はじめに

作ったアプリ
ソースコード
つくるもの
- 指定した期間を可視化できる
- 都道府県にカーソルを合わせたら詳細が出てくる
環境
Python 3.9.6
python = ">=3.9,<3.9.7"
folium = "^0.14.0"
streamlit = "^1.25.0"
streamlit-folium = "^0.13.0"
geopandas = "^0.13.2"
numpy = "^1.25.1"
データの加工
データのダウンロード
オープンデータ|厚生労働省 にある 新規陽性者数の推移(日別) をダウンロードします。
Date,ALL,Hokkaido,Aomori,Iwate,Miyagi,Akita,Yamagata,Fukushima,Ibaraki,Tochigi,Gunma,Saitama,Chiba,Tokyo,Kanagawa,Niigata,Toyama,Ishikawa,Fukui,Yamanashi,Nagano,Gifu,Shizuoka,Aichi,Mie,Shiga,Kyoto,Osaka,Hyogo,Nara,Wakayama,Tottori,Shimane,Okayama,Hiroshima,Yamaguchi,Tokushima,Kagawa,Ehime,Kochi,Fukuoka,Saga,Nagasaki,Kumamoto,Oita,Miyazaki,Kagoshima,Okinawa
2020/1/16,1,0,0,0,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
2020/1/17,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
2020/1/18,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
...
データの加工
現在のデータだと日付をキーとして扱っているのですが、都道府県別に取得する場合少し扱いづらいので扱いやすいように加工します。
import csv
import pandas as pd
DATASETS_PATH = "./path/to/newly_confirmed_cases_daily.csv"
EXPORT_PATH = "./path/to/export/japan_covid_19_cases_daily.csv"
COLUMNS = ["Prefecture_name", "Prefecture_code", "Date", "Infections"]
PREFECTURES_CODE = {
1: '北海道', 2: '青森県', 3: '岩手県', 4: '宮城県', 5: '秋田県',
6: '山形県', 7: '福島県', 8: '茨城県', 9: '栃木県', 10: '群馬県',
11: '埼玉県', 12: '千葉県', 13: '東京都', 14: '神奈川県', 15: '新潟県',
16: '富山県', 17: '石川県', 18: '福井県', 19: '山梨県', 20: '長野県',
21: '岐阜県', 22: '静岡県', 23: '愛知県', 24: '三重県', 25: '滋賀県',
26: '京都府', 27: '大阪府', 28: '兵庫県', 29: '奈良県', 30: '和歌山県',
31: '鳥取県', 32: '島根県', 33: '岡山県', 34: '広島県', 35: '山口県',
36: '徳島県', 37: '香川県', 38: '愛媛県', 39: '高知県', 40: '福岡県',
41: '佐賀県', 42: '長崎県', 43: '熊本県', 44: '大分県', 45: '宮崎県',
46: '鹿児島県', 47: '沖縄県'
}
datasets = pd.read_csv(DATASETS_PATH)
# 列`All`が必要ないので削除する
df = datasets.drop("ALL", axis=1)
# 現在列名が都道府県名になってるので都道府県コードに変更する
columns = {}
for i, column in enumerate(df.columns[1:]):
# すでにデータ上の順番が都道府県コードなのでそのまま番号に変更する
columns[column] = str(i + 1)
df.rename(columns=columns, inplace=True)
# csvとしてエクスポート
with open(EXPORT_PATH, "w", encoding="utf-8", newline="") as csv_file:
writer = csv.writer(csv_file)
writer.writerow(COLUMNS)
for column in df.columns[1:]:
for date, infections in zip(df["Date"], df[column]):
writer.writerow([PREFECTURES_CODE[int(column)], column, date, infections])
すると都道府県別にカラムができて都道府県別としての時系列が扱いやすくなりました。
| Prefecture_name | Prefecture_code | Date | Infections |
|---|---|---|---|
| 群馬県 | 10 | 2020/10/20 | 12 |
| 埼玉県 | 11 | 2020/10/20 | 32 |
| 千葉県 | 12 | 2020/10/20 | 40 |
| 東京都 | 13 | 2020/10/20 | 139 |
| 神奈川県 | 14 | 2020/10/20 | 47 |
| ... |
streamlitでfoliumのマップを表示してみる
foliumだけでは表示できないので、streamlit-foliumをつかって表示します。
st_foliumに対してuse_container_width=Trueを使うとレスポンシブ対応されます。
import folium
import streamlit as st
from streamlit_folium import st_folium
st.set_page_config(
page_title="指定期間の都道府県別の新型コロナ感染割合",
page_icon="🗾",
layout="wide"
)
map = folium.Map(
location=(36.56583, 139.88361),
tiles="cartodbpositron",
zoom_start=5
)
st_folium(map, use_container_width=True, height=720)
streamlitは以下のコマンドで起動できます
streamlit run ./path/to/yourfile.py

都道府県別のヒートマップを作成
geojsonをダウンロード
都道府県別のgeojsonをgithubで見つけました。 国土交通省 国土地理院の 地球地図日本 で公開しているShapefileを変換して加工してくれたものみたいです。
利用規約を読んでから使用してください。
ここのリポからjapan.geojsonをダウンロードします。
試しにgeojsonをfoliumマップに表示してみるとこんな感じになります。
ソースコード
import folium
import streamlit as st
import geopandas as gpd
from streamlit_folium import st_folium
GEOJSON_PATH = "./path/to/japan.geojson"
st.set_page_config(
page_title="指定期間の都道府県別の新型コロナ感染割合",
page_icon="🗾",
layout="wide"
)
map = folium.Map(
location=(36.56583, 139.88361),
tiles="cartodbpositron",
zoom_start=5
)
geojson = gpd.read_file(GEOJSON_PATH)
folium.GeoJson(geojson).add_to(map)
st_folium(map, use_container_width=True, height=720)

マップを動かすとアプリがリロードしてしまう
アプリ上でマップを動かしたり、ズームしたりするとアプリがリロードされてしまうので、すこし調べてみると、マップに変更を加えることでstreamlitに対して違う値を返してしまい、リロードしてしまうので、st_foliumにreturned_objects=[]を指定して何も返さないようにすればいいみたいです。
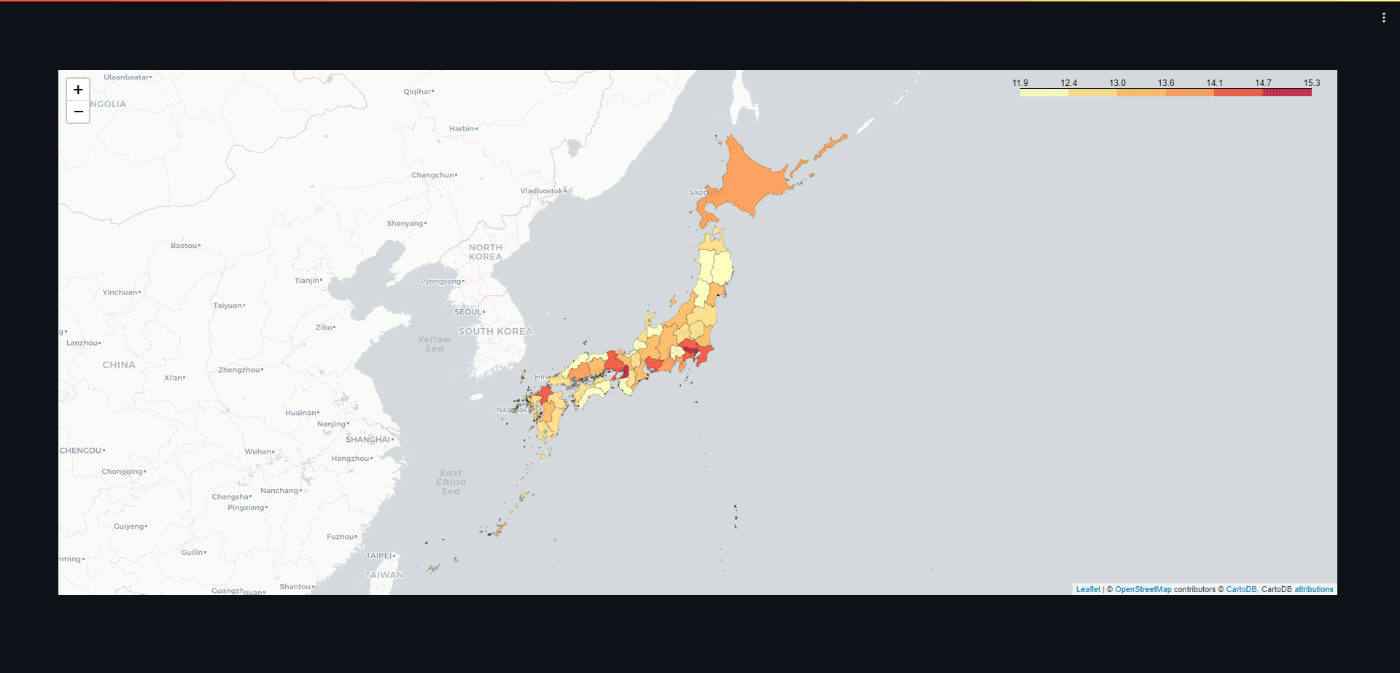
全期間のヒートマップを作成
実際にヒートマップの重みを対数スケールにして、表示してみたいと思います。
@st.cache_dataを使って、geojsonとcsvはずっと同じデータなのでキャッシュ化して、一回目以降の読み込みを効率化してます。
@st.cache_data
def get_geojson():
gpd_df = gpd.read_file(GEOJSON_PATH)
return gpd_df
@st.cache_data
def get_datasets():
df = pd.read_csv(DATASETS_PATH)
df["Date"] = pd.to_datetime(df["Date"]).dt.date
return df
folium.Choroplethのcolums引数の配列の一個目はデータセットのキーとなるカラムを書きます。2個目にはヒートマップの重みとなるカラムを選びます。
key_on引き数では、geojsonファイルにあるデータとデータセットのデータを紐づけるキーを記入します。
folium.Choroplethにヒートマップの色など、ほかのパラメータが指定できるので詳しくは ドキュメント をみてください。
folium.Choropleth(
geo_data=geojson,
data=df_all,
columns=["Prefecture_code", "Infections_logarithm"],
key_on="feature.properties.id",
fill_color='YlOrRd',
nan_fill_color='darkgray',
fill_opacity=0.8,
nan_fill_opacity=0.8,
line_opacity=0.2,
).add_to(map)
それぞれのDataFrame.groupbyを使ってグループ化してaggメゾットでグループごとにsumしていきます。
また日本の三大都市があまりにもほかの県との差が大きいので、対数スケールにしてもう少し見やすくします。
ついでにカーソルを合わせたときに表示する割合もここで計算しておきます。
df_group = df.groupby(["Prefecture_name", "Prefecture_code"], as_index=False)
df_group = df_group.agg({
'Infections': 'sum'
})
df_group.sort_values("Infections", inplace=True, ascending=False)
df_group["Infections_logarithm"] = np.log(df_group["Infections"])
df_group[df_group["Infections_logarithm"] == -np.inf] = 0
df_group["Infections_Percentage"] = 100 * df_group["Infections"] / df_group["Infections"].sum()
geojsonを確認してみると、それぞれの都道府県別の空間データと一緒に
都道府県コード(feature.properties.id)があるので、今回はこれを使用します。
{
"type": "FeatureCollection",
"features": [
{
"type": "Feature",
"properties": {
"nam": "Kyoto Fu",
"nam_ja": "京都府",
"id": 26
},
"geometry": {
"type": "MultiPolygon",
"coordinates": [
[
[
[
...
ここまでのソースコード
import folium
import numpy as np
import pandas as pd
import streamlit as st
import geopandas as gpd
from streamlit_folium import st_folium
GEOJSON_PATH = "./path/to/japan.geojson"
DATASETS_PATH = "./path/to/japan_covid_19_cases_daily.csv"
@st.cache_data
def get_geojson():
gpd_df = gpd.read_file(GEOJSON_PATH)
return gpd_df
@st.cache_data
def get_datasets():
df = pd.read_csv(DATASETS_PATH)
df["Date"] = pd.to_datetime(df["Date"]).dt.date
return df
st.set_page_config(
page_title="指定期間の都道府県別の新型コロナ感染割合",
page_icon="🗾",
layout="wide"
)
map = folium.Map(
location=(36.56583, 139.88361),
tiles="cartodbpositron",
zoom_start=5
)
geojson = get_geojson()
df = get_datasets()
df_group = df.groupby(["Prefecture_name", "Prefecture_code"], as_index=False)
df_group = df_group.agg({
'Infections': 'sum'
})
df_group.sort_values("Infections", inplace=True, ascending=False)
df_group["Infections_logarithm"] = np.log(df_group["Infections"])
df_group[df_group["Infections_logarithm"] == -np.inf] = 0
df_group["Infections_Percentage"] = 100 * df_group["Infections"] / df_group["Infections"].sum()
folium.Choropleth(
geo_data=geojson,
data=df_group,
columns=["Prefecture_code", "Infections_logarithm"],
key_on="feature.properties.id",
fill_color='YlOrRd',
nan_fill_color='darkgray',
fill_opacity=0.8,
nan_fill_opacity=0.8,
line_opacity=0.2,
).add_to(map)
st_folium(map, use_container_width=True, height=720, returned_objects=[])
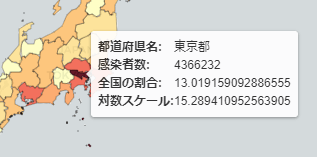
カーソルを合わせたときに詳細を表示
folium.Choroplethはカーソルを合わせたときに、tooltipを表示することができないので上のレイヤーにほぼ透明なfolium.GeoJsonを置いて表示します。
それに使う変数を宣言します。
STYLE_FUNC = lambda x: {'fillColor': '#ffffff',
'color':'#000000',
'fillOpacity': 0.1,
'weight': 0.1}
HIGHLIGHT_FUNC = lambda x: {'fillColor': '#000000',
'color':'#000000',
'fillOpacity': 0.50,
'weight': 0.1}
そのためにまず、folium.GeoJsonは一つのデータフレームしか使えないので、geopandasとdataframeをマージします。これにより、データを取得することができるようになります。
df_geojson = pd.merge(
geojson.loc[:,['id', 'nam_ja', 'geometry']], df,
right_on="Prefecture_code",
left_on="id",
)
tooltipのところのfieldsにカーソル合わせたときに表示したいカラムを指定して、aliasesは表示したデータのラベルを書きます。folium.GeoJsonTooltipは他にもできることがあるので詳しくは ドキュメント を見てください。
choropleth_info = folium.GeoJson(
data=df_geojson,
style_function=STYLE_FUNC,
highlight_function=HIGHLIGHT_FUNC,
control=False,
tooltip=folium.GeoJsonTooltip(
fields=["nam_ja", "Infections", "Infections_Percentage", "Infections_logarithm"],
aliases=['都道府県名: ', '感染者数: ', '全国の割合: ', '対数スケール: '],
labels=True,
sticky=True,
style=("background-color: white; color: #333333; font-family: arial; font-size: 12px; padding: 10px;"),
)
)
ここで常に一番上に表示させています。
map.keep_in_front(choropleth_info)
ここで薄くさせて、カーソル合わせたときのstyleを記述しています。
choropleth_info = folium.GeoJson(
data=df,
style_function=STYLE_FUNC,
highlight_function=HIGHLIGHT_FUNC,
...
ここまでのソースコード
import folium
import numpy as np
import pandas as pd
import streamlit as st
import geopandas as gpd
from streamlit_folium import st_folium
GEOJSON_PATH = "./path/to/japan.geojson"
DATASETS_PATH = "./path/to/japan_covid_19_cases_daily.csv"
STYLE_FUNC = lambda x: {'fillColor': '#ffffff',
'color':'#000000',
'fillOpacity': 0.1,
'weight': 0.1}
HIGHLIGHT_FUNC = lambda x: {'fillColor': '#000000',
'color':'#000000',
'fillOpacity': 0.50,
'weight': 0.1}
@st.cache_data
def get_geojson():
gpd_df = gpd.read_file(GEOJSON_PATH)
return gpd_df
@st.cache_data
def get_datasets():
df = pd.read_csv(DATASETS_PATH)
df["Date"] = pd.to_datetime(df["Date"]).dt.date
return df
st.set_page_config(
page_title="指定期間の都道府県別の新型コロナ感染割合",
page_icon="🗾",
layout="wide"
)
map = folium.Map(
location=(36.56583, 139.88361),
tiles="cartodbpositron",
zoom_start=5
)
geojson = get_geojson()
df = get_datasets()
df_group = df.groupby(["Prefecture_name", "Prefecture_code"], as_index=False)
df = df_group.agg({
'Infections': 'sum'
})
df.sort_values("Infections", inplace=True, ascending=False)
df["Infections_logarithm"] = np.log(df["Infections"])
df["Infections_Percentage"] = 100 * df["Infections"] / df["Infections"].sum()
folium.Choropleth(
geo_data=geojson,
data=df,
columns=["Prefecture_code", "Infections_logarithm"],
key_on="feature.properties.id",
fill_color='YlOrRd',
nan_fill_color='darkgray',
fill_opacity=0.8,
nan_fill_opacity=0.8,
line_opacity=0.2,
).add_to(map)
df_geojson = pd.merge(
geojson.loc[:,['id', 'nam_ja', 'geometry']], df,
right_on="Prefecture_code",
left_on="id",
)
choropleth_info = folium.GeoJson(
data=df_geojson,
style_function=STYLE_FUNC,
highlight_function=HIGHLIGHT_FUNC,
control=False,
tooltip=folium.GeoJsonTooltip(
fields=["nam_ja", "Infections", "Infections_Percentage", "Infections_logarithm"],
aliases=['都道府県名: ', '感染者数: ', '全国の割合: ', '対数スケール: '],
labels=True,
sticky=True,
style=("background-color: white; color: #333333; font-family: arial; font-size: 12px; padding: 10px;"),
)
)
map.add_child(choropleth_info)
map.keep_in_front(choropleth_info)
st_folium(map, use_container_width=True, height=720, returned_objects=[])
表示するデータの絞り込み機能の作成
画面を分割して、マップとウィジェットを分ける
このままでは画面全体にマップが広がっているので、st.columnsを使って4:1に画面で分けます。
画面を4:1に変更します。
placeholder = st.empty()
map_col, menu_col = placeholder.columns([4, 1])
これを使ってそれぞれの画面に分けるためにコードの全体を変更します。
また、今回はメニューの部分は期間を指定できるようにするだけなので、これで大丈夫です。
with menu_col:
st.header("絞り込み")
start_date = st.date_input(
'開始日',
min_value=df["Date"].min(),
max_value=df["Date"].max(),
value=df["Date"].min(),
key="start_date"
)
end_date = st.date_input(
'終了日',
min_value=df["Date"].min(),
max_value=df["Date"].max(),
value=df["Date"].max(),
key="end_date"
)
こんな感じに分けます
geojson = get_geojson()
df = get_datasets()
placeholder = st.empty()
map_col, menu_col = placeholder.columns([4, 1])
with menu_col:
st.header("絞り込み")
start_date = st.date_input(
'開始日',
min_value=df["Date"].min(),
max_value=df["Date"].max(),
value=df["Date"].min(),
key="start_date"
)
end_date = st.date_input(
'終了日',
min_value=df["Date"].min(),
max_value=df["Date"].max(),
value=df["Date"].max(),
key="end_date"
)
with map_col:
df_group = df.groupby(["Prefecture_name", "Prefecture_code"], as_index=False)
df_group = df_group.agg({
'Infections': 'sum'
})
df_group.sort_values("Infections", inplace=True, ascending=False)
df_group["Infections_logarithm"] = np.log(df_group["Infections"])
df_group["Infections_Percentage"] = 100 * df_group["Infections"] / df_group["Infections"].sum()
folium.Choropleth(
geo_data=geojson,
data=df_group,
columns=["Prefecture_code", "Infections_logarithm"],
key_on="feature.properties.id",
fill_color='YlOrRd',
nan_fill_color='darkgray',
fill_opacity=0.8,
nan_fill_opacity=0.8,
line_opacity=0.2,
).add_to(map)
...
分けたときのソースコード
import folium
import numpy as np
import pandas as pd
import streamlit as st
import geopandas as gpd
from datetime import date
from streamlit_folium import st_folium
GEOJSON_PATH = "./path/to/japan.geojson"
DATASETS_PATH = "./path/to/japan_covid_19_cases_daily.csv"
STYLE_FUNC = lambda x: {'fillColor': '#ffffff',
'color':'#000000',
'fillOpacity': 0.1,
'weight': 0.1}
HIGHLIGHT_FUNC = lambda x: {'fillColor': '#000000',
'color':'#000000',
'fillOpacity': 0.50,
'weight': 0.1}
@st.cache_data
def get_geojson():
gpd_df = gpd.read_file(GEOJSON_PATH)
return gpd_df
@st.cache_data
def get_datasets():
df = pd.read_csv(DATASETS_PATH)
df["Date"] = pd.to_datetime(df["Date"]).dt.date
return df
st.set_page_config(
page_title="指定期間の都道府県別の新型コロナ感染割合",
page_icon="🗾",
layout="wide"
)
map = folium.Map(
location=(36.56583, 139.88361),
tiles="cartodbpositron",
zoom_start=5
)
geojson = get_geojson()
df = get_datasets()
placeholder = st.empty()
map_col, menu_col = placeholder.columns([4, 1])
with menu_col:
st.header("絞り込み")
start_date = st.date_input(
'開始日',
min_value=df["Date"].min(),
max_value=df["Date"].max(),
value=df["Date"].min(),
key="start_date"
)
end_date = st.date_input(
'終了日',
min_value=df["Date"].min(),
max_value=df["Date"].max(),
value=df["Date"].max(),
key="end_date"
)
with map_col:
df_group = df.groupby(["Prefecture_name", "Prefecture_code"], as_index=False)
df_group = df_group.agg({
'Infections': 'sum'
})
df_group.sort_values("Infections", inplace=True, ascending=False)
df_group["Infections_logarithm"] = np.log(df_group["Infections"])
df_group["Infections_Percentage"] = 100 * df_group["Infections"] / df_group["Infections"].sum()
folium.Choropleth(
geo_data=geojson,
data=df_group,
columns=["Prefecture_code", "Infections_logarithm"],
key_on="feature.properties.id",
fill_color='YlOrRd',
nan_fill_color='darkgray',
fill_opacity=0.8,
nan_fill_opacity=0.8,
line_opacity=0.2,
).add_to(map)
df_geojson = pd.merge(
geojson.loc[:,['id', 'nam_ja', 'geometry']], df_group,
right_on="Prefecture_code",
left_on="id",
)
choropleth_info = folium.GeoJson(
data=df_geojson,
style_function=STYLE_FUNC,
highlight_function=HIGHLIGHT_FUNC,
control=False,
tooltip=folium.GeoJsonTooltip(
fields=["nam_ja", "Infections", "Infections_Percentage", "Infections_logarithm"],
aliases=['都道府県名: ', '感染者数: ', '全国の割合: ', '対数スケール: '],
labels=True,
sticky=True,
style=("background-color: white; color: #333333; font-family: arial; font-size: 12px; padding: 10px;"),
)
)
map.add_child(choropleth_info)
map.keep_in_front(choropleth_info)
st_folium(map, use_container_width=True, height=720, returned_objects=[])
実際にデータを絞る
実際st.session_stateでinputの中身を取得して、絞ります。
また、件数がゼロ以下だった場合は 該当データなし と表示します。
with map_col:
if st.session_state["start_date"] and st.session_state["end_date"]:
start_date = st.session_state["start_date"]
end_date = st.session_state["end_date"]
df = df[(df["Date"] >= start_date) & (df["Date"] <= end_date)]
if len(df) <= 0:
st.markdown("# 該当データなし")
else:
...

最終的なソースコード
import folium
import numpy as np
import pandas as pd
import streamlit as st
import geopandas as gpd
from datetime import date
from streamlit_folium import st_folium
GEOJSON_PATH = "./path/to/japan.geojson"
DATASETS_PATH = "./path/to/japan_covid_19_cases_daily.csv"
STYLE_FUNC = lambda x: {'fillColor': '#ffffff',
'color':'#000000',
'fillOpacity': 0.1,
'weight': 0.1}
HIGHLIGHT_FUNC = lambda x: {'fillColor': '#000000',
'color':'#000000',
'fillOpacity': 0.50,
'weight': 0.1}
@st.cache_data
def get_geojson():
gpd_df = gpd.read_file(GEOJSON_PATH)
return gpd_df
@st.cache_data
def get_datasets():
df = pd.read_csv(DATASETS_PATH)
df["Date"] = pd.to_datetime(df["Date"]).dt.date
return df
st.set_page_config(
page_title="指定期間の都道府県別の新型コロナ感染割合",
page_icon="🗾",
layout="wide"
)
map = folium.Map(
location=(36.56583, 139.88361),
tiles="cartodbpositron",
zoom_start=5
)
geojson = get_geojson()
df = get_datasets()
placeholder = st.empty()
map_col, menu_col = placeholder.columns([4, 1])
with menu_col:
st.header("絞り込み")
start_date = st.date_input(
'開始日',
min_value=df["Date"].min(),
max_value=df["Date"].max(),
value=df["Date"].min(),
key="start_date"
)
end_date = st.date_input(
'終了日',
min_value=df["Date"].min(),
max_value=df["Date"].max(),
value=df["Date"].max(),
key="end_date"
)
with map_col:
if st.session_state["start_date"] and st.session_state["end_date"]:
start_date = st.session_state["start_date"]
end_date = st.session_state["end_date"]
df = df[(df["Date"] >= start_date) & (df["Date"] <= end_date)]
if len(df) <= 0:
st.markdown("# 該当データなし")
else:
df_group = df.groupby(["Prefecture_name", "Prefecture_code"], as_index=False)
df_group = df_group.agg({
'Infections': 'sum'
})
df_group.sort_values("Infections", inplace=True, ascending=False)
df_group["Infections_logarithm"] = np.log(df_group["Infections"])
df_group[df_group["Infections_logarithm"] == -np.inf] = 0
df_group["Infections_Percentage"] = 100 * df_group["Infections"] / df_group["Infections"].sum()
folium.Choropleth(
geo_data=geojson,
data=df_group,
columns=["Prefecture_code", "Infections_logarithm"],
key_on="feature.properties.id",
fill_color='YlOrRd',
nan_fill_color='darkgray',
fill_opacity=0.8,
nan_fill_opacity=0.8,
line_opacity=0.2,
).add_to(map)
df_geojson = pd.merge(
geojson.loc[:,['id', 'nam_ja', 'geometry']], df_group,
right_on="Prefecture_code",
left_on="id",
)
choropleth_info = folium.GeoJson(
data=df_geojson,
style_function=STYLE_FUNC,
highlight_function=HIGHLIGHT_FUNC,
control=False,
tooltip=folium.GeoJsonTooltip(
fields=["nam_ja", "Infections", "Infections_Percentage", "Infections_logarithm"],
aliases=['都道府県名: ', '感染者数: ', '全国の割合: ', '対数スケール: '],
labels=True,
sticky=True,
style=("background-color: white; color: #333333; font-family: arial; font-size: 12px; padding: 10px;"),
)
)
map.add_child(choropleth_info)
map.keep_in_front(choropleth_info)
st_folium(map, use_container_width=True, height=720, returned_objects=[])
最後に
初めてzennの記事を書いてみました!
初めてgeojsonとか、streamlit使ってみました!
参考になるとうれしいです。

Discussion