はじめに
弊社では商品情報の検索の用途としてオンプレ環境ElasticSearchを利用していました。
今回、ElasticSearchからAWS OpenSearchに移行して本番運用していく上で監視すべきポイントや知っておいた方が良い点などを書ければと思います。
この記事の背景
はじめてOpenSearchを運用するにあたって色々な不安要素があると思います。
例えばストレージ容量、インスタンスタイプ、ノード数、負荷状況などが予想していた見積もり通りなのか、サービスが成長していく中でどういったタイミングでスケールさせればいいか、負荷が高い状態ではどういった振る舞いをするのかなど理解深耕を進めていく。
OpenSearchの何を監視していくか
上記のAWSドキュメントを参考にいくつか監視していく項目を洗い出します。
どれも重要そうですね、重要になってくるのは以下の項目でしょうか、運用していく上で監視する項目や監視内容を調整していくのが良いかと思います。
| 監視項目 | 監視内容例 |
|---|---|
| ClusterStatus.red | 少なくとも1つのプライマリシャードとそのレプリカがノードに割り当てられていない状態 |
| ClusterStatus.yellow | 少なくとも1つのレプリカシャードがノードに割り当てられていない状態 |
| Nodes | クラスタのノード数 |
| FreeStorageSpace | クラスターのノードの空きストレージ容量が20GiB以下になっているか |
| AutomatedSnapshotFailure | 自動スナップショットが失敗 |
| MasterCPUUtilization, CPUUtilization | CPU使用率が最大80%以上続く状態が15分間で3回以上発生 |
| MasterJVMMemoryPressure, JVMMemoryPressure | JVM負荷が最大95%以上続く状態が1分間で3回以上発生 |
| ThreadpoolWriteQueue | インデックス作成の同時実行数が高い状態、Queue数が平均で100以上続く状態が1分間で1回以上発生 |
| ThreadpoolSearchQueue | 検索の同時実行性が高い状態、Queueが最大で5000以上の状態がが1分間で1回以上発生 |
| OpenSearchRequests | OpenSearchクラスターに対するリクエストの10%以上で5xx系が発生していないか |
| MasterReachableFromNode | マスターノードが停止しているか、連絡不能な状態 |
| ThreadpoolSearchRejected | 検索が拒否されたか |
| ThreadpoolWriteRejected | 書き込みが拒否されたか |
弊社ではNewRelicを用いて上記項目をダッシュボード上でモニタリングしOpenSearchの稼働状況を確認できるようにしています。またNewRelicアラート設定で閾値の違反が検知された場合はslack、メールにて通知するようにしています。
JVMMemoryPressureの値が大きいとどういったことが起きるのか?
まず、Javaガーベージコレクションの動きについて「JavaオブジェクトがHeapメモリに割り当てられオブジェクトの破棄・生成を繰り返し、Heapメモリ領域が断片化されたままになり新しいオブジェクトを割り当てることが困難になってきます。そこでJVMのGarbageCollectorが定期的にHeapメモリ領域を調べ未使用のオブジェクトのメモリを再利用、必要に応じてHeapを圧縮して、より連続した空き領域を確保します。」
JVMMemoryPressureはクラスタ内のすべてのデータノードで使用されるHeapメモリの割合を表します。
(MasterJVMMemoryPressureは専用マスタノードで使用されるHeapメモリの割合)
そして、 によると
- OpenSearchでは、JVMPressureが75%に達するとGarbageCollectorが起動、CPUに大きな負荷がかかり、メモリ使用量が増加し続ける可能性があります。これにより、パフォーマンスが低下したり、ClusterBlockExceptionやJVMOutOfMemoryErrorが発生する可能性がある
- JVMPressureが30分で92%を超えると、OpenSearchSearviceはすべての書き込みを操作をブロック
- JVMPressureが100%に達すると、OpenSearchService JVMは終了し、最終的にはOutOfMemoryError(OOM)によって再起動されることがある
ThreadpoolWriteQueue/ThreadpoolSearchQueueについて
OpenSearchへ書き込み(検索)操作に関連するタスクを処理するためのスレッドプール
OpenSearchへのリクエストがQueueに格納され、スレッドプール内のスレッドに対してQueueを割り当てて処理をします。
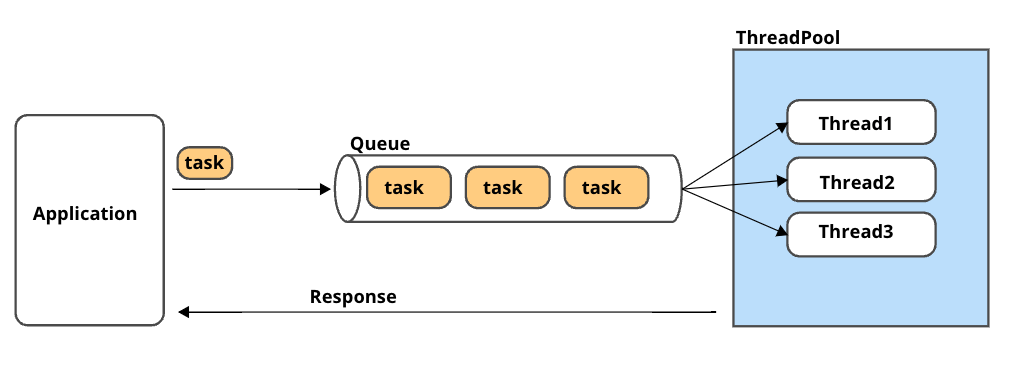
・書き込み、読み込みスレッド数は以下の計算式によって決定します。
CPUコア数 x 書き込み専用ノード数 = 書き込みスレッド数
((CPUコア数 x 3) / 2 + 1) x 読み込み専用ノード数 = 読み込みスレッド数
例としてR5.2xlargeを選択した場合は
8vCPU x ノード数3 = 書き込みスレッド数24
(8vCPU x 3) / 2 + 1) x ノード数3 = 読み込みスレッド数39
となります。
・検索キューのサイズは1000、書き込みキューのサイズは10000となっています。
GET _cluster/settings?include_defaults
"search" : {
"max_queue_size" : "1000",
"queue_size" : "1000",
"size" : "4",
"auto_queue_frame_size" : "2000",
"target_response_time" : "1s",
"min_queue_size" : "1000"
},
...
"write" : {
"queue_size" : "10000",
"size" : "2"
},
※ OpenSearch2.x系にて確認
ThreadpoolWriteRejected/ThreadpoolSearchRejectedについて
スレッドプールで書き込み/検索が拒否(Error 429 Too Many Requests)されたタスクの数を表しています。それぞれの書き込み・読み込みキューの上限を超えるとスレッドプールで拒否されます。
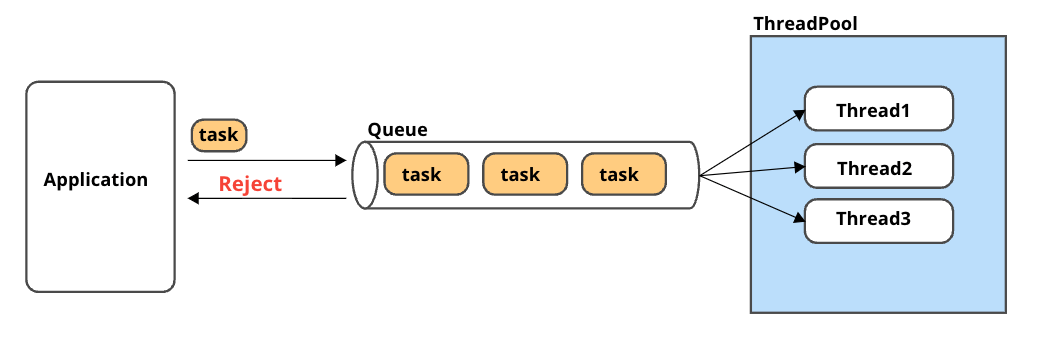
それ以外にもOpenSearchのアドミッションコントロール(過負荷になるのを防ぐ)という仕組みによって、JVMMemoryPressure利用率の高い場合リクエストを抑制する動作もあります。ノード上のメモリが解放され、メモリ利用率が下がるまでリクエストが拒否されることがあります。
リクエストペイロードサイズによってもリクエストの拒否が発生。
-
ThreadpoolWriteRejectedが発生する場合、OpenSearchへの書き込みリクエスト数を調整、インスタンスサイズをあげてCPUコア数を増やすなどの対応が必要
もしくは下記ドキュメントのrefresh_intervalの設定も有効になりそうです。
https://repost.aws/ja/knowledge-center/opensearch-indexing-performance -
ThreadpoolSearchRejectedが発生する場合は、データノード数を増やすなどのスケールアウト、もしくはスレッド数(CPUコア)を増やすためにスケールアップが必要
ClusterStatus.red
- 少なくとも1つのプライマリシャードとそのレプリカがノードに割り当てられていない
それによりスナップショットが失敗する。
問題のあるインデックスを削除する、インスタンスサイズを上げるなどの対応
原因がデータノードの処理の継続的な高負荷による可能性もあるため、JVMMemoryPressure、CPUUtilization、ノード数、ストレージ容量の状態を見て判断
最後に
定期的に負荷状況の統計を確認し、インスタンスサイズやノード数などの調整を検討して最適な状態を維持、またサービスページの表示速度が遅い、表示自体がされない状況に陥った時などの障害から迅速に復旧対応するために、AWSドキュメンテーションの確認、監視、OpenSearchの仕組み理解していこうと思います。そして困ったときはAWSサポートに頼る。備えあれば憂いなしですの。
最後までお付き合いいただき、ありがとうございます。
来年も何卒よろしくお願いいたします。🙏🌟
参考資料

Discussion