英語プレゼンターのトークをリアルタイムに日本語翻訳しプレゼンターのPC画面と並べて字幕表示するアプリを自作してしまった話
TechRAMEN 2025 に参加しました
2025年7月下旬に、北海道は旭川市で開催された "TechRAMEN" (テックラーメン) という、"技術好きのための円卓会議" と題した IT 技術系のカンファレンスイベントに参加してきました。
ちなみに TechRAMEN はこの 2025 年が第2回目の開催です。来年 2026 年は、富良野での開催を計画開始されたようです。来年も楽しみです!
で、この "TechRAMEN はいいぞー" という話もしたいところなのですが、今回はいったんそれは先送りします。代わりに今回は、この TechRAMEN 参加にあたって、表題のように、英語プレゼンターのトークをリアルタイムに日本語翻訳し、プレゼンターのPC画面と並べて字幕表示するアプリを、ちょっと紆余曲折ありまして結局自作することになり、当日運用することとなったので、その体験や経緯を共有してまいります。
ちなみに、この記事、めっちゃ長いです。
英語スピーカーが登壇するが翻訳どうするの件
TechRAMEN では毎年、登壇者の募集を行なっています。それで、私は、知人の Drew Robbins に「とても楽しいカンファレンスなので、せっかくだから、登壇者に募集してみたらどう?」と誘ってみました。そこで Drew はスピーカー募集に応募し、選考を通過しました。
ということで、Drew は TechRAMEN 2025 当日は登壇することになりました。
しかしひとつ心配なことが発生しました。実は Drew は基本、英語のネイティブスピーカーなのです。そしてまた、日本国内のローカルカンファレンスにおいて、参加者の多く (私も含まれます) に英語ネイティブのトークを聞き取っていただくことを、正直、お願いしにくいです (これはこれで1本、エモい記事が書けるテーマなんですが、それはさておき)。かといって、自分は同時通訳ができるほどの技量もありません。
幸い、現代は機械翻訳がずいぶんと優秀です。そこで、Drew のセッションでは、何らかのソフトウェア技術を駆使して Drew が英語でしゃべっている音声をテキスト化した上で日本語テキストに翻訳し、Drew の PC 画面上に字幕として合成して、最終的にプロジェクターに出力する、ということをやることを考えました。もう少し具体的には、以下の図のようなことを考えました。

ただし、Drew を誘ったのは自分である手前、TechRAMEN 運営に、そのような翻訳字幕システムの用意・運用を押しつけるのはできかねました。そこで TechRAMEN 運営に、この翻訳字幕システムの件は私に任せていただくよう事前に申し入れをし、ご快諾いただきました。
ということで、自分は翻訳字幕システムの用意をすることになりました。
最初のアイディア
この翻訳字幕システムの用意について、当初は自分はまぁまぁ楽観的に考えていました。いくつか思いつくところがあったのです。
ひとつは、ChatGPT や Microsoft Copilot などの AI エージェントの音声会話モードで、AI に逐次翻訳者になってもらう方法です。これは X 上のツイートで「へぇ、こういうこともできるのか」と知りました (下記リンク先を参照)。
このやり方は "翻訳字幕システム" とは違いますが、場合によってはこのような方法も悪くないかもしれない、と思案していました。
また、とあるオンラインイベントに Zoom で参加したとき、そのイベントでは "Cuckoo" というサービスを使って、英語や韓国語のディクテーション & 日本語テキストへの翻訳を行なっているのを見ていました。
その経験から、何となればこの Cuckoo を使えばそれで済むかな、とかも漠然と考えていました。
他にも Django Congress JP 2025 の YouTube 動画を視聴したときにも、同じように英語スピーカーのトークから日本語字幕を表示している様子が見えていました。あとでお聞きしたところ、こちらは岡野さん (@tokibito) が所属する ObotAI で開発している Minutz というサービスが利用されていたそうです。
なので、この Minutz を利用させてもらうことでも実現できそう、と思っておりました。
また、自分の PC は Windows なのですが、Windows には "Live Caption" というアプリが付属しており、このアプリは日本語や英語の音声を聞き取ってリアルタムで文字起こししてくれます。
そしてこの "Live Caption" が最近、同時翻訳にも対応したっぽい、との噂を聞いていました。なので、もしうまくいくのなら "Live Caption" アプリでもいいんじゃないかな、と考えました。
当日会場のインターネット接続が不安
このようにいろいろ選択肢もあるなぁ、と考えていたのですが、別の不安材料が気になり始めました。当日会場のインターネット接続の安定性と速度です。上記に挙げたアイディアはいずれも、"Live Caption" アプリを除き、インターネット接続に依存しています。
しかし TechRAMEN 運営からは Wi-Fi によるインターネット接続サービスの提供はありません。また、会場設備には Free Wi-Fi はあるようでしたが、そのようなカンファレンス向けではないでしょうから使う気になれません。
となると手持ちのスマホのモバイル回線を使ったテザリングだけが残された手段です。しかしこれも安心できません。というのも TechRAMEN 会場は旭川市街地中心からクルマで20分ほどの、周りに建物があまりないところなのです。

そこに 100人規模の、常にツイートしてたりラップトップ開いて Vibe Coding とかしてそうな、とにかくモバイル回線で常に何かしているような集団がいるわけです。しかも1人1デバイスとも限りません。そのような状況で、果たして基地局の通信容量がどの程度確保されているかもわからず、テザリングしても通信が詰まったりしないだろうか、心配になってしまいました。
つまり、Drew のセッション当日、インターネット接続の品質が悪くて、せっかくの翻訳字幕システムが満足に動作しないかもしれない、という不安に襲われました。
ちなみに、Windows の Live Capton はインターネット接続なしでも動作するようでした。また、噂の翻訳機能を試してみたところ、日本語を聞き取って英語へ翻訳してくれることが確認できました。動作中はしっかり NPU も使用している様子です。しかしなんということでしょう、日本語聞き取りから英語への翻訳はやってくれるのに、その逆、英語聞き取りから日本語への翻訳は、現在時点で未対応だというのです。なので、インターネット接続なしを想定した場合、Live Caption も救いの手にはなりません。
PC ローカルの AI モデルでやれないか?
このように当日会場のインターネット接続のことが心配になった自分は、インターネット上のサービスに頼らず、自分のラップトップ PC 上だけで動作する翻訳字幕システムを構築できないか考え始めました。自分のラップトップの仕様は以下のとおりで、しょぼいかもですが一応 GPU を積んでいますし、NPU も持っています。
- CPU & NPU - AMD Ryzen AI 9 HX 370
- GPU - NVIDIA GeForce RTX 4060 / 6 GB VRAM
このハードウェアを活かして、なんとか PC ローカルの AI モデルだけで動く翻訳字幕システムを構築できないか、まずは ChatGPT の Web 検索オプションを On にして、既存のソリューションを探してみました。しかし今回の要件にマッチするものは見つからないか、あっても個人利用のレベルでは高価過ぎるものしか見つけることができませんでした。
そこで、ないのなら作ってみるかー、と自作に挑戦することにしたのです。ただし、後でも述べますが、自分にはこの分野の知識・経験がまったくありませんでした。ですが昨今は ChatGPT や Gemini、Claude といった AI がかなり強力に支援してくれます。なので、実はイケるんじゃね? とか思ってた次第です。
しかし、結果を先に言っておくと、この試みは実質失敗に終わります (!)。 しかしながらこれが、翻訳字幕システムを自作するに至った経緯・背景事情なのでした。
ちなみに、私的な諸事情により、この判断を下した時点で TechRAMEN 当日まであと10日、という状況でした。
C# / Blazor Server を採用
翻訳字幕システムを自作するにあたって、時間もさほど残されていなかったので、自分の得意な C# および Blazor Server を使って構築することにしました。つまり UI は Web ブラウザ上で動作することになります。
結果としてはこれは悪くない選択だったと思っています。Blazor Server は突き詰めて言えば PC 上で稼働するただの .NET コンソールアプリです。そのため、PC 上のすべての資源に何も考えずとも普通にアクセスできます。なので、PC ローカルで稼働する AI モデルとの統合も、特になにも考えずに素で組み上げるだけで実現できてしまいます。また、ローカルの AI モデルとのやりとりの結果を Web ページ上に反映する必要がありますが、これまた Blazor Server の黒魔術によって、単純にコンポーネントのステートに反映するだけで、サーバー側での状態変更が Web ページ上に即時反映されます。裏では Blazor Server のランタイムが WebSocket でごにょごにょしてるわけですが、ソースコード上は簡潔に「やりたいこと」が宣言的に記述されるだけです。自前で「クライアント側とサーバー側を WebSocket とか SSE で結んで~」みたいなことを書く必要がありませんので、時間が押している中、この種の実装を書く手間が不要なのは助かりました。
もちろん、他の言語やプラットフォーム、フレームワーク等でも、ぜんぜん実現できたと思いますし、それぞれに良いところがあると思います。ただ、今回の件で自分の得意な技術選定でも、幸いにして悪くない選択だった、ということです。
プレゼンターの PC 画面を中継する
さて次に、プレゼンターの PC 画面と翻訳字幕とを並べて表示するために、プレゼンターの PC 画面をキャプチャすることにします。これには、USB で接続して使う市販の HDMI キャプチャデバイスを使いました。このキャプチャデバイスは、これを刺している PC からはカメラデバイスとして認識される仕組みです。その昔に Amazon で購入したのですが、同型機は生産販売を終了しているようでした。とはいえ、この種のデバイスは様々なメーカーから販売されていますので、今でも入手に困ることはないでしょう。いま検索したところ、下記サイトに私が購入したのと同じデバイスの写真がありましたのでリンクを貼っておきます。
ということで、この HDMI キャプチャデバイス = カメラデバイスからの入力を Web ページ上に映せば、プレゼンター PC 画面の中継が実現できます。これはブラウザの Media Capture and Stream API と <video> 要素を使えば容易に実現できます。
実はこの部分は C#/Blazor ネイティブでは実装できず、JavaScript で実装する必要があります。とはいえ、実際のコーディング作業は GitHub Copilot にお願いして済ませることができ、労せずして実装完了しました。
AI Dev Gallery アプリが親切
続けて、英語音声の聞き取りと日本語テキストへの翻訳を実現していく必要があります。
しかし実際のところ、私自身はこの分野においてまったくの素人・初心者です。実のところ各種 AI モデルを PC ローカル上で動かす方法もまったく未知の領域でした。そこで、ChatGPT に聞きながら、行き当たりばったりで、手探りで実現方法を探っていくことになりました。
ChatGPT が言うには、この種の課題解決については Open AI の Whisper という音声認識モデルを使うのが鉄板である、ということがわかりました。また、前述のとおり今回の一件で使用するプラットフォーム = 自分の PC は Windows なのですが (全く関係ない話ですが Drew のラップトップは Mac です)、これには "AI Dev Gallery (Preview)" というアプリが Microsoft から提供されており (下記リンク先)、これを使うと気軽に各種 AI モデルを試せるよ、ということも教えてもらいました。
前述のとおり、自分はこの分野はまったくの素人であるので、まずはこの AI Dev Gallery をインストールするところから始めました。そうしたところ、この AI Dev Gallery は大変便利で、このアプリの GUI 上にサポートされている代表的な AI モデルが一覧表示され、
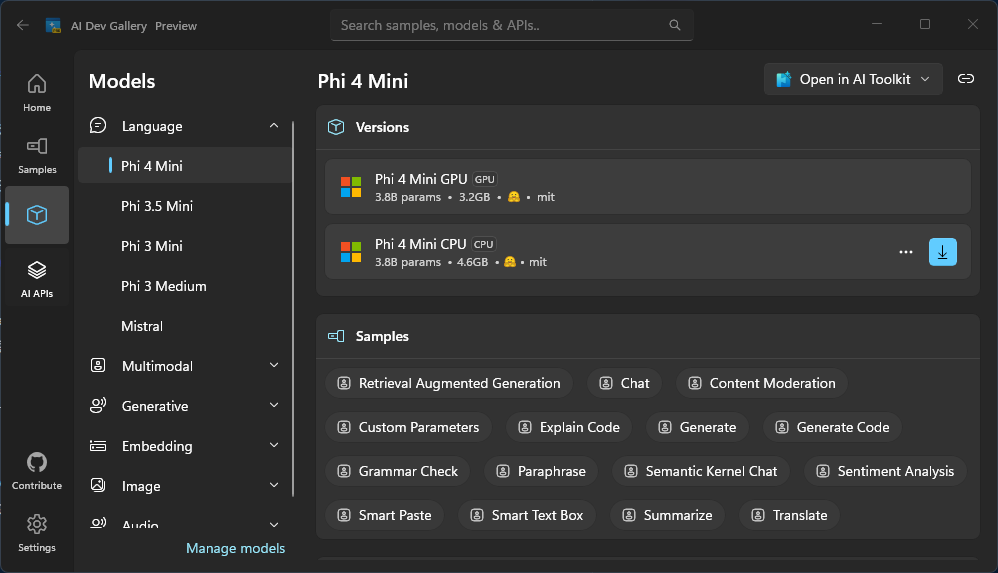
それを選べば PC 上にダウンロードされ、さらにテキストチャットや翻訳といった動作を AI Dev Gallery アプリ内で試すことができることがわかりました。

さらにそれらサンプル動作は、C#/.NET のデスクトップアプリケーション用のソースコード (使用されているフレームワークは WPF) としてエクスポート可能なのでした。
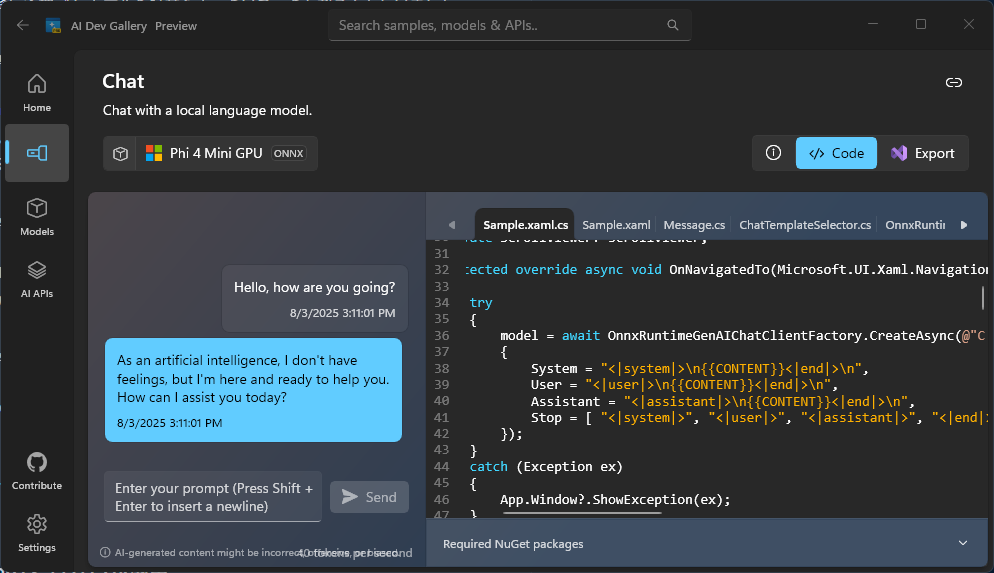
前述のとおり、翻訳字幕システムは C#/Blazor で構築することとしたため、AI Dev Gallery アプリからエクスポートされたソースコードをよしなにコピペするだけで、翻訳字幕システムにそれらローカルの各種 AI モデルを使ったコードを実装することができました。
Whisper が... 動かなくはないが激重
そして、音声認識モデルである Whisper も、AI Dev Gallery アプリ上に掲載されていました。

ということでモデルをダウンロードするところから試してみることにしたのですが、しかしどうも、CPU モデルしか掲載されていない ようなのです。他の Phi4 などのモデルでは NVIDIA の GPU を使って動作する CUDA 対応のモデルが選べたのですが、Whisper にはそれが見当たらないのです。嫌な予感がしつつ、とりあえず CPU 対応の Whisper Medium モデル (1.3 GB) をダウンロードし、AI Dev Gallery アプリ上で音声認識の動作を試してみました。
そうしたところ、CPU ファンが唸りをあげて回りだし、タスクマネージャーで見たところ CPU クロックが 4 GHz を超えたまま、一部コアの使用率が天辺に貼り付いたままとなりました。そして音声認識の処理速度も遅く、ぜんぜんリアルタイムっていう感じにはなりませんでした。
Mdeium モデルは大きすぎたか、とあきらめて、Whisper Tiny モデル (73.8 MB) に切り替えましたが、これでも CPU 使用率は依然高く、また、やはりモデルが小さすぎるのか、音声認識の精度が非実用レベルまで悪化しました。
自分はここで詰んでしまいました。
自分に技量があれば、Whisper の GPU 対応モデルを探し出すとか変換するとかして用意し、より実用レベルで実行することができたかもしれません。何なら、AMD の NPU で動かすこともできたりするのでしょうか。しかし繰り返しになりますが、自分はこの技術領域においてまったくの初心者であり、手も足も出ませんでした。ChatGPT に泣きついて見るも、ChatGPT の回答内容を理解できないほどに自分の前提知識が不足していることも多く、また、ChatGPT のいうとおりに各種ツール類をインストールして試して見るもどうも結果がおかしく、さりとて ChatGPT の回答が果たしてどこまで本当のことを言っているのかの判断もできない、という状況でした。Python を使ったソリューションがいくつか返ってきましたが、自分は Python も素人です。もっと落ち着いて学習を重ね、時間をかけて一歩ずつ知識レベルを上げていけばどうにかなったのかもしれません。しかし TechRAMEN 当日まで残り 7 日と迫っており完全にテンパってしまっていました。
音声認識は Vosk で
Windows に搭載されている音声認識はどうか
そこで Whisper の使用はあきらめ、他の音声認識モデルを ChatGPT に探してもらいました。しかし Whisper 一強なのかどうなのか、これといったソリューションが見つかりません。
いっぽう、Windows には OS 自体に音声認識機能とその API が備わっています。これを利用できないか試してみましたが、古くからある API は認識精度が著しく低く (音声で単純なコマンドを発話したら反応する、といった程度でしか実用にならない)、
また、新世代の API はインターネット接続が必須で (どこかのサーバーで処理するらしい)、今回の目的であるオフライン動作の要件を満たしませんでした。
Web ブラウザが提供する音声認識 API
Chromium 系の Web ブラウザが備える Speech Recognition API も同様で、これは精度は悪くはないものの、これまた実際の処理はインターネット上のどこかで行なわれるらしく、インターネット接続必須でした (そもそも今日現在でも "Experimental" としてマークされている API なのですが)。
Vosk を知る
そこで改めて ChatGPT に、インターネット接続なしで動作する音声認識ソリューションが他にないか探してもらったところ、Vosk という音声認識ライブラリ を教えてもらいました。
.NET 用のバインディングも NuGet パッケージとして配布されており、C# / Blazor 製の翻訳字幕システムへの組み込みも問題なさそうです。
試しに翻訳字幕システムに組み込んでみたところ、期待どおり労せずして実装することができました。モデルをいくつかダウンロードして動作確認したところ、CPU 使用率は低く抑えられたまま、まずまずの精度、かつ、じゅうぶんなリアルタイム性能で音声認識ができることを確認できました。
128 MB の軽量モデルを採用
最終的に選んだモデルは、たかだか 128 MB の "vosk-model-en-us-0.22-lgraph" です。当初は 2.3 GB ある "vosk-model-en-us-0.42-gigaspeech"、あるいはせめて 1.8 GB の "vosk-model-en-us-0.22" でないと実用レベルの精度が出せないんじゃないか、と思っていました。しかし実際のところは、自分が試した範囲では、128 MB の "vosk-model-en-us-0.22-lgraph" で十二分な精度、むしろ CPU 使用率が低く反応も速い、といった感触でした。モデルのサイズが小さくてもなかなかの高性能を出せるのは不思議です。
ということで、英語話者の音声を英語テキストにリアルタイムで文字起こしする部分は、Vosk + vosk-model-en-us-0.22-lgraph (128 MB) で実装しました。
翻訳は AI モデルで... しかし精度が
Phi 4 Mini が動いたが翻訳精度がイマイチ
音声の英語テキスト化まで実現できましたので、残るは日本語テキストへの翻訳です。ということで再び AI Dev Gallery アプリを使って試してみました。AI Dev Gallery アプリに標準で掲載されているモデルで色々試した結果、Phi 4 Mini というモデルが一番翻訳の精度が高そうでした。しかし Phi 4 Mini がこれらモデルのなかで一番精度が高い、と言っても、絶対的な翻訳精度としてはかなり物足りない結果となりました。ぶっちゃけ、 何言っているかわからん、 みたいな翻訳結果がたびたび出力されるのです。
Mini じゃない Phi 4 は自分の PC では重過ぎ
やっぱり "Mini" なのがいけないのかなー、と思い、他のモデルは試せないのか見ていたところ、AI Dev Gallery アプリでは、Azure Foundry Local という、Microsoft が出している別のローカル AI モデルツールと統合して動作することができ、この Foundry Local を使えば、さらに試せるモデルが増えることがわかりました。
早速、示された手順に従って PC に Azure Foundry Local をインストールし、Foundry Local 経由で利用可能なモデルを確認したところ、Mini じゃない Phi 4 (8.37 GB) が選べることがわかりました。
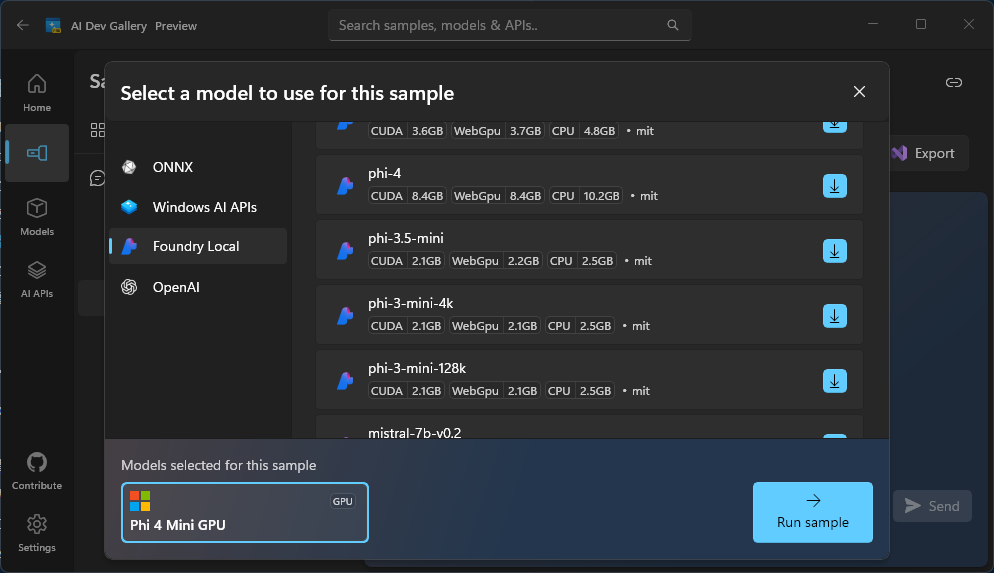
ということで Mini ではない Phi 4 を試してみました。しかし今度は PC のハードウェア性能が不足し、翻訳速度が遅く使い物になりませんでした。
DeepSeek と Qwen - 翻訳結果が安定しない
他に試行錯誤した中では DeepSeek R1 の 7B のモデル (Instruct, CUDA, 5.278 GB) と、Qwen 2.5 の 7B のモデル (Instruct, CUDA, 4.73 GB) が、自分のラップトップでもじゅうぶんな速度で翻訳処理を行なうことができ、かつ、精度も Phi 4 よりもマシに見えました。しかしこれらモデルは、ちょくちょくと「翻訳しますね!」みたいな、翻訳結果そのもの以外の AI 自身の一人称の内容を出力してしまうことや、翻訳結果が中国語になってしまうことがありました。いちおうは、"instruct" モデルであるにもかかわらず、です。システムプロンプトにて、翻訳結果以外は一切出力しないよう、また、翻訳は日本語に限定するようきつく指定しても改善が見られませんでした。さらに ChatGPT にこれらモデルに対する効果的なシステムプロンプトを作ってもらい試しましたが、効果は見られませんでした。
結局 Phi 4 Mini... なんだけど、これでいいのか?
DeepSeek R1 7B および Qwen 2.5 7 B が、Phi 4 Mini よりも "読める" 翻訳結果を出してくれても、翻訳結果がたまに中国語になってしまうのはさすがに許容できません。結局 Phi 4 Mini しか現実的に採用できないと判断されました。
そこで Phi 4 Mini を採用した翻訳字幕システムをいったん実装しきりました。下図はとある YouTube 動画を入力として、こうして作りきった翻訳字幕システムの動作確認を行なっている様子です。
ということで、翻訳字幕システムはどうにか形にはなりました。
しかし先に書いたとおり、その後の動作確認を経ても、Phi 4 Mini による翻訳結果はかなり微妙です。ないよりはマシなのですが、せっかく Drew のセッションに参加してくれた人たちに、この翻訳精度でお届けするのは申し訳ない気持ちでいっぱい です。
さりとて、この自分のラップトップのハードウェア性能では、インターネット上のサービスとして提供されている生成 AI の翻訳精度と比べると、このあたりが限界、圧倒的に低い精度しか出力できなさそうであることもわかってきました。VRAM をもっとたらふく積んだ高性能の GPU が当日会場で使えたら、また違ってくるのかもしれませんが。
インターネット接続前提に舵を切り直す... も時間がない!
そこで、当初の方針を 180° 翻し、インターネット接続を前提として、インターネット上のサービス利用を採用することにしました。当日会場でのモバイル回線のテザリングが不安だとは言いましたが、まったく使えないと決まったわけではありません。Drew のセッション中、テザリングがじゅうぶんな品質で稼働継続してくれることに賭け、代わりに、ローカル PC だけでは実現できなかった翻訳精度を手に入れることにしたのです。ここまでに作り上げた Vosk + Phi 4 Mini による翻訳字幕システムの実装は、万が一、当日会場でテザリングが機能しなかった場合に備え、引き続きバックアップとして残しておくことにしました。
また、事前の TechRAMEN 運営からの情報で、会場のある地域は au は電波の掴みが悪いかも、と聞いておりました。しかし逆にその情報によって docomo ユーザーが多くて逼迫したらどうしよう、とも思い、docomo と au の2回線を準備して、どちらの回線でも選んでテザリングできる体制を用意しました。加えて Wi-Fi でのテザリングですら警戒し、スマホとラップトップとを USB ケーブルで接続しての有線接続でのテザリングとすることにしました。
しかし TechRAMEN 当日までこの時点で残り 5 日。
この技術領域の素人である自分が、今から何らかの翻訳サービスを選定・採用し、翻訳字幕システムとして統合できるのか、正直、かなり焦りました。Google 翻訳を Web 上で使うことはよくあったので、当初は、Google 翻訳の API を使わせてもらおうかと考えました。Google 翻訳は精度も高いですし、反応速度も速いので最適では、と思ったのです。しかし運の悪い (?) ことに、自分は Google 系のサービス利用にもこれまた疎く、Google のクラウドサービスに急ぎサインアップして (そう、アカウントもなかったのです...!) ヘルプドキュメントを読むも、気が焦るばかりで、どうやれば Google の翻訳 API を利用できるのか理解もおぼつかない状況でした。
Google 翻訳 API の利用ですらこんな調子だったので、当初考えていた Cuckoo や Minutz などの既存ソリューションの利用も、今からでは、まったくもって実現できる気がしなくなっていました。
そのような状況化、藁にもすがる思いで、改めて ChatGPT に、何らか他のソリューションがないか聞いてみました。
Azure AI Speech があるじゃないか
すると ChatGPT から、「Azure AI Speech サービスなら使えるんじゃないの?」との回答が。
なるほど、そうでした。
自分は Microsoft Azure なら、Azure App Services 上で Web サーバーを運用する程度にはそこそこ使い慣れてますし、課金体制も整っています。いままで自分で思いつかなかったことが恥ずかしいくらいです。
そこで急いで Azure AI Speech サービスについて調べ始めたところ、Azure AI Speech の .NET 用 SDK を使えば、オーディオ入力デバイスからの音声入力から、翻訳結果のテキスト返却まで、ワンストップで実装できてしまうんですね。UI を含めて完成された SaaS というのではなく、機能を提供する SDK、API という体裁なので、自作アプリへの組み込みも容易そうです。
ということで、下記の公式ヘルプドキュメントに従って必要な NuGet パッケージを追加し、掲載されているサンプルコードをコピペしながら進めてみたところ、あれよあれよという間に、実装を完成させることができました!
TechRAMEN 当日まで残り 3 日で、ようやく、翻訳字幕システムのインターネット接続前提バージョンが完成となりました。Drew のセッションは 40 分枠なので、実際にスマホの USB 有線接続テザリングを使っての 60 分程の連続稼働のリハーサルを済ませ、必要な機材やケーブル類をパッキングして旭川に向けて出発、当日に臨みました。
そしてセッション本番
そうして迎えた TechRAMEN 当日、Drew のセッション本番。
直前のセッション終了後の入れ替えの短い時間で機材の配線をあわただしく済ませ、ドキドキしながら Azure AI Speech Service 版の翻訳字幕システムを起動し、Drew にマイクに向かって何かしゃべってもらって試運転したところ、無事、期待どおりに Azure AI Speech サービスからスマホのテザリング越しに翻訳結果が返ってきました!
そうして Drew のセッションが開始。
以後 40 分のセッション中、自作の翻訳字幕システムは無事完走したのでした。
振り返って
翻訳精度はギリ及第点?
実のところ、Drew のセッションに参加された方々からの感想・評価をお聞きしていないので実際のところはわからないのですが、自分の感触では、翻訳の精度はギリギリ及第点だったかなぁ、と見ています。素晴らしい翻訳精度という気もしませんが、Drew のセッション内容を概ね把握できる程度には役立ったのではないだろうか、という自己評価です。
TechRAENN 本祭終了後、懇親会に向かうバスで岡野さんとお話する機会があり、「Whisper を VRAM 6 GB のラップトップの GPU で回すのはちょっと無理があるよねー」「やっぱりそうなんですかー」みたいな会話をしたりしていました。そこで岡野さんからお聞きした感じですと、Azure AI Speech サービスも悪くはないのですが、このような用途に特化したリアルタイムのディクテーション & 翻訳ソリューションのほうが、より高い精度での日本語翻訳を提供できた可能性が高く、その意味では、今回 Drew の英語セッションにご参加された皆さんにはお詫び申し上げます。
将来また似たような境遇におかれる機会があれば、翻訳字幕システムの自作にこだわらず、既存の完成度の高いソリューションの選定と利用を前提に、しっかり時間を確保して取り組みたいところです。
Azure AI Speech サービスの利用料金は?
今回、Azure AI Speech サービスは、従量課金で利用しました。気になるお値段 (?) ですが、TechRAMEN 本番当日の利用料金は ¥243 でした。その他にも開発中の動作確認時や、事前のリハーサルなどでも稼働させているので、総コストはもう少しかかっていますが、それでもセッション当日を含む全額で ¥500 くらいで済んでいます。なお、私個人のとある特殊な事情で、ある種のスポンサーみたいなのが付いていたため、実際には私からは、今回は1円も支払いが発生せずに済んでおります。
もうひとつの立役者 - ピンマイク
今回の翻訳字幕システムの稼働にあたり、もうひとつ、重要なデバイスがありました。ピンマイクです。使用した製品は NearStream 製の AWM20T という製品です。
いわゆるピンマイクというよりは、クリップオンマイクといった体の製品ですが、これを Drew のシャツに取り付けてもらい、彼の英語音声をこれで拾って、翻訳字幕システム (Azure AI Speech サービス) 入力していたのでした。ワイヤレスなので Drew の動きを妨げることもありません。ワイヤレス特有の遅延がほんの僅かあるのですが、今回は翻訳字幕システムへの入力ですので、実質問題になりませんでした。とにかく、このクリップ型のワイヤレスマイクのおかげで、Drew のトーク音声を安定して高品質に拾うことができました。
おまけ - 翻訳字幕システムを自作するにあたってこだわったところ
結局は PC ローカルだけでのオフライン動作を断念したため、翻訳字幕システムを自作する必要性はほぼなくなってしまっていましたが、時間の都合で、自作の方針のまま走り抜けることとなってしまった訳であります。
しかしながら、せっかく (?) 自作でやりきるとした以上、一点だけこだわったところがありました。
それは逐次の翻訳結果の出現を、しっかりアニメーション表示するようにしたところです。
音声認識されて返ってきた翻訳結果テキストを、何も考えずに (?) 表示エリアにただ追加してしまうと、既存の前回までの翻訳結果テキストが、ガクッと下にスクロールします。これだと、まだその前回翻訳テキストを目で追っていたときに、読んでいた箇所を見失いがちで非常にストレスです。とくに翻訳字幕システムの字幕領域の幅が狭いこともあって (主画面は、プレゼンターの PC 画面ですから)、翻訳結果テキストが折り返した複数行ぶんで挿入されることも多く、この "いきなりのジャンプ" に拍車をかけます。
そこで今回の自作実装では、新たな翻訳結果テキストが発生したときは、にゅーっと滑り込むようにそのテキスト要素を出現させるようにし、既存の翻訳結果テキスト要素はそれにあわせて下にスムーススクロールしていくようにしました。このようにすることで、視線はスムーススクロールについていくことができ、それまで読んでいた箇所を見失うことがなくなったのではないか、と思います。実をいうと、まだ改善の余地があるのですが (確定するまで翻訳結果が変動・増減し、上下に "暴れる" ことがあるので、これをどうにか抑止したかった)、とにかくここまで実装することで、"翻訳結果の読みやすさ" に貢献できたのではないか、と考えております。
また、Zoom や Microsoft Teams などを使ったオンライン登壇とは異なり、聴衆がいる前でプロジェクタでスクリーンに映して行なうセッションですので、スクリーンの下の方は聴衆の皆さんには見にくいはず、と考え、新しい翻訳結果テキストは上に挿入し、既存の翻訳結果テキスト要素は下方にスクロールアウトしていくレイアウトとしたことも、小さなことながら、こだわりポイントです。
おわりに
大変長々と書き連ねましたが、以上が、Drew の英語セッションで使用した、翻訳字幕システムの舞台裏でした。改めて、必ずしも最善の翻訳字幕システムを提供できたとは限らない点 (Azure AI Speech もそこそこいいと思うんですけど、Minutz を利用したほうがよりよい体験を提供できたかもしれない可能性)、Drew のセッションに参加された各位にお詫び申し上げます。
それでもなお、何も支援のない状態よりも、幾ばくかでも皆さんのセッション理解の一助になっていれば、少しは報われる気がします。
何はともあれ、"技術好きのための円卓会議"、TechRAMEN への参加、おつかれさまでした。また来年お会いできることを願っております。
Discussion