Phi-3.5-miniを文埋め込み取得向けにファインチューニングして、MAUIを使ってスマホで動かす
この記事は、ポート株式会社 サービス開発部 その2 Advent Calendar 2024の、13日目の記事です。
ポート株式会社でサーバーサイドの開発者として働いている、ito845と申します。今回は、まったく専門ではない、AIとネイティブアプリ開発を題材に、会社での取り組みとは関係がない個人的な記事を書かせていただきました。
記事の概要
以下の内容に取り組み、その過程をまとめて記述したものになります。
- Phi-3.5-miniを文埋め込み取得向けにファインチューニングする
- INT4に量子化したONNX形式のモデルをMAUIを用いて、PC/スマホで動作させる
背景
今年、新卒として入社してから、Webの技術の学習を行ったり、RubyとTypeScriptばかり触っていたりしていたのですが、筋力が衰えないようにC#やPythonも書いておきたくなりました。そこで、以前から気になっていたPhi-3.5-miniで少し遊んでみたいと考え、以下のような内容を思いついて実行に移した次第です。
- Phi-3.5-miniと呼ばれる文章を取り扱うモデルを、文埋め込み取得向けにファインチューニングする
- ファインチューニングしたモデルを、INT4に量子化&ONNX形式に変換し、MAUIを用いてPC/スマホで動作させる
Phi-3.5-miniを文章生成やチャットボットをスマホで動かしてみるような記事は、世の中にたくさん存在していると考えられます。そこで試しに、「文埋め込みの取得向けにファインチューニングする」という、ひと手間を加えようとしました。ファインチューニング自体は中途半端な結果となってしまっていますが、気が向いた際にきちんと学習を回すかもしれません。
Phi 3.5-miniとは
Phi-3.5-miniは、Microsoft社が公開している小規模言語モデル(SLM)の一種です。大規模言語モデル(LLM)と比較すると少ないパラメーターのモデルであることが特徴で、量子化をするとスマートフォンなどの比較的性能が低いハードウェアでも動作するとされています。
名前が似ているモデルとして、マルチモーダル版のPhi-3.5-visionや、MoE版のPhi-3.5-MoEも存在していますが、今回使用するPhi-3.5-miniは、文章を取り扱うモデルとなります。以後、Hugging Face Hubで配布されているモデルの名称に合わせて、Phi-3.5-mini-instructと記載します。
手順
結果的に、以下の手順で目的を達成することができました。取り組む前にきちんと調査していなかったため、所々、力技でなんとかしている箇所があります。
-
Phi-3.5-mini-instructのモデルの構造の確認 - Sentence Transformersを用いた文埋め込み向けのファインチューニング
- 学習結果のモデルの量子化とONNX形式への変換
- 量子化済みのONNX形式のモデルを編集して使用しない部分を削除する
- C#でONNX形式のモデルを動かす簡易的なライブラリの実装
- .NET MAUIでアプリを実装して、PC/スマホにデプロイ
Phi-3.5-mini-instuctのモデルの構造の確認
念のため、文埋め込みの取得向けにファインチューニングができそうか、モデルの構造を確認します。
Hugging Face Hubで公開されている学習済みのモデルのクラスは、Phi3ForCausalLMです。
Phi3ForCausalLMのコンストラクタを見ると、ベースとなるPhi3Modelがあって、それに文章生成向けのヘッドがついているという構造だと推測することができます。Phi3Modelを見ると、forwardが返す内容にlast_hidden_stateが含まれているのでこれを利用することができそうです。
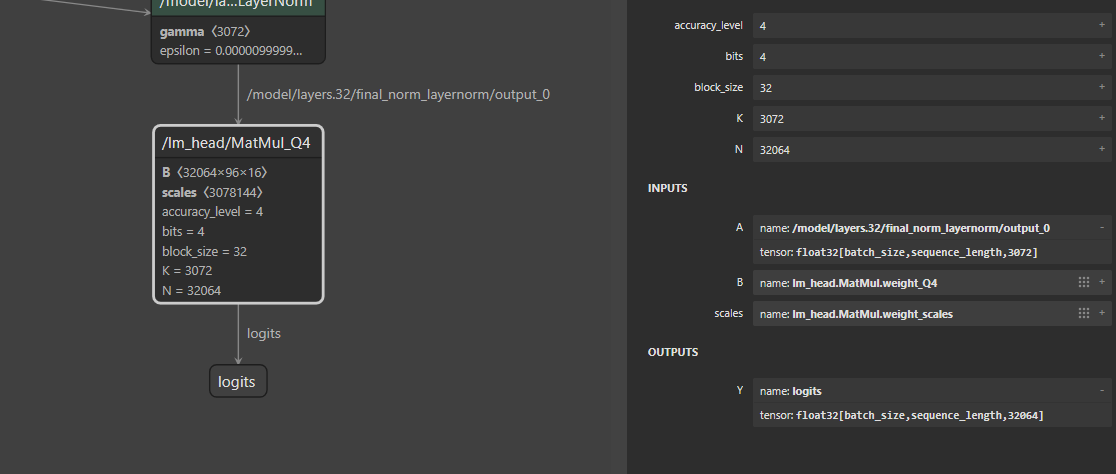
少し順番が前後しますが、量子化されたONNX形式で配布されているモデルの構造も確認します。確認には、Netronを使用します。こちらのページからONNX形式のモデルをダウンロードすることができます。
ダウンロードしてきたモデルをNetronで開いて、画面を下の方にスクロールしていくと、以下のような箇所を確認することができます。logitsを出力しているノードがヘッド部分で、ヘッドに対する入力データがlast_hidden_state相当です。
Sentence Transformersを用いた文埋め込み向けのファインチューニング
文埋め込み(text embedding)とは、文の分散表現や文ベクトルなどとも呼ばれるもので、文章の特徴や意味合いなどを含むベクトルのことを指します。性質の良い文埋め込みであれば、分類タスクに用いたり、コサイン類似度などを計算して文章の類似度を推測することができたりします。
文埋め込みを取得する手法として、Sentence-BERTなどが有名ですが、その学習にはSentece Transformersと呼ばれるライブラリがよく用いられます。今回のファインチューニングでも、Sentence Transformersを用います。
学習は、Google Colaboratoryで実施しました。1000円程度をお支払いしてA100のランタイムを使用しています。ランタイム上では、pipで以下のようなパッケージのインストール/アンインストールを実施しました。バージョンを固定しているのは、2024/12/08時点でバージョンを指定しない形のインストールを行うと、trainメソッドがうまく動作しなかったためです。
pip uninstall wandb -y
pip install transformers==4.45.2 sentence-transformers==3.1.1 datasets
pip install bitsandbytes # load_in_4bitなどを指定する場合
ちなみに、load_in_4bitやload_in_8bitのオプションを指定してモデルを読み込めば、無料のT4のランタイムでも学習を回せそうな雰囲気でした。性能の低下やNaNの発生を引き起こす可能性はありますが、学習後のモデルの重みを移し替えたり、config.jsonを書き換えたりすると、後続のONNX形式への変換も、とりあえず可能かもしれません。
学習コードは以下のような感じです。学習データには、JSNLIデータセットを使用しました。
一口にSentence Transformersでの学習といっても、様々な手法が存在していますが、今回は、MultipleNegativesRankingLossを用いて学習を行っています。
データセットの読み込みは、こちらの記事を参考にしています。
import torch
from sentence_transformers import SentenceTransformer, SentenceTransformerTrainer, SentenceTransformerTrainingArguments, InputExample, losses, models
from sentence_transformers.training_args import BatchSamplers
from datasets import Dataset
from google.colab import drive
import math
import random
drive.mount('/content/drive')
base_path = "/content/drive/MyDrive/phi_train"
train_data_file_path = f"{base_path}/nli_data/jsnli_train.tsv"
dev_data_file_path = f"{base_path}/nli_data/jsnli_dev.tsv"
drive_result_path = f"{base_path}/result"
result_path = drive_result_path
result_path = f"./result" # 今回は、後ほどターミナルで移動させるため、Google Driveのフォルダを出力先としていません。
batch_size = 8
epochs = 1
lr = 2e-05
model_path = "microsoft/Phi-3.5-mini-instruct"
word_embedding_model = models.Transformer(
model_path,
model_args={
"torch_dtype": torch.bfloat16
# "load_in_4bit": True, # FP4でモデルをロードする場合などは、コメントアウト
}
)
pooling_model = models.Pooling(
word_embedding_model.get_word_embedding_dimension(),
pooling_mode="mean") # プーリング層の挙動は適当に選んでいます。
model = SentenceTransformer(modules=[word_embedding_model, pooling_model], device="cuda")
def load_nli_dataset_for_MNRLoss(tsv_path: str):
data_dict: dict[str, dict[str, set]] = {}
def add_to_data_dict(sent1, sent2, label):
if sent1 not in data_dict:
data_dict[sent1] = {"contradiction": set(), "entailment": set(), "neutral": set()}
data_dict[sent1][label].add(sent2)
with open(tsv_path, mode="r", encoding="utf-8") as fp:
for row in fp:
if row.strip() == "":
continue
rows = row.strip().split("\t")
sent1 = rows[1].replace(" ", "")
sent2 = rows[2].replace(" ", "")
label = rows[0].replace(" ", "")
add_to_data_dict(sent1, sent2, label)
add_to_data_dict(sent2, sent1, label)
samples = []
for sent1, others in data_dict.items():
if len(others['entailment']) > 0 and len(others["contradiction"]) > 0:
samples.append({"anchor": sent1, "positive": random.choice(list(others['entailment'])), "negative": random.choice(list(others["contradiction"]))})
samples.append({"anchor": random.choice(list(others['entailment'])), "positive": sent1, "negative": random.choice(list(others["contradiction"]))})
dataset = Dataset.from_list(samples)
dataset = dataset.select_columns(["anchor", "positive", "negative"])
return dataset
training_args = SentenceTransformerTrainingArguments(
output_dir=result_path,
num_train_epochs=epochs,
bf16=True,
fp16=False,
warmup_ratio = 0.1,
per_device_train_batch_size=batch_size,
batch_sampler=BatchSamplers.NO_DUPLICATES,
learning_rate=lr,
max_steps=100, # !!!!!!学習を途中で打ち切っています!!!!!!
save_steps=9000, # len(train_samples) * epochs / batch_sizeが総ステップ数なので、それをもとに適切に設定すると良さそうです。
save_total_limit=1, # 途中で打ち切る前提なので、残すモデルを絞っています。
report_to=None
)
train_samples = load_nli_dataset_for_MNRLoss(train_data_file_path) # 約295000
train_loss = losses.MultipleNegativesRankingLoss(model)
trainer = SentenceTransformerTrainer(
model=model,
args=training_args,
train_dataset=train_samples,
compute_metrics=None,
loss=train_loss,
)
trainer.train() # 学習の実行
# 100ステップで51秒、総ステップは37000くらいなので、1epoch回しきるのに5~6時間程度かかる
今回は時間がなかったため、学習を100ステップで打ち切っています。
そのため、JSTSなどを用いた性能の評価などは実施せず、具体的な性能にも言及しません。
学習結果のモデルの量子化とONNX形式への変換
ONNX Runtime GenAI Model Builderを用いて、学習結果のモデルを量子化して、ONNX形式のモデルとして保存します。詳しい使い方は、こちらのドキュメントを参照してください。
Sentence Transformerで学習した結果のモデルは、config.jsonのarchitecturesがPhi3Modelとなっています。Model Builderは、現時点でPhi3Modelには対応しておらず、Phi3ForCausalLMである必要があったため、config.jsonを書き換えて対応しました。
より丁寧に行うなら、Phi3ForCausalLMのモデルに、学習結果のモデルの重みを移し替えて保存して、それを変換すると良いかもしれません。
今回は、以下のようなコマンドを実行しています。
# pip install onnxruntime_genai onnx
python -m onnxruntime_genai.models.builder -m "./result" -o Phi-3.5-mini-instruct-onnx-cpu-int4 -p int4 -e cpu -c cachedir
変換時のメモリ使用量はかなり多く、30~35GB程度使用されていました。変換後のモデルの保存先には、config.jsonがないため、元になったモデルのフォルダからコピーしておきました。
量子化済みのONNX形式のモデルを編集して使用しない部分を削除する
Phi3ForCausalLMとして、モデルを量子化してONNX形式に変換したため、得られたONNX形式のモデルファイルには余計な部分が存在しています。文埋め込みの向けのモデルとして扱うには、これを削除する必要があります。

今回は以下のようなPythonのコードで、不要の部分の削除と、last_hidden_stateという名称の出力の追加を行いました。
(このコードは不完全で、ヘッド部分のweightやbiasを削除することができていません。)
import onnx
from onnx import helper, TensorProto
model = onnx.load("model.onnx")
graph = model.graph
# logitsを削除
new_outputs = [out for out in graph.output if out.name != "logits"]
graph.ClearField('output')
graph.output.extend(new_outputs)
# /lm_head/MatMul_Q4ノードの削除
new_nodes = []
for node in graph.node:
if node.name != "/lm_head/MatMul_Q4":
new_nodes.append(node)
graph.ClearField('node')
graph.node.extend(new_nodes)
# /model/layers.32/final_norm_layernorm/SkipLayerNormの出力をlast_hidden_stateに変更
for node in graph.node:
for i, out_name in enumerate(node.output):
if out_name == '/model/layers.32/final_norm_layernorm/output_0':
node.output[i] = "last_hidden_state"
last_hidden_state_output = helper.make_tensor_value_info(
"last_hidden_state",
TensorProto.FLOAT,
["batch_size", "sequence_length", 3072]
)
graph.output.extend([last_hidden_state_output])
# モデルファイルの保存
onnx.save(model, "modified_model.onnx", save_as_external_data=True, all_tensors_to_one_file=True, location="modified_model.onnx.data", size_threshold=0, convert_attribute=False)
C#でONNX形式のモデルを動かす簡易的なライブラリの実装
Phi3ForCausalLMを変換したモデルなどを文章生成に利用するのであれば、Microsoft.ML.OnnxRuntimeGenAIを利用することで、簡単に文章生成の処理を実装することが可能です。今回は、モデルの構造に手を加えており、用途も変えているため、ある程度独自の実装を行う必要があります。
ONNX形式のモデルの実行自体は、Microsoft.ML.OnnxRuntime を用いることで簡単に行うことが可能です。
文章をモデルの入力に必要なトークンのID列に変換するトークナイザの処理は、Microsoft.ML.TokenizersのLlamaTokenizerを利用することができます。
また、モデルの出力を最終的な文埋め込みに変換する、プーリング相当の処理は、通常のリストの操作で雑に実装します。
空のソリューションに、.NET 8.0をターゲットとしたクラスライブラリのプロジェクトを作成して、必要なNugetパッケージを導入し、以下のようなコードを実装しました。
using Microsoft.ML.OnnxRuntime;
using Microsoft.ML.OnnxRuntime.Tensors;
using Microsoft.ML.Tokenizers;
using System.Text.Json;
namespace PhiEmbeddingLib
{
public class PhiEmbeddingModel
{
public LlamaTokenizer Tokenizer { get; }
private InferenceSession Model { get; }
public int MaxSequenceLength { get; private set; } = 4096;
private int PadTokenId { get; set; } = 32000;
private int HiddenSize { get; set; } = 3072;
private int NumKeyValueHeads { get; set; } = 32;
private int NumAttentionHeads { get; set; } = 32;
public PhiEmbeddingModel(string onnxModelPath, string modelDirPath)
{
LoadConfig(modelDirPath);
Tokenizer = CreateLlamaTokenizer(modelDirPath);
Model = new InferenceSession(onnxModelPath);
}
public List<List<float>> GetTextEmbeddings(IReadOnlyList<string> texts)
{
// ID列への変換と、最大の系列長の取得
int batchSize = texts.Count;
int maxSequenceLength = 0;
var idsList = new List<List<int>>();
foreach (var text in texts)
{
var ids = Tokenizer.EncodeToIds(text).ToList();
idsList.Add(ids);
maxSequenceLength = (ids.Count > maxSequenceLength)
? ids.Count : maxSequenceLength;
}
maxSequenceLength = (maxSequenceLength > MaxSequenceLength)
? MaxSequenceLength : maxSequenceLength;
// 最大の系列長の長さに合わせたパディングと、各データのAttentionMaskの作成
var attentionMasks = new List<List<int>>();
var sequenceLengthList = new List<int>();
foreach (var _ids in idsList)
{
var ids = _ids;
if (ids.Count > MaxSequenceLength)
{
ids = ids[..MaxSequenceLength].ToList();
}
int sequenceLength = ids.Count;
ids.AddRange(Enumerable.Repeat(PadTokenId, maxSequenceLength - sequenceLength));
var attentionMask = Enumerable.Repeat(1, sequenceLength).ToList();
attentionMask.AddRange(Enumerable.Repeat(0, maxSequenceLength - sequenceLength));
attentionMasks.Add(attentionMask);
sequenceLengthList.Add(sequenceLength);
}
// 今まで用意してきたデータを使い、モデルへの入力データを作成
var inputs = CreateOnnxInputsBase(batchSize, NumKeyValueHeads, HiddenSize / NumAttentionHeads);
inputs.Add(NamedOnnxValue.CreateFromTensor("input_ids", ConvertToTensor(idsList)));
inputs.Add(NamedOnnxValue.CreateFromTensor("attention_mask", ConvertToTensor(attentionMasks)));
var modelOutputs = Model.Run(inputs); // 推論の実行
// モデルの出力データの処理
var lastHiddenState = new List<List<List<float>>>(batchSize);
foreach (var output in modelOutputs)
{
if (output.Name == "last_hidden_state")
{
// Tensorを入れ子のリストに変換
var flatOutput = ((IEnumerable<float>)output.Value).ToList();
int jLimit = maxSequenceLength * HiddenSize;
for (int i = 0; i < flatOutput.Count; i += maxSequenceLength * HiddenSize)
{
var innerList = new List<List<float>>(maxSequenceLength);
for (int j = 0; j < jLimit; j += HiddenSize)
{
innerList.Add(flatOutput.GetRange(i + j, HiddenSize));
}
lastHiddenState.Add(innerList);
}
}
}
// [batchSize,sequenceLength,hiddenSize]が、 [batchSize,hiddenSize]になるように平均を計算すればよいだけなので省略します。
return Pooling.MeanPooling(lastHiddenState, sequenceLengthList, HiddenSize);
}
private LlamaTokenizer CreateLlamaTokenizer(string tokenizerDirPath)
{
string modelPath = Path.Combine(tokenizerDirPath, "tokenizer.model");
string addedTokensPath = Path.Combine(tokenizerDirPath, "added_tokens.json");
var specialTokens = JsonSerializer.Deserialize<Dictionary<string, int>>(File.ReadAllText(addedTokensPath));
var tokenizer = LlamaTokenizer.Create(
new StreamReader(modelPath).BaseStream, specialTokens: specialTokens
);
return tokenizer;
}
private void LoadConfig(string modelDirPath)
{
string configPath = Path.Combine(modelDirPath, "config.json");
var config = JsonSerializer.Deserialize<Dictionary<string, JsonElement>>(File.ReadAllText(configPath));
HiddenSize = config.TryGetValue("hidden_size", out var hiddenSizeElement) && hiddenSizeElement.TryGetInt32(out var hiddenSize) ? hiddenSize : 3072;
NumKeyValueHeads = config.TryGetValue("num_key_value_heads", out var numKeyValueHeadsElement) && numKeyValueHeadsElement.TryGetInt32(out var numKeyValueHeads) ? numKeyValueHeads : 32;
NumAttentionHeads = config.TryGetValue("num_attention_heads", out var numAttentionHeadsElement) && numAttentionHeadsElement.TryGetInt32(out var numAttentionHeads) ? numAttentionHeads : 32;
PadTokenId = config.TryGetValue("pad_token_id", out var padTokenIdElement) && padTokenIdElement.TryGetInt32(out var padTokenId) ? padTokenId : 32000;
MaxSequenceLength = config.TryGetValue("original_max_position_embeddings", out var maxPosElement) && maxPosElement.TryGetInt32(out var maxPos) ? maxPos : 4096;
}
private static Tensor<float> CreateDummyPastKV(int batchSize, int numKeyValueHeads, int headHiddenSize)
{
return new DenseTensor<float>([batchSize, numKeyValueHeads, 0, headHiddenSize]);
}
private static List<NamedOnnxValue> CreateOnnxInputsBase(int batchSize, int numKeyValueHeads, int headHiddenSize)
{
var input = new List<NamedOnnxValue>();
for (int i = 0; i < numKeyValueHeads; i++)
{
input.Add(NamedOnnxValue.CreateFromTensor($"past_key_values.{i}.key", CreateDummyPastKV(batchSize, numKeyValueHeads, headHiddenSize)));
input.Add(NamedOnnxValue.CreateFromTensor($"past_key_values.{i}.value", CreateDummyPastKV(batchSize, numKeyValueHeads, headHiddenSize)));
}
return input;
}
private static Tensor<long> ConvertToTensor(IReadOnlyList<IReadOnlyList<int>> input)
{
var maxCount = input.Max(x => x.Count);
Tensor<long> tensor = new DenseTensor<long>([input.Count, maxCount]);
for (int i = 0; i < input.Count; i++)
{
for (int j = 0; j < input[i].Count; j++)
{
tensor[i, j] = input[i][j];
}
}
return tensor;
}
}
}
モデルの入力データとして、input_idsとattention_maskのほかに、past_key_value.*を渡す必要があります。とりあえず動けば良いので、今回はこれを適当な空配列相当の入力データとしています。
.NET MAUIでアプリを実装して、PC/スマホにデプロイ
.NET MAUIとは、C#とXAMLでネイティブアプリを実装するためのフレームワークです。1つのコードベースから、Windows/macOS/Android/iOS向けのアプリを作成することができます。
今回は、とても単純な、2つ文章の類似度を計算して表示するだけのアプリを実装しようと思います。
先ほどのソリューションに、新たにMAUIのプロジェクトを追加して、アプリを実装していきます。
また、先ほど実装したライブラリをプロジェクト参照に追加します。これにより、MAUIから先ほど実装したモデルを動かす処理を利用することが可能です。もちろん、MAUIのプロジェクトの中にライブラリに実装したようなコードを直接実装しても問題ありません。
ONNX形式のモデルファイルなどの取り扱いについて
今回実装した、文埋め込み取得を行うクラスには、モデルファイルのパスやモデルのディレクトリのパスを渡す必要があります。つまり、モデルファイルを、デプロイ先のファイルシステム上の適切なディレクトリに配置する必要がある、ということになります。
MAUIでは、Resources/Rawのディレクトリ以下に存在するファイルをアセットとしてアプリのパッケージに含めることが可能です。パッケージに含めたファイルを、アプリのキャッシュのディレクトリに展開することで、モデルファイルの配置を実現します。
ここで発生した問題として、モデルファイルが2GBを超えているため、分割する必要があったことが挙げられます。今回は、以下のようなPythonのコードでモデルファイルを分割して、Resources/Raw以下に配置しました (splitコマンドなどで分割しても問題ありません)
def split_file(file_path, chunk_size=512*(1024**2)): # 512MB
with open(file_path, 'rb') as f:
part_num = 0
while True:
chunk = f.read(chunk_size)
if not chunk:
breakl
output_file = f"{file_path}.part{part_num}"
with open(output_file, 'wb') as out_f:
out_f.write(chunk)
part_num += 1
split_file("modified_model.onnx.data")

アプリ起動時に、以下のようなコードを実行することで、パッケージからモデルファイルなどを展開します。分割したファイルはこの時点で結合するようにしました。
// 省略 (MauiProgram.csのCreateMauiAppメソッドから呼び出す関数)
var fileList = ModelFileNames;
foreach (var file in fileList)
{
string destFilePath = Path.Combine(DestDirPath, file);
if (File.Exists(destFilePath))
{
continue;
}
using var inputStream = FileSystem.OpenAppPackageFileAsync(file).Result;
using var outputStream = File.Create(destFilePath);
inputStream.CopyTo(outputStream);
}
var partFileList = SplitModelDataFileNames;
var mergedFileOutputPath = Path.Combine(DestDirPath, MergedModelDataFileName);
if (!File.Exists(mergedFileOutputPath))
{
using var outputStream = File.Create(mergedFileOutputPath);
foreach (var partFile in partFileList)
{
using var inputStream = FileSystem.OpenAppPackageFileAsync(partFile).Result;
inputStream.CopyTo(outputStream);
}
}
// 省略
Androidのスマートフォンでアプリを動かしたり、デバッグしたい場合、USBでPCとスマホを接続してスマホ側でデバッグモードを有効にし、Visual Studio上から対象を選択して、実行もしくはデバッグを開始すればアプリをスマホ上で動かすことができます。
今回は、パッケージに含めるアセットのファイル容量が大きいためか、ビルドには1時間以上の時間がかかってしまいました。何かしら工夫を行い、ビルド時間を短縮する必要がありそうです。
動作確認
最終的に出来上がったアプリは以下の図のようなものになります。テキストを文埋め込みに変換する処理を2回行って、その結果得られたベクトルのコサイン類似度を計算して表示しています。
| PC (Windows 10) | スマートフォン (Android 13) |
|---|---|
 |
 |
 |
 |
今回はAndroidアプリの動作の確認に、Xperia 10 IIIを使用しました。これは2021年に発売されたミドルレンジのスマートフォンです。短い単語程度の文章の場合、類似度を計算するまで5~6秒程度、長い文章の場合は数十秒の時間が必要でした。今現在発売されているミドルレンジ以上のスマートフォンでは、もっと高速に動作させることができるはずです。
これで、当初想定していた、Phi-3.5-mini-instructを量子化してPC/スマホで動かすといったことを実現することができました。SQLiteやLiteDBを用いて推論済みの文埋め込みを格納できるようにしたり、モデルの推論回数を少なくしたり、推論を工夫して高速化することができれば、さらに面白いアプリが実装できるかもしれません。
まとめ
この記事では、Phi-3.5-mini-instructの学習から、ONNX形式への変換、MAUIを用いたアプリの実装までを説明しました。
今回の実装を通して、以下の3点を学ぶことができました。
-
Phi-3.5-mini-instructなどの、パラメーター数が3.8b程度の大きさのモデルであれば、比較的気軽にファインチューニングを行うことができる - 元が3.8b程度の大きさのモデルでも、INT4程度まで量子化すれば、古めのスマホ上でも動作させることができる
- ONNX形式のモデルファイルと、前処理/後処理の実装を用意することができれば、MAUIとONNX Runtimeを用いて機械学習のモデルを搭載したクロスプラットフォームのアプリを実装することができる
今後、続きを実施するとしたら、以下の内容に取り組みたいと考えています。
- ファインチューニングを1 epoch程度は実施し、JSTSのスコアを確認する
- Sentence Transformersのプーリング層で他のモードを試す
- ONNX形式のモデルに対する削除操作で、不要な重みを削除できるようにする
- MAUIアプリのアセットにモデルファイルを含めるための、より適切な方法を探す
悩みながらC#やPythonを書くことができ、当初考えていたことがある程度実現できたため、個人的には大満足でした。
ファインチューニングの続きについては、あまり期待せずにお待ちいただければと思います。また、今回実装したアプリのソースコードの公開につきましては、反響がありましたら前向きに検討させていただきます。
ポート株式会社 サービス開発部が実施している今年のアドベントカレンダーは、その1とその2が存在します。私が参加しているアドベントカレンダーその2の次回の投稿は、16日のCanoさんの記事となります。また、アドベントカレンダーその1の方は明日も投稿があり、 kojima さんが記事を投稿されるそうです。そちらの方も、ぜひご覧ください。
Discussion