーパラメータ
hyperparams: HyperParams = dict(
num_classes=10,
num_epochs=30,
batch_size=128,
dropout_rate=0.5,
learning_rate=0.01,
weight_decay=0.001,
)
# %%timeで計測する学習時間にデータセットのダウンロードにかかる時間を含めたくないので別セルで実行
get_datasets(hyperparams["batch_size"])
Downloading and preparing dataset 162.17 MiB (download: 162.17 MiB, generated: 132.40 MiB, total: 294.58 MiB) to /root/tensorflow_datasets/cifar10/3.0.2...
(以下略)
%%time
# %%timeで時間を計測しつつ学習
print("Start!")
(train_state, train_losses, test_losses, train_accs, test_accs) = main_linen(hyperparams)
print("\nFinished!")
Start!
100%|██████████| 30/30 [01:52<00:00, 3.74s/it]
Finished!
CPU times: user 2min 2s, sys: 33.8 s, total: 2min 36s
Wall time: 1min 57s
30エポックで約2分かかりました。
損失と正解率の変化をグラフにしてみました。ちゃんと学習できているようですね。
import plotly.graph_objects as go
from plotly.subplots import make_subplots
def show_graph(
num_epocs: int,
train_loss: list[float],
test_loss: list[float],
train_accuracy: list[float],
test_accuracy: list[float]
) -> None:
"""
lossと正解率のグラフをプロットする
"""
epochs = list(range(1, 1 + num_epocs))
# サブプロットを作成(1行2列)
fig = make_subplots(rows=1, cols=2, subplot_titles=("train & test loss", "train & test accuracy"))
# 左側にlossのグラフ
fig.add_trace(go.Scatter(x=epochs, y=train_loss, mode="lines", name="train_loss"), row=1, col=1)
fig.add_trace(go.Scatter(x=epochs, y=test_loss, mode="lines", name="test_loss"), row=1, col=1)
# 右側に正解率のグラフ
fig.add_trace(go.Scatter(x=epochs, y=train_accuracy, mode="lines", name="train_acc"), row=1, col=2)
fig.add_trace(go.Scatter(x=epochs, y=test_accuracy, mode="lines", name="test_acc"), row=1, col=2)
fig.update_xaxes(title_text="epoch", row=1, col=1)
fig.update_xaxes(title_text="epoch", row=1, col=2)
fig.update_yaxes(title_text="loss", row=1, col=1)
fig.update_yaxes(title_text="accuracy", row=1, col=2)
# レイアウトを更新
fig.update_layout(
title="loss & accuracy",
legend_title="value",
width=1000,
height=500
)
# グラフを表示
fig.show()
show_graph(hyperparams["num_epochs"], train_losses, test_losses, train_accs, test_accs)

Flax NNX(関数型でなくなった新しいFlax)
ここからは、関数型でなくなったFlaxの新しいAPIである NNX がLinenとどのように違うか見ていきます。
Linenの例で紹介したのと同様の画像分類を行うネットワークは以下のようなコードになり、Linenとは以下のような点が異なります。
-
レイヤー作成のメソッドが
__init__になった: そのため、model = LinenModel(10, rngs=nnx.Rngs(42)); print(model.conv1)のようなコードも普通に動くようになりました -
レイヤー作成時に指定するテンソルのサイズが入力も必要:
nn.Dense(features=128)のように出力だけ指定していたのが、nnx.Linear(in_features=4096, out_features=128, rngs=rngs)のように入力も指定が必要になりました - モードはモデル自身が管理するようになった: そのため、順伝播のメソッドにモードを表すフラグを渡さなくてもよくなりました
- 乱数ジェネレータを受け取るようになった: パラメータの初期化などのために乱数が必要なレイヤーはそのためのジェネレータを明示的に受け取るようになりました
なんということでしょう、Linenの説明でPyTorchとの違いとして挙げたポイントがすべて PyTorchと同じになりました!
一方、LinenともPyTorchとも異なる点もあります。とくに目立つのは、乱数ジェネレータを rngs というキーワード専用引数で受け取るようになったことです。乱数ジェネレータが自分で乱数キーを管理するようになったので、ステップごとに乱数キーを作り直さなくても良くなりました。
from flax import nnx
class NNXModel(nnx.Module):
num_classes: int
dropout_rate: float = 0.5
def __init__(
self, num_classes: int, dropout_rate: float = 0.5, *, rngs: nnx.Rngs
) -> None:
super().__init__()
self.num_classes = num_classes
self.dropout_rate = dropout_rate
self.conv1 = nnx.Conv(in_features=IMG_CHANNELS, out_features=32, kernel_size=(3, 3), rngs=rngs)
self.bn1 = nnx.BatchNorm(num_features=32, rngs=rngs)
self.conv2 = nnx.Conv(in_features=32, out_features=64, kernel_size=(3, 3), rngs=rngs)
self.bn2 = nnx.BatchNorm(num_features=64, rngs=rngs)
self.linear1 = nnx.Linear(in_features=4096, out_features=128, rngs=rngs)
self.dropout = nnx.Dropout(self.dropout_rate, rngs=rngs)
self.linear2 = nnx.Linear(in_features=128, out_features=self.num_classes, rngs=rngs)
def __call__(self, x: jax.Array) -> jax.Array:
x = self.conv1(x)
x = nnx.relu(x)
x = self.bn1(x)
# max_poolは本記事執筆時点ではNNXに無いのでLinenのもので代用。
# 近い内にNNXに追加されそう: https://github.com/google/flax/pull/4408
x = nn.max_pool(x, window_shape=(2, 2), strides=(2, 2))
x = self.conv2(x)
x = nnx.relu(x)
x = self.bn2(x)
x = nn.max_pool(x, window_shape=(2, 2), strides=(2, 2))
x = x.reshape((x.shape[0], -1))
x = self.linear1(x)
x = nnx.relu(x)
x = self.dropout(x)
x = self.linear2(x)
return x
モデルが状態を持つようになったことで、Linenの例で書いた create_train_state に相当する関数は、書くとすれば以下のようにめちゃくちゃシンプルになりました。もはや、わざわざ関数にするまでもないくらいですね。
def create_optimizer(
model: nnx.Module, learning_rate: float, weight_decay: float
) -> nnx.Optimizer:
# オプティマイザとしてAdamWを使う
tx = optax.adamw(learning_rate, weight_decay=weight_decay)
return nnx.Optimizer(model, tx)
学習ステップのコードも以下のようにかなりシンプルになりました。煩雑だったDropoutとBatchNormの状態更新のコードが無くなり、 optimizer.update() を呼び出すだけでよくなりました。さらに便利な点として、正解率などを計算するための MultiMetric というクラスが追加され、計算に必要な値を渡すだけでそれらのメトリクスを計算してくれるようになりました。
一方、JITコンパイルを行うためのデコレータが @jax.jit から @nnx.jit になった点には注意が必要です。これは @jax.jit は純粋関数に付けることが前提であるのに対し、NNXの学習ステップの関数は引数の model や optimizer や metrics に対してバリバリ副作用を起こすためです。同様に、勾配を計算するのに使っている関数も jax.value_and_grad から nnx.value_and_grad になっているのにも気をつけましょう。
from collections.abc import Callable
@nnx.jit
def train_step_nnx(
model: Callable[[jax.Array], jax.Array],
optimizer: nnx.Optimizer,
metrics: nnx.MultiMetric,
batch: tuple[ArrayLike, ArrayLike]
) -> None:
"""
学習ステップ
"""
(images, labels) = (jnp.asarray(batch[0]), jnp.asarray(batch[1]))
def loss_fn(
model: Callable[[jax.Array], jax.Array],
) -> tuple[jax.Array, jax.Array]:
# 損失を計算する
logits = model(images)
loss = cross_entropy_loss(logits, labels)
return (loss, logits)
# 勾配などを計算する
grad_fn = nnx.value_and_grad(loss_fn, has_aux=True)
((loss, logits), grads) = grad_fn(model)
# メトリクスを記録する
metrics.update(loss=loss, logits=logits, labels=labels)
# 状態を更新する
optimizer.update(grads)
画像を読み込み分類を学習するコードはLinenの例と大体同じですが、学習ステップの前に model.train() を、評価ステップの前に model.eval() を呼ぶことを忘れないようにしましょう。(本記事執筆中実際に書き忘れ、正解率がLinenより明らかに低い値にしかならなくて、書き忘れに気づかないまま原因を調査して時間を無駄にしました)
また、 MultiMetric クラスに正解率の計算を任せられるようになったおかげで、コードが少しシンプルになっています。
@nnx.jit
def eval_step_nnx(
model: Callable[[jax.Array], jax.Array],
metrics: nnx.MultiMetric,
batch: tuple[jax.Array, jax.Array],
) -> None:
"""
評価ステップ
"""
(images, labels) = (jnp.asarray(batch[0]), jnp.asarray(batch[1]))
logits = model(images)
loss = cross_entropy_loss(logits, labels)
metrics.update(loss=loss, logits=logits, labels=labels)
def main_nnx(hyperparams: HyperParams) -> tuple[nnx.Optimizer, dict[str, list[float]]]:
"""
NNXの画像分類モデルの学習を行う
"""
# データセットの取得
train_ds, test_ds = get_datasets(hyperparams["batch_size"])
# モデルとオプティマイザの初期化
model = NNXModel(
num_classes=hyperparams["num_classes"],
dropout_rate=hyperparams["dropout_rate"],
rngs=nnx.Rngs(42)
)
optimizer = create_optimizer(model, hyperparams["learning_rate"], hyperparams["weight_decay"])
# 記録するメトリクスを設定(損失と正解率)
metrics = nnx.MultiMetric(
accuracy=nnx.metrics.Accuracy(),
loss=nnx.metrics.Average("loss")
)
# 学習ループ
metrics_history: dict[str, list[float]] = {
"train_loss": [],
"test_loss": [],
"train_accuracy": [],
"test_accuracy": []
}
for epoch in tqdm(range(1, hyperparams["num_epochs"] + 1)):
# 学習
model.train()
for batch in tfds.as_numpy(train_ds):
train_step_nnx(model, optimizer, metrics, batch)
# 学習メトリクスの記録
for metric, value in metrics.compute().items():
metrics_history[f"train_{metric}"].append(value.item())
metrics.reset()
# 評価
model.eval()
for batch in tfds.as_numpy(test_ds):
eval_step_nnx(model, metrics, batch)
# 評価メトリクスの記録
for metric, value in metrics.compute().items():
metrics_history[f"test_{metric}"].append(value.item())
metrics.reset()
train_loss = metrics_history["train_loss"][-1]
train_acc = metrics_history["train_accuracy"][-1]
test_loss = metrics_history["test_loss"][-1]
test_acc = metrics_history["test_accuracy"][-1]
return (optimizer, metrics_history)
学習を走らせてみます。
%%time
print("Start!")
(optimizer, metrics_history) = main_nnx(hyperparams)
print("\nFinished!")
Start!
100%|██████████| 30/30 [02:20<00:00, 4.67s/it]
Finished!
CPU times: user 3min 7s, sys: 32.5 s, total: 3min 40s
Wall time: 2min 20s
30エポックで約2分半かかりました。Linenよりは少し遅いようですね。
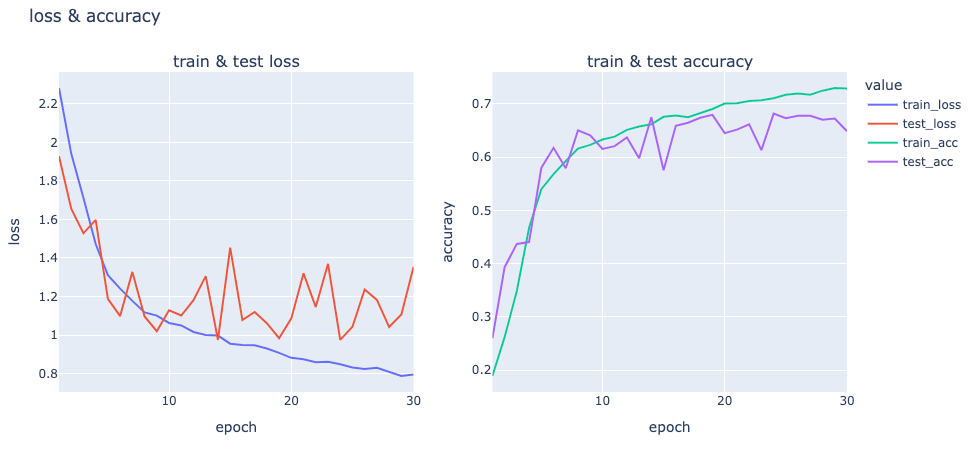
損失と正解率の変化をグラフにしてみました。Linenと同じようなグラフになりました。ちゃんと学習できているようですね。
show_graph(
hyperparams["num_epochs"],
metrics_history["train_loss"], metrics_history["test_loss"],
metrics_history["train_accuracy"], metrics_history["test_accuracy"]
)
Flax NNXモデルの保存と読み込み
せっかくモデルの学習ができたのですから、そのモデルを保存・読み込みして再利用したり追加学習したりできるようにしたいと思うのは当然でしょう。NNXのモデルを保存する方法はいくつかあり、いずれも一長一短あります。
cloudpickleを使う方法(一番お手軽)
一番お手軽なのはcloudpickleというライブラリを使う方法です。標準ライブラリにあるpickleと同じような使い勝手のデータシリアライズのライブラリですが、関数やクラスなどのpickleが対応していないオブジェクトもシリアライズできます。実はこの方法は(私が見落としてなければ)本記事執筆時点では公式ドキュメントにも書かれておらず、わりと最近リリースされたバージョンで対応されたばかりのものです。
たったこれだけのコードで保存と読み込みができます。
import cloudpickle
# オプティマイザとモデルを保存
with open("nnx_model.pkl", "wb") as f:
cloudpickle.dump(optimizer, f)
# オプティマイザとモデルを読み込み
with open("nnx_model.pkl", "rb") as f:
optimizer_loaded = cloudpickle.load(f)
テスト用の画像を100枚分類して何枚正しく分類できるか見てみましょう。
CIFAR-10は名前の通り10種類のラベルを含むデータセットなので完全ランダムに分類したら正解数は10前後になるはずですが、それよりは遥かに多い枚数正解しました。ちゃんと学習済みのモデルを読み込めているようですね。
(test_images, test_labels) = next(iter(tfds.as_numpy(get_datasets(100))[1]))
(jnp.argmax(optimizer_loaded.model(test_images), axis=1) == test_labels).sum()
Array(63, dtype=int32)
モデルをオプティマイザごと保存すると、モデルの追加学習も簡単です。例えば1ステップ分だけ追加学習するコードは以下のようになります。ちゃんと学習前後でステップ数が増えているのが確認できますね。
metrics = nnx.MultiMetric(
accuracy=nnx.metrics.Accuracy(),
loss=nnx.metrics.Average("loss")
)
print(f"Before: step={optimizer_loaded.step.item()}")
train_step_nnx(optimizer_loaded.model, optimizer_loaded, metrics, (test_images, test_labels))
print(f"After: step={optimizer_loaded.step.item()}")
Before: step=11730
After: step=11731
cloudpickleは非常にお手軽な方法ですが、ひとつ大きな欠点があります。それは セキュリティ面で非常に大きな問題があるため モデルの配布には向かないということです。READMEにも以下のように書かれているとおり、 任意コード実行が可能 なファイルフォーマットであるためです。
Security notice: one should only load pickle data from trusted sources as otherwise pickle.load can lead to arbitrary code execution resulting in a critical security vulnerability.
Orbaxを使う方法(公式が推奨)
公式ドキュメント に書かれているのは、Orbaxというライブラリを使う方法です。Orbaxは非常に多機能で、オプティマイザの状態に加えて正解率などのメトリクスをエポックごとに保存しておき、最も良かったエポックのものを読み込むといった機能などがあります。
公式ドキュメントに書かれているのは単にモデル保存して読み込むだけの単純な例ですが、せっかくなのでエポックを指定してオプティマイザとモデルを正解率とともに保存する関数を書いてみました。
import orbax.checkpoint as ocp
def save_with_orbax(
state: nnx.State,
checkpoint_dir: str,
epoch: int,
accuracy: float
) -> None:
# モデルの比較方法を設定(正解率が高いモデルが良いモデル)
options = ocp.CheckpointManagerOptions(
best_fn=lambda metrics: metrics["accuracy"]
)
# オプティマイザとモデルの状態を保存
with ocp.CheckpointManager(checkpoint_dir, options=options) as mgr:
mgr.save(
epoch,
args=ocp.args.StandardSave(state),
metrics={
"accuracy": accuracy
}
)
そして以下のように nnx.state でオプティマイザとモデルの状態だけを取り出して上記の関数に渡せば保存ができ・・・ ませんでした!!!
長々とエラーが出ていますね。これも本記事執筆時点では公式ドキュメントに書かれていないハマりポイントなので詳しく解説します(続きはスタックトレースの後で)
import os.path
save_with_orbax(
nnx.state(optimizer),
os.path.abspath("orbax_checkpoint"),
hyperparams["num_epochs"],
metrics_history["test_accuracy"]
)
ERROR:absl:[process=0] Failed to run 2 Handler Commit operations or the Commit callback in background save thread, directory: /content/orbax_checkpoint/30
Traceback (most recent call last):
File "/usr/local/lib/python3.10/dist-packages/orbax/checkpoint/async_checkpointer.py", line 121, in _thread_func
future.result()
(中略)
<ipython-input-23-eb966cc00ef0> in <cell line: 3>()
1 import os.path
2
----> 3 save_with_orbax(
4 nnx.state(optimizer),
5 os.path.abspath("orbax_checkpoint"),
<ipython-input-22-6b896aa2742d> in save_with_orbax(state, checkpoint_dir, epoch, accuracy)
13 )
14 # オプティマイザとモデルの状態を保存
---> 15 with ocp.CheckpointManager(checkpoint_dir, options=options) as mgr:
16 mgr.save(
17 epoch,
(中略)
/usr/local/lib/python3.10/dist-packages/orbax/checkpoint/type_handlers.py in get_cast_tspec_serialize(tspec, value, args)
691 }
692 # Origin dtype.
--> 693 tspec['dtype'] = jnp.dtype(value.dtype).name
694 # Destination dtype.
695 if args.dtype is None:
TypeError: Cannot interpret 'key<fry>' as a data type
Dropoutのような、ステップごとに新しい乱数を生成するために内部に乱数ジェネレータを保持しているレイヤーがモデルに含まれている場合このようなエラーが起きます。GitHubに立っているissue によると来年1月にはこの問題への対処がされるようですが、お急ぎの方のためにワークアラウンドを紹介します。
JAXには乱数のキーが2種類あり、ひとつは jax.random.PRNGKey 関数で生成される古い乱数キー、もうひとつは jax.random.key 関数で生成される新しい乱数キーです。NNXの乱数ジェネレータ nnx.Rngs は内部で新しい乱数キーを利用しているのですが、Orbaxが新しい乱数キーのシリアライズに対応していないために上記のようなエラーが起こります。
というわけで以下のような、モデル内の新しい乱数キーを古い乱数キーに変換する関数を用意します。
from jax.tree_util import DictKey, GetAttrKey, SequenceKey
StatePath = tuple[DictKey | GetAttrKey | SequenceKey, ...]
def is_rngs_key_path(path: StatePath) -> bool:
return (
len(path) >= 4
and isinstance(path[-4], DictKey) and path[-4].key == "rngs"
and isinstance(path[-2], DictKey) and path[-2].key == "key"
and isinstance(path[-1], GetAttrKey) and path[-1].name == "value"
)
def to_old_random_key(path: StatePath, value: jax.Array) -> jax.Array:
if (
is_rngs_key_path(path)
and jax.dtypes.issubdtype(value.dtype, jax.dtypes.prng_key)
):
return jax.random.key_data(value)
else:
return value
そして、上記の関数と jax.tree_util.tree_map_with_path を組み合わせて、オプティマイザとモデルの状態に含まれる乱数キーを変換すると無事に保存できます。
save_with_orbax(
jax.tree_util.tree_map_with_path(to_old_random_key, nnx.state(optimizer)),
os.path.abspath("orbax_checkpoint"),
hyperparams["num_epochs"],
metrics_history["test_accuracy"][-1]
)
モデルを保存したら、もちろん読み込みもしたいですよね。指定したディレクトリに保存されているモデルの中で最も正解率が高かったものを読み込む関数は以下のようになります。保存の関数は比較的シンプルでしたが、こちらは実装した私自身「ウッ・・・」となるような複雑さです。
def to_new_random_key(path: StatePath, value: jax.Array) -> jax.Array:
if (
is_rngs_key_path(path)
and not jax.dtypes.issubdtype(value.dtype, jax.dtypes.prng_key)
):
return jax.random.wrap_key_data(value)
else:
return value
def load_with_orbax(
checkpoint_dir: str,
optimizer_sekelton: nnx.Optimizer,
) -> tuple[nnx.Optimizer, int]:
sharding = jax.sharding.SingleDeviceSharding(jax.devices()[0])
# シャーディング(データの読み込み先)を指定する関数。
# GPUが利用可能ならGPUメモリに、そうでなければメインメモリに読み込む。
# 指定しない場合、Orbaxは保存時と同じシャーディングに読み込もうとするため、
# GPU環境で保存したモデルをCPU環境で読み込むとエラーが起きる。
def set_sharding(x: jax.ShapeDtypeStruct) -> jax.ShapeDtypeStruct:
x.sharding = sharding
return x
# モデルの比較方法を設定(正解率が高いモデルが良いモデル)
options = ocp.CheckpointManagerOptions(
best_fn=lambda metrics: metrics["accuracy"]
)
with ocp.CheckpointManager(checkpoint_dir, options=options) as mgr:
# 古い乱数キーを読み込めるように
(skeleton_graph, skeleton_state) = nnx.split(optimizer_sekelton)
skeleton_with_old_key = nnx.merge(
skeleton_graph,
jax.tree_util.tree_map_with_path(to_old_random_key, skeleton_state)
)
# 読み込むデータの構造(shapeとdtype)と読み込み先(sharding)を決定
abstract_model = nnx.eval_shape(lambda: skeleton_with_old_key)
(graph, abstract_state) = nnx.split(abstract_model)
abstract_state = jax.tree_util.tree_map(set_sharding, abstract_state)
# 一番正解率が高いエポック番号を取得
best_epoch = mgr.best_step()
# 古い乱数キーを含むデータを読み込み、乱数キーを新しいものに変換
state = mgr.restore(best_epoch, args=ocp.args.StandardRestore(abstract_state))
state_with_new_random_key = jax.tree_util.tree_map_with_path(to_new_random_key, state)
return (
nnx.merge(graph, state_with_new_random_key),
best_epoch
)
ちゃんと正解率が一番高いエポックのオプティマイザとモデルを読み込めるか確かめるために、全エポック分保存し直してみましょう。(オプティマイザもモデルも全エポックで同じですが、正解率の値は異なります)
import shutil
shutil.rmtree("orbax_checkpoint")
for epoch in range(1, hyperparams["num_epochs"] + 1):
save_with_orbax(
jax.tree_util.tree_map_with_path(to_old_random_key, nnx.state(optimizer)),
os.path.abspath("orbax_checkpoint"),
epoch,
metrics_history["test_accuracy"][epoch - 1]
)
そして、読み込みます。以下のように、学習済みのモデルを読み込むために学習前の状態のモデルを作る必要があるのがOrbaxの面倒なポイントです。
(loaded_optimizer, loaded_epoch) = load_with_orbax(
os.path.abspath("orbax_checkpoint"),
create_optimizer(
NNXModel(
num_classes=hyperparams["num_classes"],
dropout_rate=hyperparams["dropout_rate"],
rngs=nnx.Rngs(42)
),
hyperparams["learning_rate"],
hyperparams["weight_decay"]
)
)
print(f"ベストのエポック={loaded_epoch}")
ベストのエポック=24
それはそうと、正解率が一番高いエポックのオプティマイザとモデルが読み込まれているか、グラフをもう一度見て確認しましょう。ちゃんと上の「ベストのエポック」のところで test_acc が一番高くなっていますね。
show_graph(
hyperparams["num_epochs"],
metrics_history["train_loss"], metrics_history["test_loss"],
metrics_history["train_accuracy"], metrics_history["test_accuracy"]
)

PyTorchとの速度比較
JAX/Flaxはその速度も評判の理由の一つです。試しにPyTorchでも同様の画像分類モデルを学習してどの程度の時間がかかるか確認してみましょう。
まず、PyTorchのモデルのJITコンパイルに必要なライブラリであるtritonをインストールします。
%pip install -q triton
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 209.5/209.5 MB 6.5 MB/s eta 0:00:00
そして、以下のコードがこれまでLinenとNNXで実装してきたのと同様のCIFAR-10の画像分類の学習コードです
import torch
import torch.nn as tnn # Linenの `from flax import linen as nn` と衝突しないように
import torch.nn.functional as F
import torch.optim as optim
torch.manual_seed(42)
class PyTorchModel(tnn.Module):
def __init__(
self, num_classes: int, dropout_rate: float = 0.5,
) -> None:
super().__init__()
self.num_classes = num_classes
self.dropout_rate = dropout_rate
self.conv1 = tnn.Conv2d(in_channels=IMG_CHANNELS, out_channels=32, kernel_size=(3, 3))
self.bn1 = tnn.BatchNorm2d(num_features=32)
self.conv2 = tnn.Conv2d(in_channels=32, out_channels=64, kernel_size=(3, 3))
self.bn2 = tnn.BatchNorm2d(num_features=64)
self.linear1 = tnn.Linear(in_features=4096, out_features=128)
self.dropout = tnn.Dropout(self.dropout_rate)
self.linear2 = tnn.Linear(in_features=128, out_features=self.num_classes)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.conv1(x)
x = F.relu(x)
x = self.bn1(x)
x = F.max_pool2d(x, kernel_size=(2, 2), stride=(2, 2), padding=1)
x = self.conv2(x)
x = F.relu(x)
x = self.bn2(x)
x = F.max_pool2d(x, kernel_size=(2, 2), stride=(2, 2), padding=1)
x = x.reshape((x.shape[0], -1))
x = self.linear1(x)
x = F.relu(x)
x = self.dropout(x)
x = self.linear2(x)
return x
def train_step_pytorch(
model: PyTorchModel,
optimizer: optim.Optimizer,
criterion: tnn.Module,
batch: tuple[np.ndarray, np.ndarray],
device: str
) -> tuple[float, float]:
"""
学習ステップ
"""
images = torch.from_numpy(batch[0].transpose(0, 3, 1, 2)).to(device)
labels = torch.from_numpy(batch[1]).to(device)
optimizer.zero_grad()
logits = model(images)
loss = criterion(logits, labels)
loss.backward()
optimizer.step()
accuracy = compute_accuracy(
logits.detach().cpu().numpy(),
labels.detach().cpu().numpy()
)
return (loss.item(), accuracy.item())
@torch.no_grad()
def eval_step_pytorch(
model: PyTorchModel,
criterion: tnn.Module,
batch: tuple[np.ndarray, np.ndarray],
device: str
) -> tuple[float, float]:
"""
評価ステップ
"""
images = torch.from_numpy(batch[0].transpose(0, 3, 1, 2)).to(device)
labels = torch.from_numpy(batch[1]).to(device)
logits = model(images)
loss = criterion(logits, labels)
accuracy = compute_accuracy(
logits.detach().cpu().numpy(),
labels.detach().cpu().numpy()
)
return (loss.item(), accuracy.item())
def main_pytorch(
hyperparams: HyperParams,
*,
jit: bool
) -> tuple[PyTorchModel, list[float], list[float], list[float], list[float]]:
"""
PyTorchの画像分類モデルの学習を行う
"""
# データセットの取得
train_ds, test_ds = get_datasets(hyperparams["batch_size"])
# モデルとオプティマイザなどの初期化
device: str = "cuda" if torch.cuda.is_available() else "cpu"
model = PyTorchModel(
num_classes=hyperparams["num_classes"],
dropout_rate=hyperparams["dropout_rate"]
)
# JITコンパイル
if jit:
model = torch.compile(model)
model.to(device)
optimizer = optim.AdamW(
model.parameters(),
lr=hyperparams["learning_rate"],
weight_decay=hyperparams["weight_decay"]
)
criterion = tnn.CrossEntropyLoss()
# 学習ループ
train_losses: list[float] = []
test_losses: list[float] = []
train_accs: list[float] = []
test_accs: list[float] = []
for epoch in tqdm(range(1, hyperparams["num_epochs"] + 1)):
# 学習
train_loss = 0.0
train_acc = 0.0
num_train_batches = 0
model.train()
for batch in tfds.as_numpy(train_ds):
(loss, acc) = train_step_pytorch(model, optimizer, criterion, batch, device)
train_loss += loss
train_acc += acc
num_train_batches += 1
train_loss /= num_train_batches
train_acc /= num_train_batches
# 評価
test_loss = 0.0
test_acc = 0.0
num_test_batches = 0
model.eval()
for batch in tfds.as_numpy(test_ds):
(loss, acc) = eval_step_pytorch(model, criterion, batch, device)
test_loss += loss
test_acc += acc
num_test_batches += 1
test_loss /= num_test_batches
test_acc /= num_test_batches
train_losses.append(train_loss)
test_losses.append(test_loss)
train_accs.append(train_acc)
test_accs.append(test_acc)
return (model, train_losses, test_losses, train_accs, test_accs)
JITあり、JITなし、それぞれ2回ずつ計測しています。ちゃんと学習できているかの確認のため、最終エポックの test_acc も出力しています。
計測結果を見ると、JITありの1回目だけ際立って遅いです。どうやらモデルのJITコンパイルか、それに必要なモジュールの読み込みに時間がかかっていそうな感じです。それ以外は、Linenよりは少し遅く、NNXとはだいたい同じような時間になりました。やはり、この程度の複雑さのモデルでは大した差は付かないようです。
%%time
print("Start!")
torch_result_jit1 = main_pytorch(hyperparams, jit=True)
print(f"\nFinished! final test_accuracy={torch_result_jit1[-1][-1]}")
Start!
100%|██████████| 30/30 [03:19<00:00, 6.65s/it]
Finished! final test_accuracy=0.6665348101265823
CPU times: user 3min 35s, sys: 32.3 s, total: 4min 7s
Wall time: 3min 34s
%%time
print("Start!")
torch_result_jit2 = main_pytorch(hyperparams, jit=True)
print(f"\nFinished! final test_accuracy={torch_result_jit2[-1][-1]}")
Start!
100%|██████████| 30/30 [02:33<00:00, 5.10s/it]
Finished! final test_accuracy=0.663370253164557
CPU times: user 3min 8s, sys: 31.1 s, total: 3min 39s
Wall time: 2min 33s
%%time
print("Start!")
torch_result_nojit1 = main_pytorch(hyperparams, jit=False)
print(f"\nFinished! final test_accuracy={torch_result_nojit1[-1][-1]}")
Start!
100%|██████████| 30/30 [02:43<00:00, 5.46s/it]
Finished! final test_accuracy=0.6737539556962026
CPU times: user 3min 9s, sys: 30.5 s, total: 3min 39s
Wall time: 2min 44s
%%time
print("Start!")
torch_result_nojit2 = main_pytorch(hyperparams, jit=False)
print(f"\nFinished! final test_accuracy={torch_result_nojit2[-1][-1]}")
Start!
100%|██████████| 30/30 [02:51<00:00, 5.72s/it]
Finished! final test_accuracy=0.6950158227848101
CPU times: user 3min 11s, sys: 30.3 s, total: 3min 41s
Wall time: 2min 51s
まとめ
- この記事では、Flaxの新しいAPIであるNNXについて紹介しました。
- NNXは、従来の関数型のAPIであるLinenよりシンプルで取っつきやすいです。(特にPyTorchの経験者には)
- NNXのモデルの保存と読み込みについて、公式ドキュメントにも書かれていない便利機能やハマりポイントを紹介しました。
- 今回用いたモデルでは学習速度にあまり差は出なかったものの、あえて順位をつけるならLinenが最も速く、NNXとTorchは(Torchが依存しているTritonの読み込みにかかっていると思われる時間を除けば)だいたい同じくらいの時間で学習が終わりました
以上、かなりボリュームのある記事になりました。ここまで読んでいただきありがとうございます。
この記事を読んでFlaxに興味を持つ方がひとりでも増えたら嬉しいです。
付録
# 記事で使用したライブラリのバージョン一覧
import flax; print(f"{flax.__version__=}")
import jax; print(f"{jax.__version__=}")
import numpy; print(f"{numpy.__version__=}")
import optax; print(f"{optax.__version__=}")
import pandas; print(f"{pandas.__version__=}")
import plotly; print(f"{plotly.__version__=}")
import tensorflow; print(f"{tensorflow.__version__=}")
import tensorflow_datasets; print(f"{tensorflow_datasets.__version__=}")
import cloudpickle; print(f"{cloudpickle.__version__=}")
import orbax.checkpoint; print(f"{orbax.checkpoint.__version__=}")
import torch; print(f"{torch.__version__=}")
import triton; print(f"{triton.__version__=}")
flax.__version__='0.10.2'
jax.__version__='0.4.33'
numpy.__version__='1.26.4'
optax.__version__='0.2.4'
pandas.__version__='2.2.2'
plotly.__version__='5.24.1'
tensorflow.__version__='2.17.1'
tensorflow_datasets.__version__='4.9.7'
cloudpickle.__version__='3.1.0'
orbax.checkpoint.__version__='0.6.4'
torch.__version__='2.5.1+cu121'
triton.__version__='3.1.0'

Discussion