Pythonで学ぶクリーンアーキテクチャ入門
はじめに
リーディング・エッジ社で、エンジニアをしている和泉と申します。
今回はクリーンアークテクチャについて記事を書きたいと思います。
ソースコードは、以下のGitHubリポジトリに保存しておりますのでご確認頂ければと思います。
さて、クリーンアーテクチャと聞いてどのようなイメージを持ちますでしょうか?
よく使われる図として以下があるかと思います。
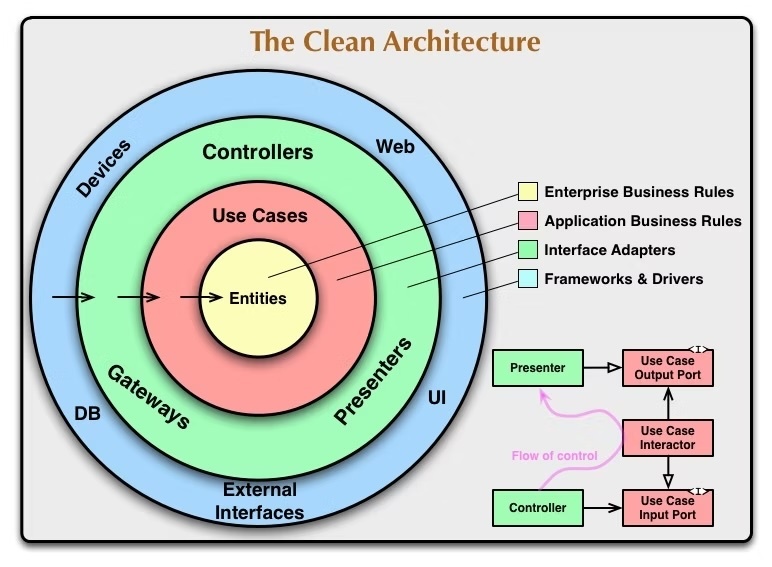
クリーンアーキテクチャの一番重要なポイントは、以下だと私は考えております。
- 各種クラスの依存関係を明確に分けて配置すること。
- 依存関係が逆転する場合は、インターフェースを利用すること。
上記を守って開発した場合、以下のような恩恵を得ることが可能になります。
- 修正する箇所を特定しやすくなる。
- 一つ一つのソースが短くなる傾向が高いため、理解しやすくなる。
- 新しい機能を追加する際に、影響範囲が極力少なくて済む。
- ビジネスロジック(図の場合は、EntitiesやUseCases)に近いレイヤーになるほど修正が必要なくなる設計になる。
- 一方、フレームワークに依存した部分やDBなど更新の頻度が高い部分が、ビジネスロジックと切り離されるため、フレームワークの変更やDBの変更がビジネスロジックに影響を及さない設計になる。
ただし、クリーンアーキテクチャを採用する際のデメリットも存在するのも事実です。
例えば、ソースコードが煩雑になり、ファイル数がMVCモデルなどと比較して多くなる傾向になります。
そのため、スタートアップの初期フェーズなどでスピードを重視する際には、開発スピードが落ちる傾向があります。
とはいえ、ある程度サービスが成熟して、開発エンジニアが増えてきた場合には、ソースコードの保守性が高くなるため導入するためのメリットが大きくなると考えられます。
本記事では、クリーンアーキテクチャに初めて触れる方を対象に、以下のGitHubリポジトリをベースに解説します。
本記事を読むことで、Pythonを使ったクリーンアーキテクチャの基本構造を理解し、実際のプロジェクトに適用する方法が分かります。
クリーンアーキテクチャとは?
クリーンアーキテクチャは、Robert C. Martin(通称 Uncle Bob)によって提唱されたソフトウェア設計の原則です。システムの依存関係を内側から外側へと流れるように整理することで、柔軟で保守性の高い構造を実現します。
特徴
- 依存関係の方向性:外側の層が内側の層に依存し、逆はない。
- ビジネスロジックの独立性:フレームワークやデータベースの影響を受けない。
- テスト容易性:ビジネスロジックのテストがしやすい。
主要なレイヤー
クリーンアーキテクチャは、以下の4つのレイヤーで構成されます。
- エンティティ(Entities):ビジネスルールやドメインモデル。
- ユースケース(Use Cases):アプリケーションのビジネスロジック。
- インターフェース(Interfaces):プレゼンテーション層、コントローラなど。
- フレームワーク(Frameworks):Webフレームワーク、データベースなど。
GitHubリポジトリの構成
ディレクトリ構成は以下のようになっています。
今回のプログラムは、
.
├── src
│ ├── training_data
│ ├── models
│ ├── modules
│ │ ├── interface_adapter
│ │ ├── repositories
│ │ ├── application
│ │ ├── domain
│ └── pages
├── requirements.txt
├── Dockerfile
└── README.md
各ディレクトリの役割とソースコード
modules/domain/ - ビジネスルールやエンティティの定義
アプリケーションを作るために一番重要なビジネスロジックに関するクラスが記載されています。
上位レイヤーのクラス(特にユースケース層)は、これらのクラスを利用してアプリケーションを構築して行きます。
import pickle
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from src.modules.domain.training_data import TrainingData
from src.modules.domain.training_result import TrainingResult
class TrainingService:
def __init__(self, pipeline: Pipeline, model_path: str):
self._pipeline = pipeline
self._model_path = model_path
def train(self, train_data: TrainingData) -> TrainingResult:
'''学習を実行する'''
X_train, X_test, y_train, y_test = train_test_split(train_data.get_features(),
train_data.get_target(),
test_size=0.2,
random_state=1)
self._pipeline.fit(X_train, y_train)
return TrainingResult(y_test, self._pipeline.predict(X_test))
def save_model(self) -> None:
'''モデルを保存する'''
with open(self._model_path, 'wb') as f:
pickle.dump(self._pipeline, f)
# training_data.py
import pandas as pd
class TrainingData:
def __init__(
self,
df: pd.DataFrame,
feature_cols: list,
target_col: str
):
self._features = df.loc[:, feature_cols]
self._target = df.loc[:, target_col]
def get_features(self) -> pd.DataFrame:
'''特徴量を取得する'''
return self._features
def get_target(self) -> pd.Series:
'''目的変数を取得する'''
return self._target
# training_result.py
from typing import Dict
from numpy import ndarray
from sklearn.metrics import f1_score, accuracy_score, precision_score, recall_score
class TrainingResult:
def __init__(self, true_y: ndarray, pred_y: ndarray):
self.true_y = true_y
self.pred_y = pred_y
def get_metrics(self) -> Dict[str, float]:
return {
'accuracy': accuracy_score(self.true_y, self.pred_y),
'precision': precision_score(self.true_y, self.pred_y, average='macro'),
'recall': recall_score(self.true_y, self.pred_y, average='macro'),
'f1': f1_score(self.true_y, self.pred_y, average='macro')
}
modules/application/ - ユースケースの実装
UsecaseのインターフェースであるUsecaseクラスです。こちらのクラスを継承したクラスを実体のクラスとして利用します。
# training_usecase.py
from src.modules.domain.training_result import TrainingResult
class TrainingUsecase:
def execute(self) -> TrainingResult:
'''学習を実行する'''
raise NotImplementedError
実際の実体のクラスが以下になります。
具体的には、ドメイン層で作成した各種クラスやインターフェースを利用して、ビジネスロジックを実行していきます。
# training_interactor.py
from src.modules.domain.training_data_repository_interface import TrainingDataRepositoryInterface
from src.modules.domain.training_result import TrainingResult
from src.modules.domain.training_service import TrainingService
from src.modules.application.training_usecase import TrainingUsecase
class TrainingInteractor(TrainingUsecase):
def __init__(
self,
training_data_repository: TrainingDataRepositoryInterface,
training_service: TrainingService
):
self._training_data_repository = training_data_repository
self._training_service = training_service
def execute(self) -> TrainingResult:
train_data = self._training_data_repository.load_data()
training_result = self._training_service.train(train_data)
self._training_service.save_model()
return training_result
modules/interface_adapter/ - インターフェース層(コントローラ)
# training_controller.py
from src.modules.application.training_usecase import TrainingUsecase
from src.modules.domain.training_result import TrainingResult
class TrainingController:
def __init__(self, training_usecase: TrainingUsecase):
self._training_usecase = training_usecase
def handle(self) -> TrainingResult:
'''学習を実行する'''
return self._training_usecase.execute()
コントローラークラスは、ユースケース層のクラスのインターフェースであるUsecaseクラスを利用して処理を実行しています。
したがって、Usecaseクラスの実体のクラスの中身が分かっていなくても利用することができる設計になっています。
そのため、実体のクラスを様々に変更することが可能になっています。
今まで、説明してきたクラスを利用する際ですが、基本的には、DI(Dependency Injection)を利用して、外部から各種クラスを用いたインスタンスを渡していくのが主流になっています。
pythonにもDIを実行するための以下の専用のライブラリが存在しています。
- injector
- python-dependency-injector
しかし、今回は分かりやすく、Controllerクラスを作成する際に各種インスタンスを生成し渡す方法を行っています。
import os
from typing import List
import streamlit as st
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from src.modules.interface_adapter.training_controller import TrainingController
from src.modules.application.training_interactor import TrainingInteractor
from src.modules.domain.training_service import TrainingService
from src.modules.repositories.file_train_data_repository import FileTrainDataRepository
def build_controller(
input_file_path: str,
feature_cols: List[str],
target_col: str,
model_path: str
) -> TrainingController:
'''TrainingControllerを作成する'''
# データの読み込み
training_data_repository = FileTrainDataRepository(
file_path=input_file_path,
feature_cols=feature_cols,
target_col=target_col
)
pipeline = Pipeline([
('scaler', StandardScaler()),
('model', GradientBoostingClassifier())
])
training_service = TrainingService(pipeline, model_path)
training_interactor = TrainingInteractor(training_data_repository, training_service)
return TrainingController(training_interactor)
st.header('モデルの作成')
# モデルファイル名の入力フォーム
with st.form('train_model'):
file_name = st.text_input('保存するファイル名')
submit_button = st.form_submit_button(label='train')
# モデルの学習と保存
if submit_button:
controller = build_controller(
input_file_path=os.path.join(
os.path.dirname(os.path.dirname(__file__)),
'training_data',
'iris_dataset.csv'
),
feature_cols=['sepal_length', 'sepal_width', 'petal_length', 'petal_width'],
target_col=['target'],
model_path=os.path.join(
os.path.dirname(os.path.dirname(__file__)),
'models',
file_name
)
)
result = controller.handle()
matrix = result.get_metrics()
st.write('model training is completed')
st.write(f'model is saved as {file_name}')
st.write('f1 score:', matrix['f1'])
st.write('accuracy:', matrix['accuracy'])
st.write('precision:', matrix['precision'])
st.write('recall:', matrix['recall'])
build_controllerで、Controllerクラスのインスタンスを生成していますが、この中身を変更することで、Controller以降の内部の挙動が変更されます。
例えば、今回はGradientBoostingClassifierを使っていますが、RandomForestClassifierに変更するなどが容易に出来ます。
まとめ
本記事では、Pythonで実装されたクリーンアーキテクチャのサンプルプロジェクトを基に、基本概念やディレクトリ構成について解説しました。
クリーンアーキテクチャの重要ポイント
✅ 依存関係の方向を整理して変更に強い設計にする。
✅ ビジネスロジックを独立させ、フレームワークの影響を受けないようにする。
✅ 各レイヤーを分離することで、テストしやすくする。
初心者の方は、このサンプルプロジェクトを実際に動かしながら、クリーンアーキテクチャの理解を深めてみてください!
Discussion