AIはギターの音色を聞き分けることができるのか
はじめに
筆者はAIの専門家ではありません
ギターを趣味としている方なら通じる話ですが、エレキギターにはモデルごとに音色のキャラクターが存在します。
このギターはいかにもストラトキャスターらしい音がする、テレキャスターの中にはレスポールのように太い音がする個体が存在する。
ビンテージギターの音は現行品には出せない。
詳しい人であれば目隠しでもある程度機種の特定ができる。
私もギターに関しては人並み以上に没頭してきた人間ですが、ストラトらしさ、レスポールらしさ、というものがわかってきた一方で時には胡散臭いと感じる時もありつつ、といった肌感覚です。
以前からAIでギターの音色とか判定できないのかな、と思っていたのでやってみました。
ギターの音色を区別させる題材
※この章はギターに詳しくない人向けの説明です、読み飛ばしても問題ありません
エレキギターのモデルとして代表的な2機種が存在します。
wikipediaより画像を拝借


この2機種はエレキギターのシェアをこの2機種だけで半分以上占める程度には代表的な存在です。
メーカーから異なる以上、2機種のギターは設計、部品から大きく異なり、
レスポールの音色をストラトキャスターで出すことはできず、逆も然りです。
どちらかのギターを所有している人であれば、音だけでもどちらがレスポールでどちらがストラトキャスターであるかを判断することができるでしょう。
具体的には、レスポールは本体重量が重く、弦振動を電気信号に変換するパーツであるピックアップが、ノイズが少なく高出力である代わりに、高域成分が落ちやすい種類のものを利用しているため、タイトで太いサウンドに。
一方ストラトキャスターは全体的に軽量でネックとボディがネジ止めされているという構造が弦振動に影響を与え、ピックアップの構造もノイズ対策が無い分高域がスポイルされず、倍音成分が豊かで煌びやかなサウンドになる傾向があります。
この2機種のギターを演奏した音声をAIに識別させてみます。
AIを実装する
おそらく発話者識別の技術をそのまま横展開すれば可能であろうという予想をしていました。
簡単な実装で発話者識別を実装しているサンプルが無いかなと思ったところ下記の記事を発見しました。
70行弱で書ける!音声データから話者を当てる人工知能を作ってみた!
わかりやすいですね、素晴らしい。
特に工夫することなくそのまま利用できたので、実装の内容は変数名を変更した程度で同じです、ありがとうございます、そしてすみません。
というわけでコードは下記の内容です、丸パクリなので問題があれば削除します。
# import libraries
import scipy.io.wavfile as wav # .wavファイルを扱うためのライブラリ
from sklearn.svm import SVC # SVC(クラス分類をする手法)を使うためのライブラリ
import numpy # ndarray(多次元配列)などを扱うためのライブラリ
import librosa # 音声信号処理をするためのライブラリ
import os # osに依存する機能を利用するためのライブラリ
# ルートディレクトリ
ROOT_PATH = 'drive/MyDrive/data/'
# ギターの種類(データのディレクトリ名になっている)
guitars=['LP', 'ST']
sound_training=[] # 学習用のFCCの値を格納する配列
guitar_training=[] # 学習用のラベルを格納する配列
def getMfcc(filename):
y, sr = librosa.load(filename) # 引数で受けとったファイル名でデータを読み込む。
return librosa.feature.mfcc(y=y, sr=sr) # MFCCの値を返します。
# 各ディレクトリごとにデータをロードし、MFCCを求めていく
for guitar in guitars:
# どのギターのデータを読み込んでいるかを表示
print('data of %s...' % guitar)
# ギターの種類でディレクトリを作成しているため<ルートパス+ギター名>で読み込める。
path = os.path.join(ROOT_PATH + guitar)
print('path = %s' % path)
# パス、ディレクトリ名、ファイル名に分けることができる便利なメソッド
for pathname, dirnames, filenames in os.walk(path):
for filename in filenames:
# macの場合は勝手に.DS_Storeやらを作るので、念の為.wavファイルしか読み込まないようにします。
if filename.endswith('.wav'):
mfcc=getMfcc(os.path.join(pathname, filename))
sound_training.append(mfcc.T) # sound_trainingにmfccの値を追加
label=numpy.full((mfcc.shape[1] ,),
guitars.index(guitar), dtype=numpy.int) # labelをguitarsのindexで全て初期化
guitar_training.append(label) # guitar_trainingにラベルを追加
sound_training=numpy.concatenate(sound_training) # ndarrayを結合
guitar_training=numpy.concatenate(guitar_training)
# カーネル係数を1e-4で学習
clf = SVC(C=1, gamma=1e-4) # SVCはクラス分類をするためのメソッド
clf.fit(sound_training, guitar_training) # MFCCの値とラベルを組み合わせて学習
print('Learning Done')
counts = [] # predictionの中で各値(予測される話者のインデックス)が何回出ているかのカウント
file_list = [] # file名を格納する配列
# 各ギターのテストデータが入っている~testというディレクトリごとにMFCCを求めていく
for guitar in guitars:
path = os.path.join(ROOT_PATH + '%stest' % guitar)
print(path)
for pathname, dirnames, filenames in os.walk(path):
for filename in filenames:
if filename.endswith('.wav'):
mfcc = getMfcc(os.path.join(pathname, filename))
prediction = clf.predict(mfcc.T) # MFCCの値から予測した結果を代入
# predictionの中で各値(予測される話者のインデックス)が何回出ているかをカウントして追加
counts.append(numpy.bincount(prediction))
file_list.append(filename) # 実際のファイル名を追加
print(file_list)
total = 0 # データの総数
correct = 0 # 正解の数
# 推測されるギターの名前がファイル名の頭と一致したらCorrect
for filename, count in zip(file_list, counts):
total += 1
result = guitars[numpy.argmax(count-count.mean(axis=0))]
if filename.startswith(result):
correct += 1
print('correct: ' + str(correct) + '/' + str(total))
print('score : ' + str(correct / total))
データを用意する
私は同じ種類のギターを何本も持っているタイプではないのでyoutube動画から拝借します。
比較的クリーンサウンドのデモ動画を探し、私の独断と偏見でこれはいかにもレスポール、ストラトであると評価できる素材を選定しました。
下記のリンクのギターの音声を数秒単位で切って学習データ、テストデータにしました。
学習、判定させてみる
この2本のギターをLP、STのラベルで整理したwavファイルとして用意します。
試しに学習データ20件、テストデータ5件で試してみました。
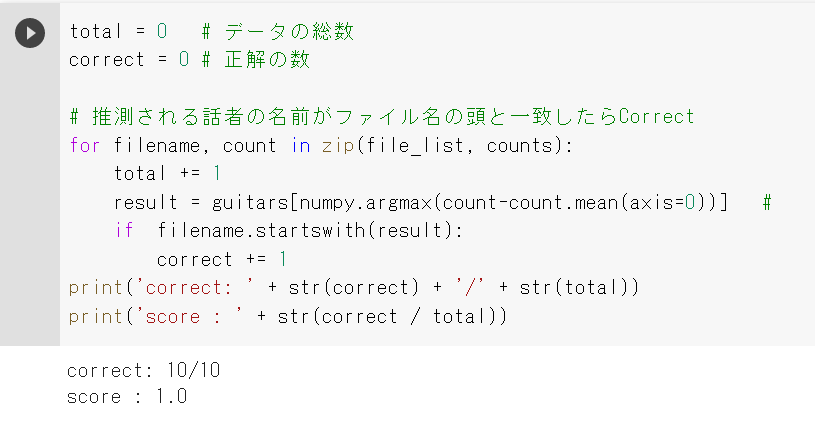
100%の精度で正解しました。

試しにレスポールの音声をストラトキャスターのテスト音声にわざと混ぜてみましたが、きちんとレスポールと判断しスコアが落ちました。
別のギターを判定させてみる
別の個体、別の環境で録音させたストラトキャスター、レスポールの音声をテストデータに5件ずつ、計10件追加してみます。

スコアが著しく悪化しました。
1本のギターだけで学習させるとやはり過学習に陥るようです。
上記2本のデータを20件ずつ、学習データにも混ぜました。

これにより、ストラトキャスター1、またはストラトキャスター2の場合はSTのラベルが、
レスポール1、またはレスポール2の場合はLPのラベルが正解ラベルになるという、通常の人間の発話者推論とは異なるデータの使い方になります。
この状態で3本目のストラトキャスターをテストデータに追加します。

3本目のストラトキャスターは学習データに詰めていませんが見事全問正解しました。
個人でサッと用意できるレベルのデータ量であるため、データセットや実装の内容によって結果は変わるかもしれませんが、簡単な実験でギターの音色をAIで判定させることができました。
今回の実験結果としては、AIはギターの音色を区別できる、という結論で本記事を終了したいと思います。
続編、AIはヴィンテージギターを区別できるのか
製造から30年以上経過したあたりから、とりわけ1950年~1960年代のエレキギターはヴィンテージと呼ばれ、高級車からマンションくらいの値段で取引されています。
本当に世界に1本しか残ってないくらいのレアなモデルになると東京都内の高級住宅街に一軒家を複数建てることができるくらいの値段になります。
希少価値としては納得がいきますが、エレキギターの音色の世界で最もホットで胡散臭い話は、ヴィンテージギターのサウンドは現行品では出せないという理論です。(暴論)
木材が違う、塗装が違う経年劣化は真似できない、ヴィンテージギターの音の良さをそれっぽく理論立てた話は諸説あります。
しかし、古い木材で極薄のラッカー塗装をしても再現できないのか。
ビンテージギターでも容赦なくはんだ付けをやり直しているのはアリなのか。
個人的にはどうあがいても再現不能というのは論理的ではないので懐疑的です。
上記のAIによってヴィンテージギターと生後間もないギターを比べてみましょう。
ヴィンテージギターはこちらの2機種を
現行品はこちらの2機種を選定しました。
ヴィンテージをV、現行品をM(modern)のラベルとします。
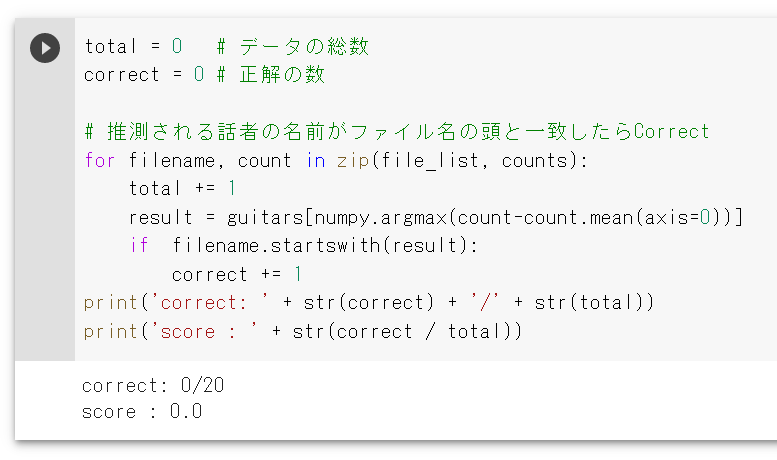
まずは、全ての個体差を判定させましたが、AIで区別する事ができなくなりました。

4本のギターをそれぞれ区別させましたが、スコアが0点になりました。
ヴィンテージギター同士の比較も0点です。


これはこのAIとデータ量の限界か...と思いましたが。


2本ずつのギターをヴィンテージチーム、現行品チームで混ぜて学習させたところ全問正解しました、マジかよ...
1本あたりの学習データが増えたことによる性能改善かもしれません。
ということで、ヴィンテージギター1と現行品1を混ぜたチーム、VM01と、もう一方のVM02にチーム分けしました。

0点です...
指板材などスペックの問題を組み替えると別の答えが出るかもしれません。
ヴィンテージギター1と現行品2を混ぜたチーム、VM03、残りのVM04を作りました。


0点ではないか...
ちょっと信じがたいのですが、今回投入したデータでは、ストラトキャスター同士の比較の難易度は明らかに上がっているものの、ヴィンテージギターと現行品の対比で学習させた場合は正解できる特徴量を学習できるという結果になりました。
ヴィンテージギターの魔法はあるのかもしれません、信じるか信じないかは、あなた次第です。
Discussion