こんにちは、IVRy でデータエンジニアとして働いている松田 健司(@ken_3ba)と申します。今まで「マツケン」というあだ名しかつかなかったのですが、社内では長いからという理由でKJと呼ばれるようになりました。
本記事は、IVRy Advent Calender「IVRy AIブログリレー Part2」6日目の記事です。
2025年7月1日入社でまだ半年経っていませんが、前職からDatabricksをずっと触っており、IVRyでもDatabricksを利用したデータ基盤構築や利活用をしています。
この記事では、Databricksの機能の1つであるAI関数を利用したプロダクト開発とその運用体制についてお話しします。実際にDatabricksを使っている方、また、Databricksは使っていないがAIをサービスに導入している方に参考になればと思います。
TL;DR
- Databricksのai_queryを使い、LLMをプロダクトに実装した際の事例を紹介します。
- AI利用時のコスト監視手法について紹介します。
- 実際にコスト異常を検知し、改善につなげたエピソードについても紹介します。
IVRy Data Hubについて
IVRyでは先日11月6日に、新しいデータプラットフォーム「IVRy Data Hub」をリリースしました。
その中で私は、社内向けのIVRy Data Hubプロジェクトに携わっており、データ基盤とAIを活用して、セールスやカスタマーサクセスチームの業務支援を行うプロダクトを開発しています。
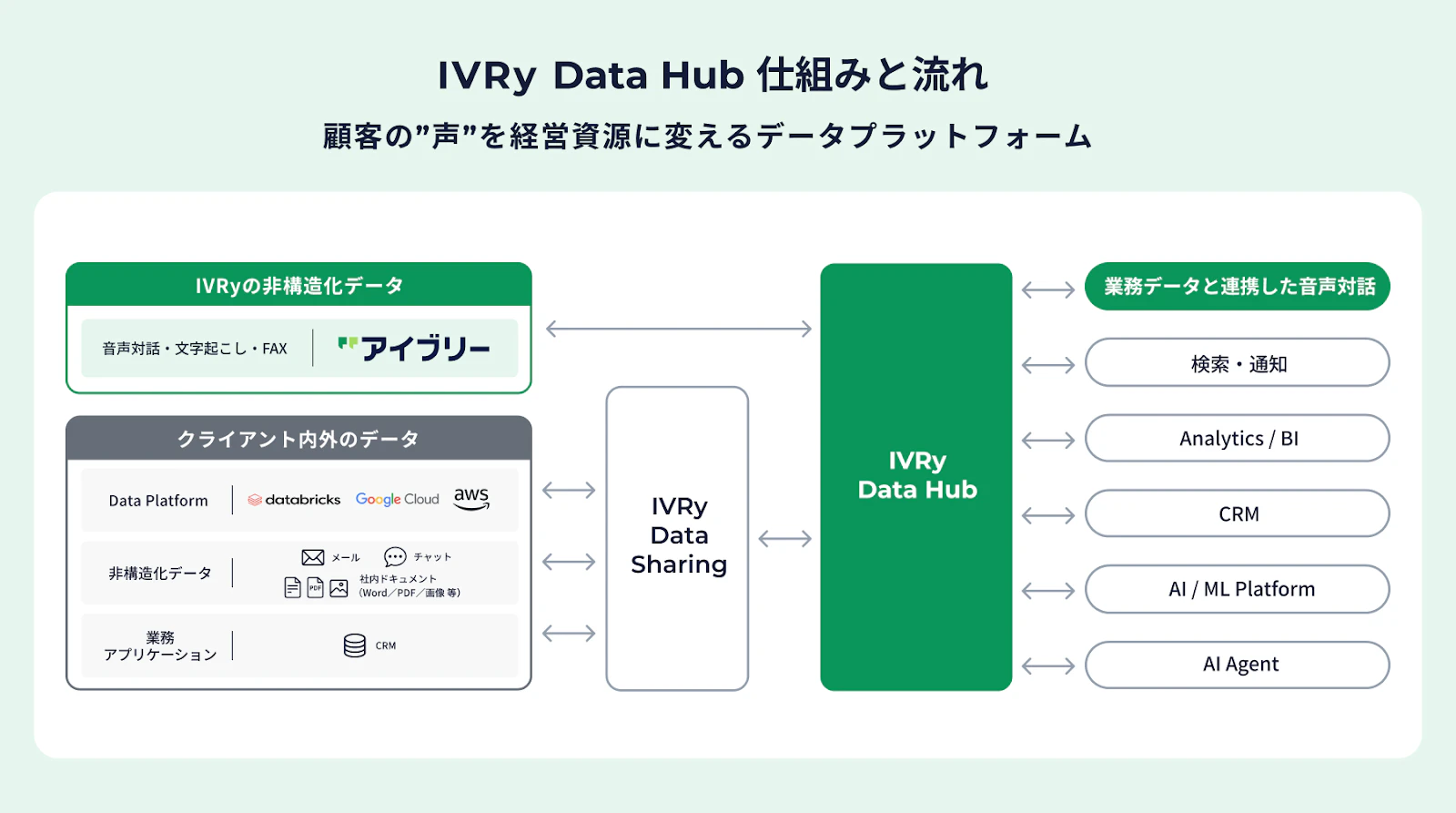
このプロダクトでは、2つの形でLLMを活用しています。
-
データ加工: Databricksの
ai_queryを使い、通話データの要約、テキストからの情報抽出、内容の分類といった処理をSQLの中で実行 - ユーザーとのやり取り: AIエージェントを通じて、セールスやCSメンバーが直接AIと対話しながら業務を進められる仕組み
本記事では、ai_queryを利用したデータ加工について記載します。
Databricks ai_queryとは
Databricksには「AI関数」と呼ばれる機能群があります。その中でもai_queryは汎用的な関数で、様々なユースケースに対応できます。
ai_queryは、以下のサンプルコードのようにSQLの中で直接LLMを呼び出せる関数です。
SELECT
ai_query(
'databricks-meta-llama-3-1-70b-instruct',
CONCAT('以下のテキストを要約してください: ', text_column)
) as summary
FROM my_table
この機能がリリースされたとき、私はとても驚きました。SQLでLLMを実行する発想が、今までの私の頭の中にはなかったからです。普通、LLMを使おうと思ったら「APIを叩くコードを書いて…」と考えますよね。それがSQLのSELECT文の中で完結してしまう。新しい時代が来たなと感じました。
この手軽さのおかげでアイデアはどんどん広がり、「データの解析ができそう」「Slackのデータが入っているからサマライズできそう」など、思いついたらすぐに試せる環境があります。
しかし、すぐに試せることと、プロダクトに組み込めることは別問題です。大体の場合、この手の機能は実験的な利用で終わってしまい、継続的にプロダクトで利用するところまでは踏み出せないケースが多いのかなと思っています。
私たちはこの壁を乗り越えて、ai_queryを実際にプロダクトに組み込みましたので、そのユースケースをお伝えします。
実際にプロダクトで動いているai_queryのユースケース
実際にai_queryをプロダクトで稼働している活用事例をご紹介します。
1. 個人情報マスキング(ai_mask)
通話データやテキストデータに含まれる個人情報を、高精度でマスキングしています。
正規表現ベースのマスキングでは、以下のような曖昧な表現に対応できません。しかし、LLMなら文脈を理解して「山田太郎さん」、「taro.yamada@example.com」が個人情報であることを認識し、適切にマスキングできます。

このように、LLMを活用することで正規表現では難しい曖昧な表現も高精度でマスキングでき、データ活用の幅が広がります。
2. 社内会議の要約
社内会議はGoogle Meetで録画しており、AI文字起こしの自動化設定をしています。AIエージェントがこのデータを参照する際、文字起こしをそのまま使うとトークン数が膨大になり、2つの問題が発生します。
- レスポンススピードの低下: エージェントの応答が遅くなる
- コストの増大: LLMの利用コストが跳ね上がる
そこで、Databricksのai_queryを使い、文字起こしデータから要約を自動生成しています。事前に要約しておくことで、エージェントが効率よくデータを参照できるようになっています。
これらはすべて「試してみた」レベルではなく、プロダクションで継続的に動いている機能です。
AI破産を防ぐコスト監視体制の構築
LLMをプロダクトで運用するからこそ、コスト管理がより重要になります。
私たちが実際に構築した監視体制を紹介します。
1. コストダッシュボードの作成と定点観測
Databricksを利用した際に自動で取得されるシステムテーブルがあります。
それを活用して、AI関数の利用状況を可視化するような以下のダッシュボードを作成しています。

このダッシュボードはデータ基盤チームの毎週の定例で確認しており、スパイクが発生した場合は原因を調査する運用にしています。これにより、知らぬ間に高額利用していた、という事態を防げます。
また、利用者向けにもダッシュボードを公開しています。自分がどれくらい利用したかをすぐに確認でき、AIのコスト感を実感を持って把握できます。
さらに、最近のDatabricksのアップデートで、ダッシュボードのグラフ画像をSlackへ自動連携できる機能が追加されました。わざわざダッシュボードを見に行く必要がなくなり、とても便利です。
2. 閾値を超えた場合のアラート設定
グラフ画像がSlackへ自動連携される前は、ダッシュボードを毎日見に行くのに運用コストがかかっていました。そこで、閾値を超えた場合に自動でSlackアラートが飛ぶ仕組みを構築しています。
具体的には、以下のような条件でアラートを出しています。
- 前日のコストが1日あたりの予算を超えた場合
- ai_queryの利用料が閾値を超えた場合
アラートが飛んだら、まずダッシュボードで詳細を確認し、どのクエリが原因かを特定できます。
3. シミュレータによる事前見積もり
新しいAI機能を試す際、「実際にどれくらいコストがかかるか」を事前に見積もることで、大幅なコスト増加を防ぐことができます。Databricksにはコストを試算できるシミュレータがあるため、そちらを利用して試算し、コスト感覚を持ちながら開発を進めています。

4. 利用制限の設定
意図しない過度な利用を防ぐため、Databricksの利用制限機能を活用しています。Databricksでは、モデルごとに以下の単位で制限をかけられます。
- QPM(Queries Per Minute): 1分あたりのリクエスト数の上限
- TPM(Tokens Per Minute): 1分あたりのトークン数の上限

この設定により、たとえばクエリのミスでLIMIT句を外してしまい大量のレコードを実行しても、一定の範囲内でコストが抑えられます。「最悪の事態」を想定したガードレールとして機能しています。
これらの4つの施策は、インフラ運用では当たり前のことですが、AI時代においても同様、むしろそれ以上に重要です。コスト監視、アラート、事前見積もり、利用制限を徹底することで、予期せぬコスト増加を防いでいます。
コスト異常を検知し実際に改善した事例
ai_queryを使った機能をプロダクションにデプロイして数日後、データ基盤チームの毎週の定例で想定よりコストがかかっていることに気づきました。
差分更新したレコードにしかai_queryを適用していないはずなのに、思ったよりコストがかかっている。調査したところ、すでに処理済みの全体のレコードに対してもai_queryが実行されており、想定以上にコストがかかっている状態でした。
その原因を調査したところ、CTEの記述ミスでした。
具体的には、WHERE句による絞り込みをCTEの外側(最後のSELECT)で行っており、CTE内で早めにフィルタリングしていなかったことが原因です。
-- 問題のあるクエリの簡略化例
WITH ai_processed AS (
SELECT
id,
ai_query('model', text_column) as result
FROM source_table
-- ここでフィルタリングしていない!
)
SELECT * FROM ai_processed
WHERE updated_at > '2024-01-01' -- フィルタリングが遅い
この書き方だと、CTE内でai_queryが全レコードに対して実行された後に、WHERE句で絞り込まれます。つまり、本来処理が不要なレコードにもai_queryが実行され、コストが無駄にかかっていました。
幸いにも、コスト監視ダッシュボードやアラート設定を事前に構築していたため、この異常に気づくことができました。いやー、本当に助かった。。。
もしそれらがなければ、月末の請求書を見て初めて気づくことになったと思うと肝が冷えました。
「AI破産」という言葉は大げさかもしれませんが、LLMのコストは使い方次第で簡単に数十万、数百万円に達します。事前に監視体制を構築しておいて本当によかったです。
まとめ
本記事では、Databricksのai_queryを使ってLLMをプロダクトに組み込んだ事例を紹介しました。
- LLMのプロダクト実装: 個人情報マスキングや商談動画の要約など、実際にプロダクションで継続的に動いている機能を紹介しました
- コスト監視体制の構築: ダッシュボード作成、アラート設定、シミュレータによる事前見積もり、利用制限の4つの施策で予期せぬコスト増加を防いでいます
- 監視体制の効果: CTEの記述ミスによるコスト異常を早期に検知し、改善につなげることができました
LLMをプロダクトに組み込む際は、機能開発と同じくらいコスト監視体制の構築が重要です。この記事が、これからLLMを本番運用しようとしている方の参考になれば幸いです。
IVRyでは、Advent Calendarをもう1レーン走らせています。
IVRyでは「イベントや最新ニュース、募集ポジションの情報を受け取りたい」「会社について詳しく話を聞いてみたい」といった方に向けて、キャリア登録やカジュアル面談の機会をご用意しています。ご興味をお持ちいただけた方は、ぜひ以下のページよりご登録・お申し込みください。

Discussion