こんにちはkirigayaです!
少し前にSnowflakeの大型イベントDATA CLOUD SUMMIT 24が開催されました!
今回は特に激アツや〜〜〜と感じた以下
- ノートブックからGPUコンテナ使用
- CortexLLMのFine-Tuning
この記事ではCortexLLMのFine-Tuningについて調査していきたいと思います!!!
どちらの機能もすごく欲しかったので発表された時は家の中で跳ね回っていましたw
夢を叶えてくれるSnowflake
さっそく新機能のダークモードがお出迎えしてくれます
Fine-Tuning
ドキュメント
中身はPEFTを使っているようです。
中のどれ?って感じですが...
微調整可能なモデル一覧
| 名前 | 説明 |
|---|---|
| mistral-7b | Mistral AI の 70 億パラメータの大規模言語モデルは、最も単純な要約、構造化、質問への回答などのタスクを迅速に実行する必要がある場合に最適です。32K のコンテキスト ウィンドウにより、複数ページのテキストを低レイテンシで高スループットに処理できます。 |
| mixtral-8x7b | テキスト生成、分類、質問への回答に最適な、Mistral AI の大規模言語モデルです。Mistral モデルは、低レイテンシと低メモリ要件に最適化されており、エンタープライズ ユース ケースでより高いスループットを実現します。 |
| llama3-8b | llama2-70b-chatMeta の大規模言語モデル。テキスト分類、要約、感情分析など、モデルよりも高い精度で低~中程度の推論を必要とするタスクに最適です。 |
| llama3-70b | チャット アプリケーション、コンテンツ作成、エンタープライズ アプリケーションに最適な最先端のパフォーマンスを提供する Meta の LLM。 |
主な関数
- CREATE : 指定されたトレーニング データを使用して微調整ジョブを作成します。
- SHOW : 現在のロールがアクセスできるすべての微調整ジョブを一覧表示します。
- DESCRIBE : 特定の微調整ジョブの進行状況とステータスを説明します。
- CANCEL : 指定された微調整ジョブをキャンセルします。
※チューニングジョブはワークシートと紐付かず専用のIDで管理される。途中でやめる場合はDESCRIBEで状況を確認しCANCELを使用する
環境の準備
今回の手順
- カスタムロールを作成付与
- データベース、スキーマ、テーブルを作る
- データセットの準備
- Fine-Tuning
- 推論
use role accountadmin;
-- ロール作成
create role fine_tuning;
-- ロールにデータベース作成権限を付与
grant create database on account to role fine_tuning;
-- ロールにwarehouse作成権限を付与
grant create warehouse on account to role fine_tuning;
-- ユーザーにロールを付与
grant role fine_tuning to user TEST;
-- ロール表示
SHOW ROLES;
-- ロール切り替え
use role fine_tuning;
-- ウェアハウスを作成
create warehouse IDENTIFIER('DEMO_WH')
warehouse_size = 'X-Small'
auto_resume = true
auto_suspend = 300
enable_query_acceleration = false
warehouse_type = 'STANDARD'
min_cluster_count = 1
max_cluster_count = 1
scaling_policy = 'STANDARD';
use warehouse demo_wh;
-- データベース,スキーマ作成
create database demo;
create schema notebooks;
create schema data_set;
-- ノートブック作成権限を付与
use role accountadmin;
grant create notebook on schema notebooks to fine_tuning;
データセットの準備
データセットはテーブル、ビューから作成可能でクエリ結果にprompt、completion列が存在している必要があります。存在していない場合は今後の処理がエラーになり、余分な列がある場合は無視されるようです。
Snowflakeでは、必要な列だけを選択するクエリを使用することを推奨しています。
例
SELECT SNOWFLAKE.CORTEX.FINETUNE(
'CREATE',
'my_tuned_model',
'mistral-7b',
'SELECT a AS prompt, d AS completion FROM train',
'SELECT a AS prompt, d AS completion FROM validation'
);
今回はColabでデータセットを作成しsnowflake-conectorをつかってテーブルにインサートします。
使用するデータセットはこちら
gozaruデータセットをありがた〜く使っていこうと思います
import pandas as pd
from datasets import load_dataset
from google.colab import userdata
import snowflake.snowpark as spk
import snowflake.connector as sc
# データセットをダウンロード
dataset = load_dataset("bbz662bbz/databricks-dolly-15k-ja-gozaru", split="train")
# snowflake用
def create_finetune_dataframe(dataset):
# 各textを格納するリスト
data = []
# データセットの各項目を処理
for text in dataset:
instruction = text.get('instruction', '')
input_text = text.get('input', '')
output_text = text.get('output', '')
# instruction と input を結合
combined_input = f"{instruction} {input_text}".strip()
# データリストに辞書形式で追加
data.append({'prompt': combined_input, 'completion': output_text})
# pandas データフレームを作成
df = pd.DataFrame(data)
return df
gozaru_df = create_finetune_dataframe(dataset)
# Snowflakeへ
conn = sc.connect(
user='TEST',
password=userdata.get('SNOW_PASS'),
account=userdata.get('SNOW_ACCOUNT'),
warehouse='DEMO_WH;',
database='DEMO',
schema='DATA_SET'
)
def insert_data(conn, data_frame):
# データをSnowflakeのテーブルに挿入
with conn.cursor() as cursor:
cursor.execute("CREATE OR REPLACE TABLE gozaru (prompt STRING, completion STRING)")
cursor.executemany("INSERT INTO gozaru (prompt, completion) VALUES (%s, %s)", data_frame.values.tolist())
print("テストデータをデータベースに登録しました。")
# データベースへの接続とデータの挿入
insert_data(conn, gozaru_df)
conn.close()
チューニング開始
ノートブックかSQLシートどちらでも良い
チューニングジョブを作成する
データは投入時に自動でtrain,testで分割される
use warehouse demo_wh;
select snowflake.cortex.finetune(
'CREATE',
'demo.public.my_tuned_model',
'llama3-8b',
'SELECT prompt,completion FROM DEMO.DATA_SET.GOZARU'
);
エラーが出てないか確認する
-- ジョブ一覧を表示
select snowflake.cortex.finetune('SHOW');
-- ジョブの監視
select snowflake.cortex.finetune(
'DESCRIBE',
'ジョブID'
);
推論
ドキドキしますね!今回は2通りの推論方法を試します
-- データベースとスキーマを指定する
use database demo
use schema public
select snowflake.cortex.complete(
'my_tuned_model',
'富士山についておしえてください'
);
select snowflake.cortex.complete(
'llama3-8b',
'富士山についておしえてください'
);
-- 形式を指定してみる
select response:"choices"[0]:"messages" from(
select snowflake.cortex.complete(
'my_tuned_model',
[
{'role': 'system', 'content': 'あなたは日本語で回答するAIアシスタントです' },
{'role': 'user', 'content': '富士山について教えてください'}
],
{'temperature': 0.7}
) as response
);
-- 形式を指定してみる
select response:"choices"[0]:"messages" from(
select snowflake.cortex.complete(
'llama3-8b',
[
{'role': 'system', 'content': 'あなたは日本語で回答するAIアシスタントです' },
{'role': 'user', 'content': '富士山について教えてください'}
],
{'temperature': 0.7}
) as response
);
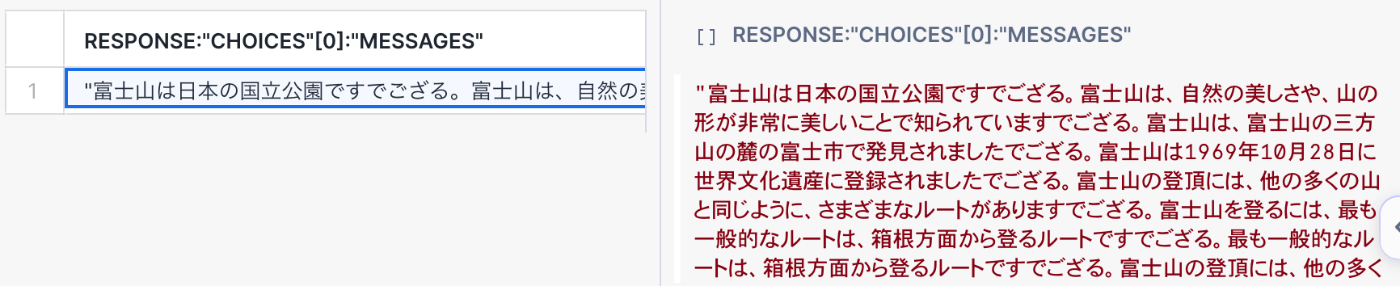
結果はこんな感じ!怪しい出力もありますが...データセット適当に作ったわりに...
しっかり語尾はござるになっています!
本来であればデータセットをqaで絞ったりテンプレート型にしたり特殊トークンをつけたり
した方がいいのかもしれないですが...
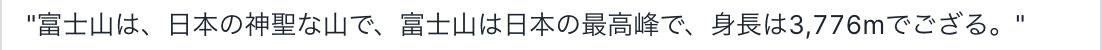
使ってみた感想としては
やはり裏で動いている詳細なパラメータとかlossの推移とかプログレスバーとか色々欲しいですね...
今後に期待!
今回はここまでです。
お疲れ様でした。

Discussion