こんにちは、株式会社IVRy のボルドーです。
本記事では弊社のモバイルアプリ「アイブリー」で取得している Firebase の Analytics および Crashlytics のログを Claude Code に分析、SQL を書かせてデータ基盤上にモニタリングダッシュボードを作成したので紹介したいと思います。

Databricks
IVRy では Databricks を社内データ基盤として採用し、2025 年 7 月から本格利用を開始しています。導入の様子は以下のスライドで紹介されています。
その他にも 7月の導入以降続々と記事を公開しています。
- [2025-09-30] Databricks Genie を利用した分析基盤とデータモデリングの IVRy の現在地
- 自然言語でのデータ分析を当たり前に:IVRyのDatabricks Genie運用の現在地(インターン視点)
- データウェアハウスでアプリ開発!? 新機能Databricks Appsで社内アプリを作った話
- AI でデータ分析!Databricks Genie の活用事例
記事中にもあるように Databricks の AI である Genie には大いに期待しているのですが、「Firebase Analytics, Crashlytics 向けの分析 SQL を書かせる」という用途においては自然言語で指示して丸っと任せるということにはもう少し時間がかかりそうな印象です。
モチベーション
モバイルアプリエンジニアで日常的に SQL を書いている人は多くはないと思います。私自身がそうで、たまに書くとデータ構造や記法等 忘れてしまっていてなかなか思うような分析ができないことがもどかしかったです。
そこで AI にアイブリーアプリのログ仕様を理解させた上で高精度な SQL を全員が書けるようにしたいと思い取り組み始めました。
Firebase Analytics と Crashlytics は多くのモバイルアプリで採用されているツールであり、BigQuery へのエクスポートが非常に簡単に実現できるため BigQuery でログを分析するという記事はちらほら見かけます。
しかしながら Agentic Coding で自律的に SQL を書かせる・実行させる、Databricks で分析する ということに関して事例を見かけなかったため弊社の取り組みが誰かの参考になるかもしれないと思い執筆に至りました。
Agentic Coding の準備
SQL 実行環境の準備
Agentic Coding のために必要なことは AI がデータ構造を理解できる環境を用意すること、つまりAI が書いた SQL を実行できる環境を用意することだと考えました。
前述の通り、Firebase Analytics と Crashlytics のログは BigQuery にエクスポートが可能です。gcloud CLI を使えば AI に直接 BigQuery 上でクエリを実行させることも可能なのですが、費用面を始めとした様々な懸念があったため、Google Cloud Storage (GCS) に parquet 形式で必要なデータだけエクスポートして開発用端末にダウンロード[1]することにしました。
そして開発用端末で SQL を高速に実行するために DuckDB を採用しました。
Claude Code に BigQuery から GCS に parquet 形式でエクスポートしたいと言えばすぐにスクリプトを書いてくれます。IVRy では多くのチームで mise を使っているのでセットアップ手順はこのような流れで作成してもらいました。
.mise.toml
# .mise.toml
[tools]
duckdb = "latest"
gcloud = "latest"
python = "3.12"
shellcheck = "0.10"
[env]
_.file = [".env", ".env.local"]
# 1. リポジトリをクローン
git clone https://github.com/{your-org}/firebase-analysis.git
cd firebase-analysis
# 2. mise でツールをインストール
mise install
# 3. 環境変数の設定
cp .env.example .env
# .env を編集
# 4. GCP認証
gcloud auth login
gcloud config set project YOUR_PROJECT_ID
# 5. データ同期とインポート
mise run workflow
# 6. サンプルクエリを実行
mise run some-query
スキーマドキュメントの作成
まずは Claude Code に DuckDB の実行方法だけ教えて Firebase Analytics, Crashlytics のログを分析させてドキュメントを拡充します。
この時何度か試行錯誤してコマンドを作っておくと新規ログが増えた際の拡充が捗ります。
コマンド例
Analyze Crashlytics Issue
Firebase Crashlytics の特定 issue を詳細分析し、レポートを自動生成します。
実行方法
/analyze-crashlytics-issue <issue_id> [start_date] [end_date]
例:
/analyze-crashlytics-issue xxxxxxxxxxxx
/analyze-crashlytics-issue xxxxxxxxxxxx 2025-11-05 2025-11-12
引数:
-
issue_id: Firebase Crashlytics の Issue ID(必須) -
start_date: 分析開始日(省略時: 7日前) -
end_date: 分析終了日(省略時: 今日)
📋 分析内容
このコマンドは以下を自動的に分析し、レポートを生成します:
1. 基本情報
- クラッシュ総数
- ユニークデバイス数
- 分析期間
- プラットフォーム(Android/iOS)
2. 詳細メモリ情報
-
総 RAM 容量 =
memory.used + memory.free -
メモリ使用率 =
100 × memory.used / (memory.used + memory.free) -
空きメモリ =
memory.free - RAM 容量別の分布(〜4GB, 4〜6GB, 6〜8GB, 8〜12GB, 12GB〜)
- メモリ使用率の統計(平均、中央値、最小、最大)
3. ストレージ情報
- 空きストレージ容量
- ストレージ使用率
- ストレージ不足のクラッシュ比率
4. デバイス統計
- メーカー別クラッシュ数とメモリ使用率
- デバイスモデル別(上位20件)
- Android/iOS バージョン別
- CPU アーキテクチャ別
- アプリバージョン別(導入バージョン、廃止バージョンの特定)
5. 通話イベント分析(Crashlytics logs に通話ログが含まれる場合)
- 通話タイプ別(発信/着信)
- クラッシュパターン(通話開始時/通話中/通話終了後)
- 通話開始からクラッシュまでの時間統計
6. 共通パターンの抽出
- クラッシュ直前のログパターン
- エラーメッセージの頻度
- 特定のイベントシーケンス
7. 時系列分析
- 日別クラッシュ数
- 時間帯別の傾向
- デバイス別の時系列推移
🔍 分析手順
Step 0: Crashlytics タイトル・サブタイトルの取得
DuckDB から取得:
SELECT issue_title, issue_subtitle
FROM crashlytics_events
WHERE issue_id = '{issue_id}'
LIMIT 1;
Firebase MCP が利用可能な場合:
- MCP の
get_crashlytics_issue関数で Issue タイトルを取得 - MCP の
ask_gemini_consultant関数でクラッシュの概要を取得 - 取得した情報をレポートの冒頭に記載
...省略
例えば Analytics で event_name action_xxx というものがあったとして、以下のような情報がすぐに出てきます。
- どの OS, アプリバージョンでログが存在するか
- どんなパラメーターがありどんな値が入っているか
- 対象ログの内どのくらいの割合か
| 例1 | 例2 |
|---|---|
 |
 |
相互変換用ドキュメント、AGENTS.md の作成
DuckDB, BigQuery, Databricks はそれぞれ SQL の関数が異なります。そのため変換用のドキュメントを作成します。これも事前に違いを調査させた上でまず変換してもらい何度かエラーのやり取りを繰り返して変換ガイドを充実させました。
特に変換が最小限になるように以下の指示をしておくと変換精度が良くなる印象でした。
- テーブルは作成せず、ビューのみを使用すること
- ネスト構造(event_params, device など)を保持すること
- 公式スキーマを厳守すること
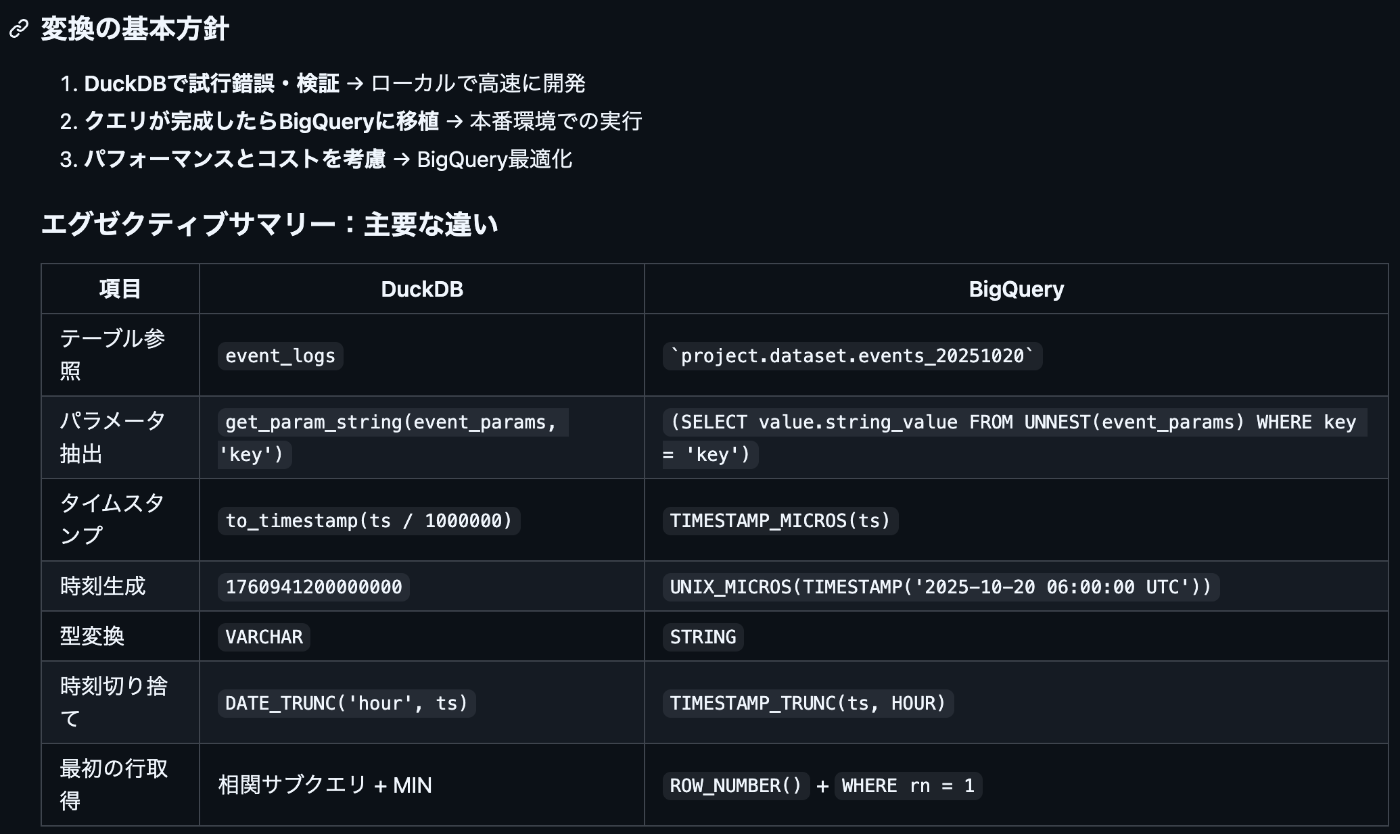
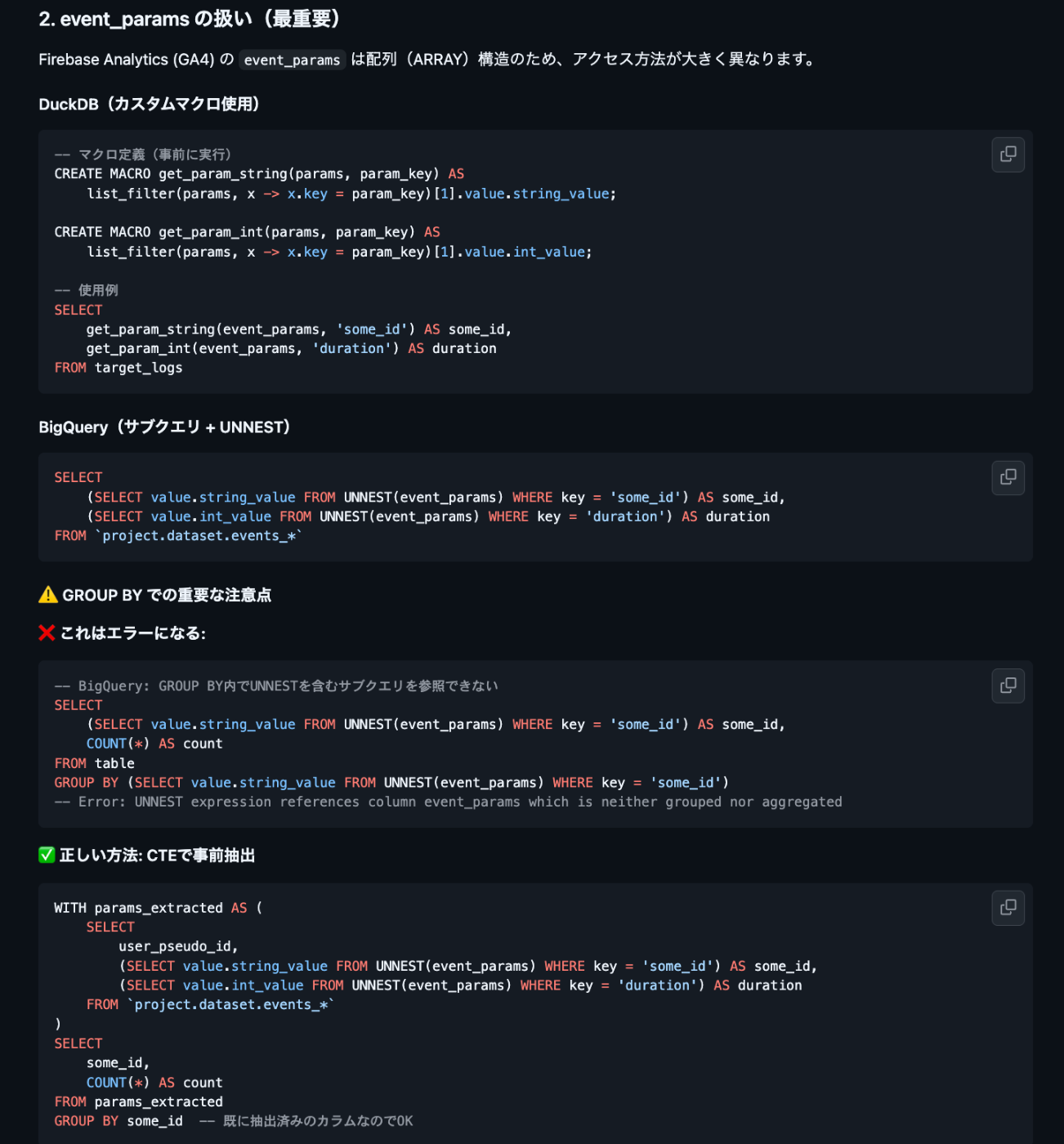
BigQuery 変換ガイドの抜粋
Databricks への変換ガイドも同様に作成します。

Databricks 変換ガイドの冒頭
最後に AGENTS.md や CLAUDE.md 等を書いて全てのドキュメントを読むように指示すれば完成です[2]。
自然言語で分析したい内容を伝えて SQL を作成、ダッシュボード構築
ここまでで Claude Code はモバイルアプリのログ構造を理解しているため自然言語で分析したい内容を伝えるだけで DuckDB で実行した分析結果を出してくれて、更に BigQuery, Databricks 用の SQL も同時に出力されるようになっています。
その SQL を使って Databricks 上で実行してダッシュボードを作成すれば完成です。

分析依頼例
実行の様子
Claude Code が自律的にクエリを発行してデータ構造を確認、分析していることがわかります。


実行結果
サマリーおよび、BigQuery と Databricks 用の SQL が出力されています。



Databricks ならではの使い方
Databricks には ai_query という関数が用意されています。
私はこれを使って Crashlytics の issue_id と installation_uuid でカウントして数が多い組み合わせ(= 同一端末で繰り返し同じ問題が発生)に関してエラーが発生した時にユーザーがどんな操作をしていたか、特徴的なログが出ていないか等毎日分析させて Slack に通知しています。
ai_query すごく便利なので次回また記事にする予定です。
select
ai_query(
'databricks-gemma-3-12b',
concat(
"これはモバイルアプリユーザーの端末から繰り返し送信されたエラーを issue_id, installation_uuid で group by してまとめたログの 1つです。",
"...アイブリー固有の説明は割愛...",
"nested_logs にユーザーイベントのログがあるので issue_title, issue_subtitle を踏まえてユーザーがどのような操作をして、どのような理由で繰り返しこのエラーが発生しているのかを簡潔に教えてください。",
"\n---\n",
"\nissue_title: ", c.issue_title,
"\nissue_subtitle: ", c.issue_subtitle,
"\nnested_logs: ", concat_ws(...)
)
) as ai_summary,
...
from some_crashlytics_logs

通知の例
まとめ
Firebase Analytics, Crashlytics で収集したログの分析で Agentic Coding する方法について紹介しました。
従来であれば時間を要したであろう以下の処理が Claude Code によって正味 2日で作成することができました。
- mise を使った環境構築
- BigQuery から対象ログデータの取得
- Google Cloud Storage (GCS) へのエクスポートスクリプトの作成
- GCS からのダウンロードスクリプトの作成
- DuckDB を AI コーディングツールに操作させてドキュメントの整備
- スキーマドキュメントの作成
- DuckDB, BigQuery, Databricks 用の SQL 相互変換ドキュメントの作成
- AGENTS.md, CLAUDE.md 等の作成
- AI コーディングツールに自然言語で分析したい内容を伝えて出力された SQL からダッシュボードを作成
この記事が同じような課題を抱えている方の参考になれば幸いです。
IVRyでは、Advent Calendarをもう1レーン走らせています。本日は、にしかたさんの「変化の時だから、組織の熱量を可視化したい。IVRy流インタビュー記事の作り方【プロンプト公開】」が公開されました!ぜひご覧ください。
We are hiring!
IVRyでは「イベントや最新ニュース、募集ポジションの情報を受け取りたい」「会社について詳しく話を聞いてみたい」といった方に向けて、キャリア登録やカジュアル面談の機会をご用意しています。ご興味をお持ちいただけた方は、ぜひ以下のページよりご登録・お申し込みください。

Discussion