【Stable Diffusion】Diffusersでファインチューニング
ついにDiffusersでモデルのファインチューニングが可能になったので、試しに動かしてみました。
Diffusersとは?
AI画像生成でおなじみのStable Diffusionを手軽に扱う事を可能にするライブラリです。
(APIトークンの取得などを済ませれば)これだけの記述でテキストからの画像生成が可能になります。
import torch
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, revision="fp16")
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("test.png")
基本的な使いかたについては割愛します。
ファインチューニングが可能になった
これまで、ファインチューニングを行うには元々のstable diffsuionを扱うのが一般的でしたが。
Diffusersでもファインチューニングを可能とするスクリプトが公開されました。
このPRで追加されたスクリプトを実行して、生成されたモデルを利用するだけです。
なおメモリ24GB以上のGPUでないと学習途中で落ちます。
Google Colabであれば、月額1000円程度の課金で学習スクリプトが動く性能のマシンを利用することができます。
ローカル環境でGPUに20万円以上を出すことを思えばお買い得ですね。

無課金でもメモリ16GB程度まで性能を上げることができますが、そのスペックでは落ちました。
ファインチューニングを試してみる
今回はHugging Faceに転がっているGazoche/gundam-captionedで試してみます。
(なお執筆時点でデータセットの投稿者本人による学習済モデルが公開されています。
Google ColabのProプランで5時間程度の学習時間を要しましたが、無事に学習できました。
元々のデータセットのプロンプトの内容に則り、A robot~と指示すると、それっぽい画像が生成されます。

"A robot, humanoid, futuristic, red and gray"
元のデータセットの同じプロンプトの画像はこちらです、

しっかり抽象化できていることが確認できます。
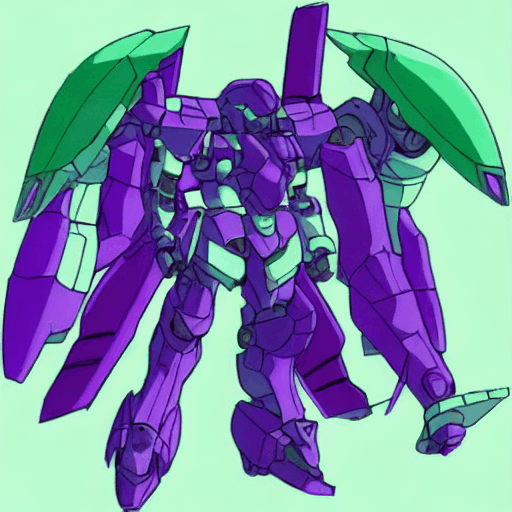
"A robot, humanoid, futuristic, purple and green"

"A robot, humanoid, futuristic, white and blue and red"
正統派なガンダムの色を指定すると完全にガンダムになりました。
右側に謎のオブジェクトが生成されますが。

"A robot, GUNDAM"
ストレートにガンダムを描かせたらだいぶゴツくなりました。

"A robot like a dog"
ベースは汎用のstable diffusionのため、専門知識の幅を超えるものを出そうとすると想定外の出力が出てきます。
Google Colab上での動かし方
Google Colabでは、提供された学習スクリプトはそのまま動きません。
通常スクリプトの実行時に指定するオプション引数を、あらかじめコード上に記載しておくカスタマイズが必要です。
Google Colab上にコピペできるように実際のコードを記載します。
学習以外にも便利なスニペットを含めておきます。
まずはマシンスペックを確認するワンライナーです。
!nvidia-smi
下記のような出力が得られます。
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 A100-SXM4-40GB Off | 00000000:00:04.0 Off | 0 |
| N/A 26C P0 44W / 400W | 0MiB / 40536MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
ここでマシンスペックが低い場合は、ランタイム>ランタイムの変更からハイメモリのランタイムを選択し、ランタイムの接続を解除して繋ぎなおしましょう。
なお執筆時点では無課金で24GBメモリが割り当てられることはありません。
必要なライブラリをインストールします。
!pip install diffusers==0.4.1 accelerate torchvision transformers>=4.21.0 ftfy tensorboard modelcards datasets bitsandbytes
Hugging Faceにノートブック上でログインします
from huggingface_hub import notebook_login
notebook_login()
コマンドライン引数で指定するべきオプションをコードで指定します。
dataset_name、output_dirなどを適宜変更してください。
class args():
def __init__(self):
self.pretrained_model_name_or_path = "CompVis/stable-diffusion-v1-4"
self.dataset_name = "Gazoche/gundam-captioned"
self.dataset_config_name = None
self.train_data_dir = None
self.image_column = None
self.caption_column = "text"
self.max_train_samples = None
self.output_dir = "sd-model-gundam-captioned"
self.cache_dir = None
self.seed = 512
self.resolution = 512
self.center_crop = True
self.random_flip = True
self.train_batch_size = 1
self.num_train_epochs =100
self.max_train_steps = 15000
self.gradient_accumulation_steps = 4
self.gradient_checkpointing = True
self.learning_rate = 1e-05
self.scale_lr = False
self.lr_scheduler = "constant"
self.lr_warmup_steps = 0
self.use_8bit_adam = None
self.use_ema = True
self.adam_beta1 = 0.9
self.adam_beta2 = 0.999
self.adam_weight_decay = 1e-2
self.adam_epsilon = 1e-08
self.max_grad_norm = 1.0
self.push_to_hub = None
self.hub_token = None
self.hub_model_id = None
self.logging_dir = "logs"
self.mixed_precision = "fp16"
self.report_to = "tensorboard"
self.local_rank =-1
args = args()
学習の中心部分です。
なお学習内容を保存したい場合はGoogle Driveをマウントし、モデルの保存先をMyDriveにしておきましょう。
import argparse
import logging
import math
import os
import random
from pathlib import Path
from typing import Iterable, Optional
import numpy as np
import torch
import torch.nn.functional as F
import torch.utils.checkpoint
from accelerate import Accelerator
from accelerate.logging import get_logger
from accelerate.utils import set_seed
from datasets import load_dataset
from diffusers import AutoencoderKL, DDPMScheduler, PNDMScheduler, StableDiffusionPipeline, UNet2DConditionModel
from diffusers.optimization import get_scheduler
from diffusers.pipelines.stable_diffusion import StableDiffusionSafetyChecker
from huggingface_hub import HfFolder, Repository, whoami
from torchvision import transforms
from tqdm.auto import tqdm
from transformers import CLIPFeatureExtractor, CLIPTextModel, CLIPTokenizer
logger = get_logger(__name__)
def parse_args():
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
if env_local_rank != -1 and env_local_rank != args.local_rank:
args.local_rank = env_local_rank
# Sanity checks
if args.dataset_name is None and args.train_data_dir is None:
raise ValueError("Need either a dataset name or a training folder.")
return args
def get_full_repo_name(model_id: str, organization: Optional[str] = None, token: Optional[str] = None):
if token is None:
token = HfFolder.get_token()
if organization is None:
username = whoami(token)["name"]
return f"{username}/{model_id}"
else:
return f"{organization}/{model_id}"
dataset_name_mapping = {
"Gazoche/gundam-captioned": ("image", "text"),
}
# Adapted from torch-ema https://github.com/fadel/pytorch_ema/blob/master/torch_ema/ema.py#L14
class EMAModel:
"""
Exponential Moving Average of models weights
"""
def __init__(self, parameters: Iterable[torch.nn.Parameter], decay=0.9999):
parameters = list(parameters)
self.shadow_params = [p.clone().detach() for p in parameters]
self.decay = decay
self.optimization_step = 0
def get_decay(self, optimization_step):
"""
Compute the decay factor for the exponential moving average.
"""
value = (1 + optimization_step) / (10 + optimization_step)
return 1 - min(self.decay, value)
@torch.no_grad()
def step(self, parameters):
parameters = list(parameters)
self.optimization_step += 1
self.decay = self.get_decay(self.optimization_step)
for s_param, param in zip(self.shadow_params, parameters):
if param.requires_grad:
tmp = self.decay * (s_param - param)
s_param.sub_(tmp)
else:
s_param.copy_(param)
torch.cuda.empty_cache()
def copy_to(self, parameters: Iterable[torch.nn.Parameter]) -> None:
"""
Copy current averaged parameters into given collection of parameters.
Args:
parameters: Iterable of `torch.nn.Parameter`; the parameters to be
updated with the stored moving averages. If `None`, the
parameters with which this `ExponentialMovingAverage` was
initialized will be used.
"""
parameters = list(parameters)
for s_param, param in zip(self.shadow_params, parameters):
param.data.copy_(s_param.data)
def to(self, device=None, dtype=None) -> None:
r"""Move internal buffers of the ExponentialMovingAverage to `device`.
Args:
device: like `device` argument to `torch.Tensor.to`
"""
# .to() on the tensors handles None correctly
self.shadow_params = [
p.to(device=device, dtype=dtype) if p.is_floating_point() else p.to(device=device)
for p in self.shadow_params
]
args = parse_args()
logging_dir = os.path.join(args.output_dir, args.logging_dir)
accelerator = Accelerator(
gradient_accumulation_steps=args.gradient_accumulation_steps,
mixed_precision=args.mixed_precision,
log_with=args.report_to,
logging_dir=logging_dir,
)
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
# If passed along, set the training seed now.
if args.seed is not None:
set_seed(args.seed)
# Handle the repository creation
if accelerator.is_main_process:
if args.push_to_hub:
if args.hub_model_id is None:
repo_name = get_full_repo_name(Path(args.output_dir).name, token=args.hub_token)
else:
repo_name = args.hub_model_id
repo = Repository(args.output_dir, clone_from=repo_name)
with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
if "step_*" not in gitignore:
gitignore.write("step_*\n")
if "epoch_*" not in gitignore:
gitignore.write("epoch_*\n")
elif args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
# Load models and create wrapper for stable diffusion
tokenizer = CLIPTokenizer.from_pretrained(args.pretrained_model_name_or_path, subfolder="tokenizer")
text_encoder = CLIPTextModel.from_pretrained(args.pretrained_model_name_or_path, subfolder="text_encoder")
vae = AutoencoderKL.from_pretrained(args.pretrained_model_name_or_path, subfolder="vae")
unet = UNet2DConditionModel.from_pretrained(args.pretrained_model_name_or_path, subfolder="unet")
# Freeze vae and text_encoder
vae.requires_grad_(False)
text_encoder.requires_grad_(False)
if args.gradient_checkpointing:
unet.enable_gradient_checkpointing()
if args.scale_lr:
args.learning_rate = (
args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
)
# Initialize the optimizer
if args.use_8bit_adam:
try:
import bitsandbytes as bnb
except ImportError:
raise ImportError(
"Please install bitsandbytes to use 8-bit Adam. You can do so by running `pip install bitsandbytes`"
)
optimizer_cls = bnb.optim.AdamW8bit
else:
optimizer_cls = torch.optim.AdamW
optimizer = optimizer_cls(
unet.parameters(),
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
# TODO (patil-suraj): load scheduler using args
noise_scheduler = DDPMScheduler(
beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000, tensor_format="pt"
)
# Get the datasets: you can either provide your own training and evaluation files (see below)
# or specify a Dataset from the hub (the dataset will be downloaded automatically from the datasets Hub).
# In distributed training, the load_dataset function guarantees that only one local process can concurrently
# download the dataset.
if args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
dataset = load_dataset(
args.dataset_name,
args.dataset_config_name,
cache_dir=args.cache_dir,
)
else:
data_files = {}
if args.train_data_dir is not None:
data_files["train"] = os.path.join(args.train_data_dir, "**")
dataset = load_dataset(
"imagefolder",
data_files=data_files,
cache_dir=args.cache_dir,
)
# See more about loading custom images at
# https://huggingface.co/docs/datasets/v2.4.0/en/image_load#imagefolder
# Preprocessing the datasets.
# We need to tokenize inputs and targets.
column_names = dataset["train"].column_names
# 6. Get the column names for input/target.
dataset_columns = dataset_name_mapping.get(args.dataset_name, None)
if args.image_column is None:
image_column = dataset_columns[0] if dataset_columns is not None else column_names[0]
else:
image_column = args.image_column
if image_column not in column_names:
raise ValueError(
f"--image_column' value '{args.image_column}' needs to be one of: {', '.join(column_names)}"
)
if args.caption_column is None:
caption_column = dataset_columns[1] if dataset_columns is not None else column_names[1]
else:
caption_column = args.caption_column
if caption_column not in column_names:
raise ValueError(
f"--caption_column' value '{args.caption_column}' needs to be one of: {', '.join(column_names)}"
)
# Preprocessing the datasets.
# We need to tokenize input captions and transform the images.
def tokenize_captions(examples, is_train=True):
captions = []
for caption in examples[caption_column]:
if isinstance(caption, str):
captions.append(caption)
elif isinstance(caption, (list, np.ndarray)):
# take a random caption if there are multiple
captions.append(random.choice(caption) if is_train else caption[0])
else:
raise ValueError(
f"Caption column `{caption_column}` should contain either strings or lists of strings."
)
inputs = tokenizer(captions, max_length=tokenizer.model_max_length, padding="do_not_pad", truncation=True)
input_ids = inputs.input_ids
return input_ids
train_transforms = transforms.Compose(
[
transforms.Resize((args.resolution, args.resolution), interpolation=transforms.InterpolationMode.BILINEAR),
transforms.CenterCrop(args.resolution) if args.center_crop else transforms.RandomCrop(args.resolution),
transforms.RandomHorizontalFlip() if args.random_flip else transforms.Lambda(lambda x: x),
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]),
]
)
def preprocess_train(examples):
images = [image.convert("RGB") for image in examples[image_column]]
examples["pixel_values"] = [train_transforms(image) for image in images]
examples["input_ids"] = tokenize_captions(examples)
return examples
with accelerator.main_process_first():
if args.max_train_samples is not None:
dataset["train"] = dataset["train"].shuffle(seed=args.seed).select(range(args.max_train_samples))
# Set the training transforms
train_dataset = dataset["train"].with_transform(preprocess_train)
def collate_fn(examples):
pixel_values = torch.stack([example["pixel_values"] for example in examples])
pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()
input_ids = [example["input_ids"] for example in examples]
padded_tokens = tokenizer.pad({"input_ids": input_ids}, padding=True, return_tensors="pt")
return {
"pixel_values": pixel_values,
"input_ids": padded_tokens.input_ids,
"attention_mask": padded_tokens.attention_mask,
}
train_dataloader = torch.utils.data.DataLoader(
train_dataset, shuffle=True, collate_fn=collate_fn, batch_size=args.train_batch_size
)
# Scheduler and math around the number of training steps.
overrode_max_train_steps = False
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
overrode_max_train_steps = True
lr_scheduler = get_scheduler(
args.lr_scheduler,
optimizer=optimizer,
num_warmup_steps=args.lr_warmup_steps * args.gradient_accumulation_steps,
num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
)
unet, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
unet, optimizer, train_dataloader, lr_scheduler
)
weight_dtype = torch.float32
if args.mixed_precision == "fp16":
weight_dtype = torch.float16
elif args.mixed_precision == "bf16":
weight_dtype = torch.bfloat16
# Move text_encode and vae to gpu.
# For mixed precision training we cast the text_encoder and vae weights to half-precision
# as these models are only used for inference, keeping weights in full precision is not required.
text_encoder.to(accelerator.device, dtype=weight_dtype)
vae.to(accelerator.device, dtype=weight_dtype)
# Create EMA for the unet.
if args.use_ema:
ema_unet = EMAModel(unet.parameters())
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if overrode_max_train_steps:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
# We need to initialize the trackers we use, and also store our configuration.
# The trackers initializes automatically on the main process.
if accelerator.is_main_process:
accelerator.init_trackers("text2image-fine-tune", config=vars(args))
# Train!
total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(train_dataset)}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
# Only show the progress bar once on each machine.
progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
progress_bar.set_description("Steps")
global_step = 0
for epoch in range(args.num_train_epochs):
unet.train()
train_loss = 0.0
for step, batch in enumerate(train_dataloader):
with accelerator.accumulate(unet):
# Convert images to latent space
latents = vae.encode(batch["pixel_values"].to(weight_dtype)).latent_dist.sample()
latents = latents * 0.18215
# Sample noise that we'll add to the latents
noise = torch.randn_like(latents)
bsz = latents.shape[0]
# Sample a random timestep for each image
timesteps = torch.randint(0, noise_scheduler.num_train_timesteps, (bsz,), device=latents.device)
timesteps = timesteps.long()
# Add noise to the latents according to the noise magnitude at each timestep
# (this is the forward diffusion process)
noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
# Get the text embedding for conditioning
encoder_hidden_states = text_encoder(batch["input_ids"])[0]
# Predict the noise residual and compute loss
noise_pred = unet(noisy_latents, timesteps, encoder_hidden_states).sample
loss = F.mse_loss(noise_pred.float(), noise.float(), reduction="mean")
# Gather the losses across all processes for logging (if we use distributed training).
avg_loss = accelerator.gather(loss.repeat(args.train_batch_size)).mean()
train_loss += avg_loss.item() / args.gradient_accumulation_steps
# Backpropagate
accelerator.backward(loss)
if accelerator.sync_gradients:
accelerator.clip_grad_norm_(unet.parameters(), args.max_grad_norm)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
# Checks if the accelerator has performed an optimization step behind the scenes
if accelerator.sync_gradients:
if args.use_ema:
ema_unet.step(unet.parameters())
progress_bar.update(1)
global_step += 1
accelerator.log({"train_loss": train_loss}, step=global_step)
train_loss = 0.0
logs = {"step_loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
progress_bar.set_postfix(**logs)
if global_step >= args.max_train_steps:
break
# Create the pipeline using the trained modules and save it.
accelerator.wait_for_everyone()
if accelerator.is_main_process:
unet = accelerator.unwrap_model(unet)
if args.use_ema:
ema_unet.copy_to(unet.parameters())
pipeline = StableDiffusionPipeline(
text_encoder=text_encoder,
vae=vae,
unet=unet,
tokenizer=tokenizer,
scheduler=PNDMScheduler(
beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", skip_prk_steps=True
),
safety_checker=StableDiffusionSafetyChecker.from_pretrained("CompVis/stable-diffusion-safety-checker"),
feature_extractor=CLIPFeatureExtractor.from_pretrained("openai/clip-vit-base-patch32"),
)
pipeline.save_pretrained(args.output_dir)
if args.push_to_hub:
repo.push_to_hub(commit_message="End of training", blocking=False, auto_lfs_prune=True)
accelerator.end_training()
学習が終わったら下記のコードで画像を生成します。
import torch
from diffusers import StableDiffusionPipeline
from torch import autocast
DEVICE = "cuda"
pipe = StableDiffusionPipeline.from_pretrained("./sd-model-gundam-captioned")
pipe.to(DEVICE)
prompt = "A robot, humanoid, red and gray"
with autocast(DEVICE):
image = pipe(prompt, guidance_scale=7.5)["sample"][0]
image.save("test.png")
image
Discussion