本記事はアイスタイル Advent Calendar 2023 25日目の記事です。
去年はアドカレを書く余裕もあまりなかったので、2年ぶり4回目の投稿になるsugatoです。
アイスタイルではデータエンジニアをさせてもらっています。
はじめに
現在、Modern Data Stackな新しいデータ基盤の構築を進めていますが、その中で導入することにしたGreat Expectationsの紹介をしたいと思います。
Great Expectaitonsを導入することは決めたものの、まだまだ日本語の記事が少ないなと思いますので、実際にデータ基盤に導入するか悩んでいる方に少しでも参考になる情報があれば幸いです。
コミュニティ内ではGXと呼ばれているので、本記事では以下、GXと省略することにします。
想定読者
GXの開発フローより以前の章に関しては、データ品質に関心がある全ての方向けの内容になります。
以降は、実際に利用しているコードの紹介も含みますので、エンジニア向けの内容です。
また、現時点で実装中の内容を含むため、変更があれば別の機会に紹介できればと思います。
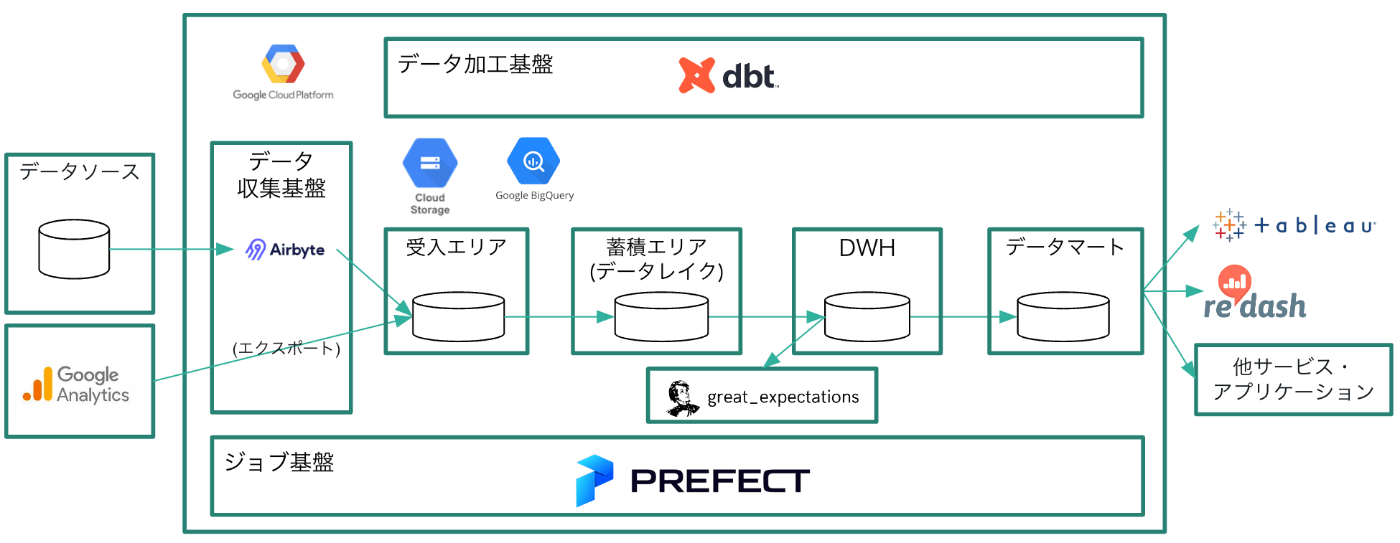
新しいデータ基盤の概要図
現在目指しているデータ基盤の簡易な概要図が以下のものになります。
データのモデリング部分はエリアの中で実際にはさらに細分化されていますが、本記事では割愛します。
Great Expectations(GX)の導入経緯
現在、アイスタイルにおけるデータパイプラインは分散して管理者も複数いるため、生成されるデータの品質にばらつきがある、という課題があります。
また、ソースシステム側とのコミュニケーションが不十分で、データ基盤に入ってくるデータの品質が担保できていない、という課題がありました。(詳細は後述します。)
新しいデータ基盤ではdbtも導入予定のため、品質を担保する仕組みとしてdbt側でのtestを実施することもある程度可能でした。
この中で、GXを導入することにしたのは責任分解点を設けるためです。
まずはデータの加工前に入ってくるデータの品質を担保したい。
そしてそのために、様々なMetricsを見ることができるGXを採用することにしました。
期待している役割・利用方針
他にも記事があるので、GXにおける各ファイルの作成方法は割愛しますが、以下のようなjsonファイルを作成することで、特定テーブルに対するバリデーションの設定が可能です。
metaの設定も可能ですが、省略可能なので割愛しています。
バリデーション定義ファイルのサンプル
{
"data_asset_type": null,
"expectation_suite_name": "raw_orders",
"expectations": [
{
"expectation_type": "expect_table_row_count_to_be_between",
"kwargs": {
"max_value": 99,
"min_value": 99
}
},
{
"expectation_type": "expect_table_columns_to_match_set",
"kwargs": {
"column_set": [
"id",
"order_date",
"user_id",
"status"
],
"exact_match": null
}
}
],
"ge_cloud_id": null
}
データ契約の検知
サンプルのjsonにも記載した通り、expectation_typeに対して、バリデーションを設定したい項目を定義します。
BigQueryに対して設定可能なexpectation_typeの一覧はこちら
現時点では、社内のどのテーブル・カラムがGCP上に連携されているか、ソースシステム側と十分なコミュニケーションができていません。
そのため、カラムが追加・削除されてしまったり、1~5までの値が定義されたカラムに新しい値が入ってくる等を検知できず、レポートに影響を与えてしまったことがありました。
expectationsのファイルを設定するためには、予めソーシスステム側に確認を行い、何を異常として検知するか、というデータ契約を結ぶことが必要になります。
仮に変更内容の連絡が漏れたとしても、GX側で検知することで、基盤側に入ってくるデータの品質を担保することが可能です。
明確なルールを定義できるものだけをGXの責任範囲とする
GXの機能として、以下のような統計的な値の検知をすることも可能です。
- カラムに含まれる値(平均値・中央値も可能)が、設定値の範囲内にあること
- レコード数が、設定値の範囲内であること
ただしこういった値は、時系列的にデータが溜まっていくことで、異常値と判定される条件自体が変わってしまいます。
そのため、GXの責任範囲はいわゆる未知の既知の範囲にとどめ、統計的な値など明確なルールを定義できないものは未知の未知として、Data Observability側の責務としようと考えています。
2023年12月現在、re-dataの導入を検討中です。
この決断に至ったのも、過去参加したData Quality Fundamentalsの輪読会で全てのMetricsを一つのツールに依存して検知しなくても良い、と考えたことも影響しています。
datatech-jpでは、他にも勉強会や情報交換が行われていますので、興味ある方はぜひご参加ください!
GXの開発フロー
新しい基盤の概要図で示した通り、パイプライン自体はPrefectで実行しますが、実行するジョブはドメイン単位で分割します。
(本記事の中ではPrefectに関して詳細は触れませんが、後日また紹介ができれば。)
主なパッケージのバージョン
great-expectations = "==0.15.46"
sqlalchemy = "<2.0"
sqlalchemy-bigquery = "==1.5.0"
python_version = "3.10"
GXの検証中に、sqlalchemyは2.0以下に固定した方が良い、という警告が出たので、バージョンの指定を行っています。
どうやら2.0から大きな変更が予定されているみたいです。
GX側のリポジトリ構成
実行ファイル群は、CLIで作成することも可能ですが、ファイルコピーでも全く問題ありません。
その際、jupyterが起動するのですが、開発フローとして手間な印象があったので割愛しました。
ジョブはドメイン単位で分割するので、同じ粒度でテンプレートのフォルダを用意し、開発時の負担を減らす構成を目指しています。
リポジトリ構成と主要なファイル群
ドメインごとのフォルダ名(domain-template)
├ checkpoints
│ └ checkpoints.yml(バリデーションを実行するための設定ファイル)
├ expectations(バリデーションの設定ファイル群の格納)
│ └ table_name.json
├ great_expectations.yml(データソースの設定ファイル)
│
scripts(GXの処理を実行するためのファイル群)
├ gx_docs.py(ログファイル出力用)
├ gx_manager.py
├ gx_validate.py(バリデーション実行用)
│
.env
開発フローの概要
- domain-templateを複製して、フォルダ名を対象ドメインに変更
(新規ドメインの開発時のみ) - expectations配下にバリデーションの定義ファイルを作成
- checkpoints.ymlに対して、2番で定義したファイル名を追加
- バリデーションの実行結果の確認
- 問題なければマージしてデプロイ
というフローを想定しています。
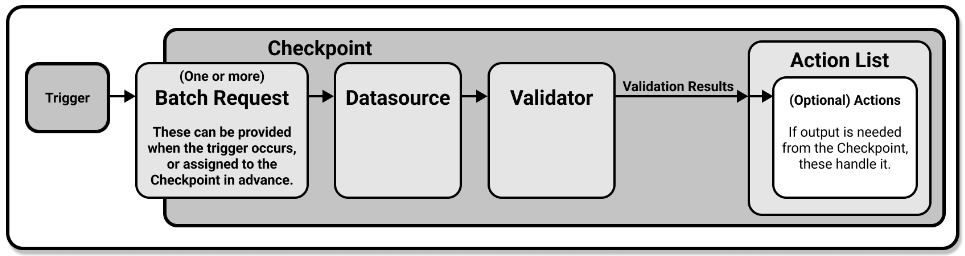
バリデーションが実行される仕組み
用語が少々特殊なものが登場しますが、実行される仕組みとしては以下の図の流れになります。
各ファイルの詳細および開発時の変更箇所
動的に環境を切り替えるため、環境変数を利用しています。
TARGETに個人名を入れていますが、ローカル以外ではこのファイルは利用されません。
環境変数の設定
TARGET=sugato(開発者個人用のデータセット名)
DOMAIN=domain-template(開発対象のドメインの名前)
GCP_PROJECT_ID=dev
datasourcesの設定
datasourcesの部分は動的に切り替えることはせず、1ファイル内に環境ごとの指定を行います。
基盤の概要図では示しませんでしたが、GCPのプロジェクトを環境によって分けているためです。
connection_stringの部分が環境変数によって切り替わるため、開発フローの中でこのファイルへの変更は行いません。
great_expectations.ymlの設定
config_version: 3.0
datasources:
dev:
class_name: Datasource
module_name: great_expectations.datasource
execution_engine:
class_name: SqlAlchemyExecutionEngine
module_name: great_expectations.execution_engine
connection_string: bigquery://${GCP_PROJECT_ID}/${TARGET}
data_connectors:
default_runtime_data_connector_name:
class_name: RuntimeDataConnector
module_name: great_expectations.datasource.data_connector
batch_identifiers:
- default_identifier_name
default_inferred_data_connector_name:
class_name: InferredAssetSqlDataConnector
module_name: great_expectations.datasource.data_connector
include_schema_name: true
introspection_directives:
schema_name: ${TARGET}
default_configured_data_connector_name:
class_name: ConfiguredAssetSqlDataConnector
module_name: great_expectations.datasource.data_connector
stg:
class_name: Datasource
module_name: great_expectations.datasource
execution_engine:
class_name: SqlAlchemyExecutionEngine
module_name: great_expectations.execution_engine
connection_string: bigquery://${GCP_PROJECT_ID}/${TARGET}
data_connectors:
default_runtime_data_connector_name:
class_name: RuntimeDataConnector
module_name: great_expectations.datasource.data_connector
batch_identifiers:
- default_identifier_name
default_inferred_data_connector_name:
class_name: InferredAssetSqlDataConnector
module_name: great_expectations.datasource.data_connector
include_schema_name: true
introspection_directives:
schema_name: ${TARGET}
default_configured_data_connector_name:
class_name: ConfiguredAssetSqlDataConnector
module_name: great_expectations.datasource.data_connector
prd:
class_name: Datasource
module_name: great_expectations.datasource
execution_engine:
class_name: SqlAlchemyExecutionEngine
module_name: great_expectations.execution_engine
connection_string: bigquery://${GCP_PROJECT_ID}/${TARGET}
data_connectors:
default_runtime_data_connector_name:
class_name: RuntimeDataConnector
module_name: great_expectations.datasource.data_connector
batch_identifiers:
- default_identifier_name
default_inferred_data_connector_name:
class_name: InferredAssetSqlDataConnector
module_name: great_expectations.datasource.data_connector
include_schema_name: true
introspection_directives:
schema_name: ${TARGET}
default_configured_data_connector_name:
class_name: ConfiguredAssetSqlDataConnector
module_name: great_expectations.datasource.data_connector
config_variables_file_path: uncommitted/config_variables.yml
stores:
expectations_store:
class_name: ExpectationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: expectations/
validations_store:
class_name: ValidationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: uncommitted/validations/
evaluation_parameter_store:
class_name: EvaluationParameterStore
checkpoint_store:
class_name: CheckpointStore
store_backend:
class_name: TupleFilesystemStoreBackend
suppress_store_backend_id: true
base_directory: checkpoints/
profiler_store:
class_name: ProfilerStore
store_backend:
class_name: TupleFilesystemStoreBackend
suppress_store_backend_id: true
base_directory: profilers/
expectations_store_name: expectations_store
validations_store_name: validations_store
evaluation_parameter_store_name: evaluation_parameter_store
checkpoint_store_name: checkpoint_store
data_docs_sites:
local_site:
class_name: SiteBuilder
show_how_to_buttons: true
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: uncommitted/data_docs/local_site/
site_index_builder:
class_name: DefaultSiteIndexBuilder
anonymous_usage_statistics:
data_context_id: c63250a7-8a7d-4d6c-894b-6cf2562d2d54
enabled: true
notebooks:
include_rendered_content:
globally: false
expectation_suite: false
expectation_validation_result: false
expectations配下にバリデーション定義ファイル作成
サンプルファイルは、期待する役割・利用方針で既に記載しているので、ここでは割愛します。
以下のテンプレファイルを予め作成しておき、こちらを複製して修正します。
checkpointsで呼ばれるバリデーション用のテンプレ.json
{
"data_asset_type": null,
"expectation_suite_name": "テーブル名",
"expectations": [
{
"expectation_type": "実行したいバリデーション項目1つ目",
"kwargs": {
"引数に応じてセットしてください": [
]
}
},
{
"expectation_type": "実行したいバリデーション項目2つ目",
"kwargs": {
"引数に応じてセットしてください": [
]
}
}
],
"ge_cloud_id": null
}
checkpointsの設定
checkpoints.ymlは複数ファイル作成することも可能ですが、1ファイルで管理しています。
このファイルがGXのバリデーション実行時に呼ばれますが、ドメイン単位でジョブを設定し、管理し易くするためです。
開発時はデータ契約に基づいて作成したjsonファイルを、checkpointsで呼び出されるように追記します。
仮に1つのドメインで複数のジョブが発生する場合は、checkpoints.yml自体をジョブ単位で分けていきます。
checkpoints.ymlの設定
name: '${DOMAIN}'
config_version: 1.0
template_name:
module_name: great_expectations.checkpoint
class_name: Checkpoint
run_name_template: '%Y%m%d-%H%M%S-${DOMAIN}'
expectation_suite_name:
batch_request: {}
action_list:
- name: store_validation_result
action:
class_name: StoreValidationResultAction
- name: store_evaluation_params
action:
class_name: StoreEvaluationParametersAction
- name: update_data_docs
action:
class_name: UpdateDataDocsAction
site_names: []
evaluation_parameters: {}
runtime_configuration: {}
validations:
- batch_request:
datasource_name: ${GCP_PROJECT_ID}
data_connector_name: default_inferred_data_connector_name
data_asset_name: ${TARGET}.テーブル名
data_connector_query:
index: -1
expectation_suite_name: テーブル名
# expectations配下のjsonファイルの数だけ、以下にテーブルを追加してください
- batch_request:
datasource_name: ${GCP_PROJECT_ID}
data_connector_name: default_inferred_data_connector_name
data_asset_name: ${TARGET}.テーブル名
data_connector_query:
index: -1
expectation_suite_name: テーブル名
profilers: []
ge_cloud_id:
expectation_suite_ge_cloud_id:
各種pythonファイルの中身
ローカルで動作検証する場合は、gx_validate.pyのみを利用します。
gx_manager.py
import great_expectations as gx
import os
import argparse
from pydantic import BaseModel
class ArgsModel(BaseModel):
domain: str
class GreatExpectations:
def __init__(self, args: ArgsModel):
self.args = args
self.context = gx.get_context(context_root_dir=os.path.abspath(args.domain))
def validation(self):
"""Creates a task that validates a run of a Great Expectations checkpoint"""
results = self.context.run_checkpoint(
checkpoint_name="checkpoints",
run_name=self.args.domain,
)
# バリデーションの結果をチェック
if results.success is True:
print("All validations succeeded!")
else:
print("Some validations failed!")
# 各バリデーション結果を確認し、失敗したもののテーブル名を出力
failed_tables = []
# run_result_keyは後続で呼ばれてないですが、itemsのキーとvalueを返すために設定
for run_result_key, run_result_value in results['run_results'].items():
if 'validation_result' in run_result_value and not run_result_value['validation_result']['success']:
failed_table_name = run_result_value['validation_result']['meta']['expectation_suite_name']
failed_tables.append(failed_table_name)
if failed_tables:
print("Failed tables:", failed_tables)
return results
def build_data_docs(self):
"""Creates a task that builds the Great Expectations data docs"""
result = self.context.build_data_docs()
return result
@classmethod
def initialize(cls):
parser = argparse.ArgumentParser(description="Great Expectations")
parser.add_argument("--domain", help="ドメイン名")
args = parser.parse_args()
model = ArgsModel(domain=args.domain)
return GreatExpectations(model)
gx_docs.py
import sys
from gx_manager import GreatExpectations
if __name__ == "__main__":
gx = GreatExpectations.initialize()
gx.build_data_docs()
gx_validate.py
import sys
from gx_manager import GreatExpectations
if __name__ == "__main__":
gx = GreatExpectations.initialize()
result = gx.validation()
if result.success is False:
sys.exit(1)
ローカルでの動作検証
検証では、checkpoints.ymlに3つのテーブルを指定しています。
そのため、バリデーションを実行すると同時に3つのMetricsが計算されています。
この際2点の理由から、エラー時に出力されるメッセージをあまり作り込んでいません。
- 複数のテーブルを指定する想定なので、ログが大量に吐かれると検索しにくい
- htmlファイルが出力されるので、そちらで詳細確認が可能
バリデーション実行結果
# バリデーションが全て成功した場合、成功したメッセージのみが返って来ます
great_expectations sugato$ python scripts/gx_validate.py --domain domain-template
Calculating Metrics: 100%|███████████████████████████████████████████████████████████████████████| 4/4 [00:01<00:00, 2.41it/s]
Calculating Metrics: 100%|███████████████████████████████████████████████████████████████████████| 4/4 [00:01<00:00, 2.82it/s]
Calculating Metrics: 100%|███████████████████████████████████████████████████████████████████████| 4/4 [00:01<00:00, 3.25it/s]
All validations succeeded!
great_expectations sugato$
# バリデーションが失敗する場合、どのテーブルに対するバリデーションが失敗したのか、というものだけ出力します
great_expectations sugato$ python scripts/gx_validate.py --domain domain-template
Calculating Metrics: 100%|████████████████████████████████████████████████████████████████████████████| 4/4 [00:01<00:00, 2.64it/s]
Calculating Metrics: 100%|████████████████████████████████████████████████████████████████████████████| 4/4 [00:01<00:00, 3.36it/s]
Calculating Metrics: 100%|████████████████████████████████████████████████████████████████████████████| 4/4 [00:01<00:00, 3.60it/s]
Some validations failed!
Failed tables: ['wisdom_answer', 'raw_customers']
htmlファイルでの実行結果確認
バリデーションを実行すると、uncommitted配下にindex.htmlというファイルが出力されます。
データ基盤上で実行する場合、これらのログファイルをGCSに吐き出して、履歴として保持します。
.gitignoreの対象にしているフォルダのみを以下で明示
ドメインごとのフォルダ名(domain-template)
├ profilers
├ uncommitted
│ ├ data_docs/local_site
│ │ ├ expectations
│ │ ├ static
│ │ ├ validations
│ │ └ index.html(重要なのはこのファイルのみ!)
│ └ validations
このファイルパスをコピーして、Chrome等で開くと、以下の画面が表示されます。
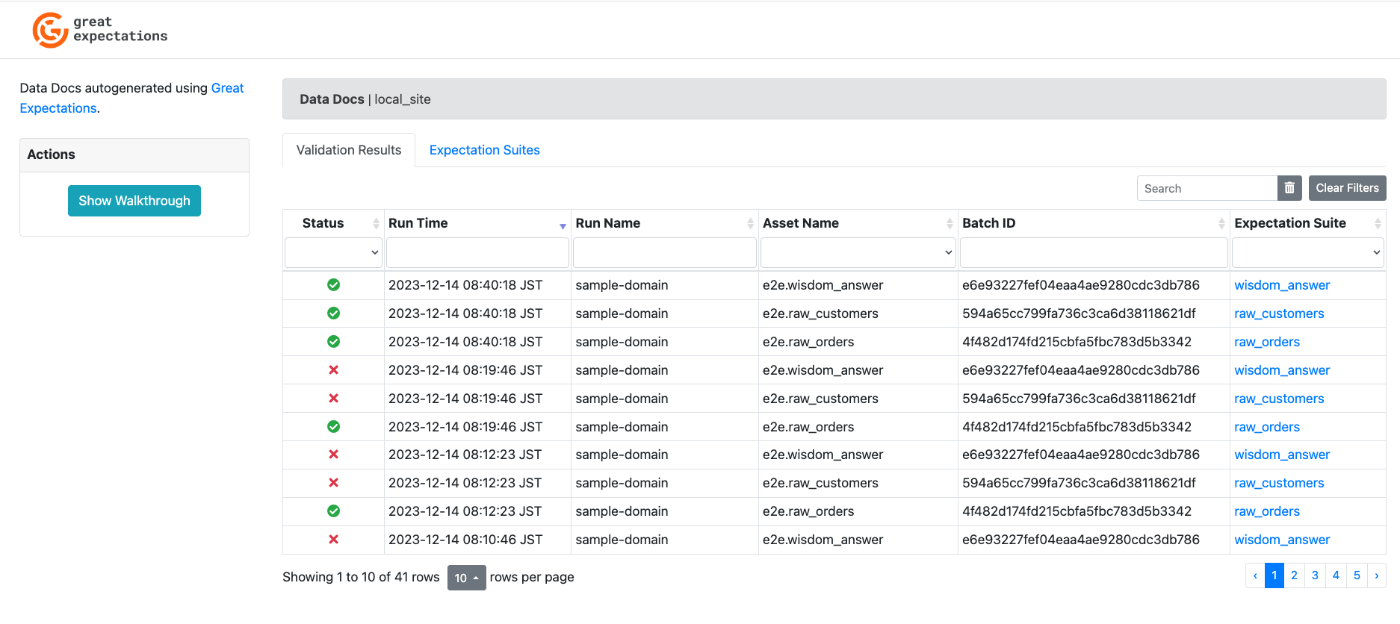
status等をクリックすると、上記画面からバリデーションの実行結果に飛ぶことが可能です。
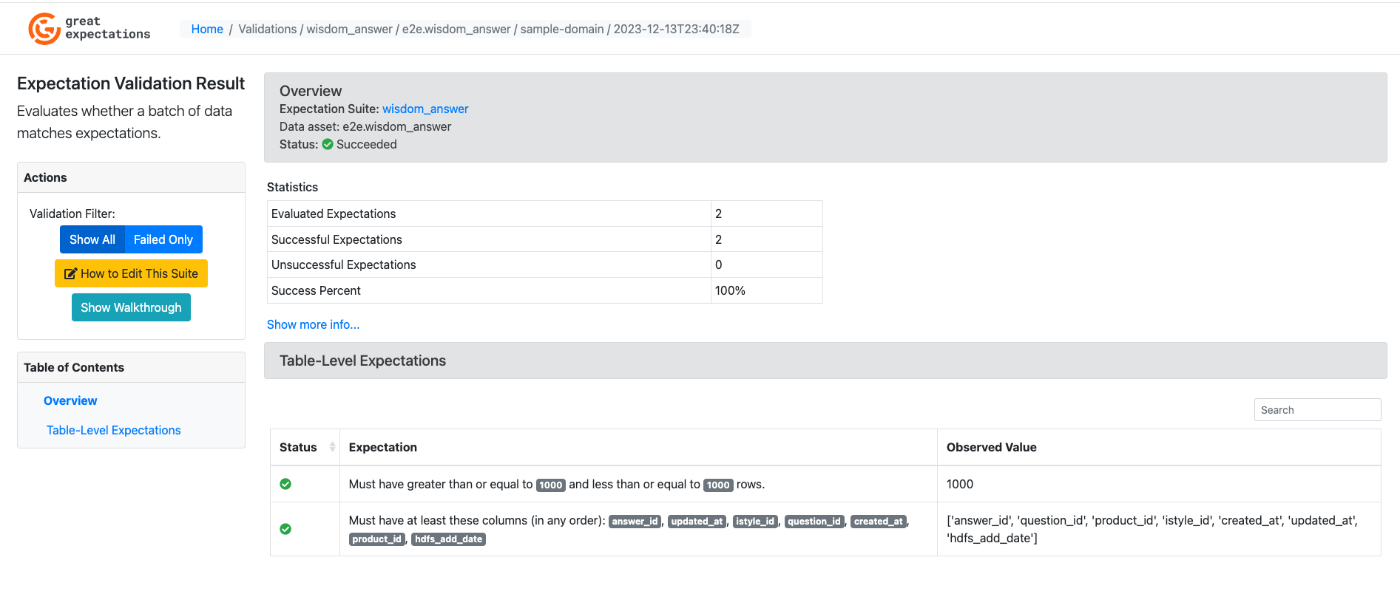
バリデーションの成功画面
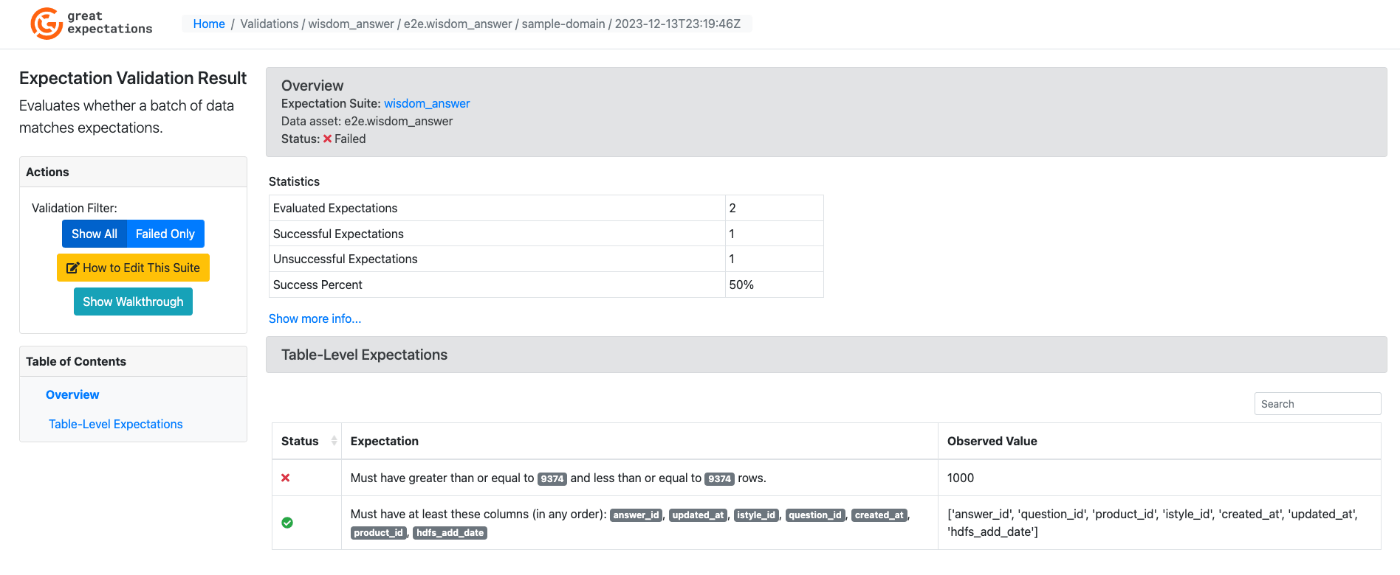
バリデーションの失敗画面
Expectation Suite列のテーブル名をクリックすると、jsonでの設定内容も確認可能です。
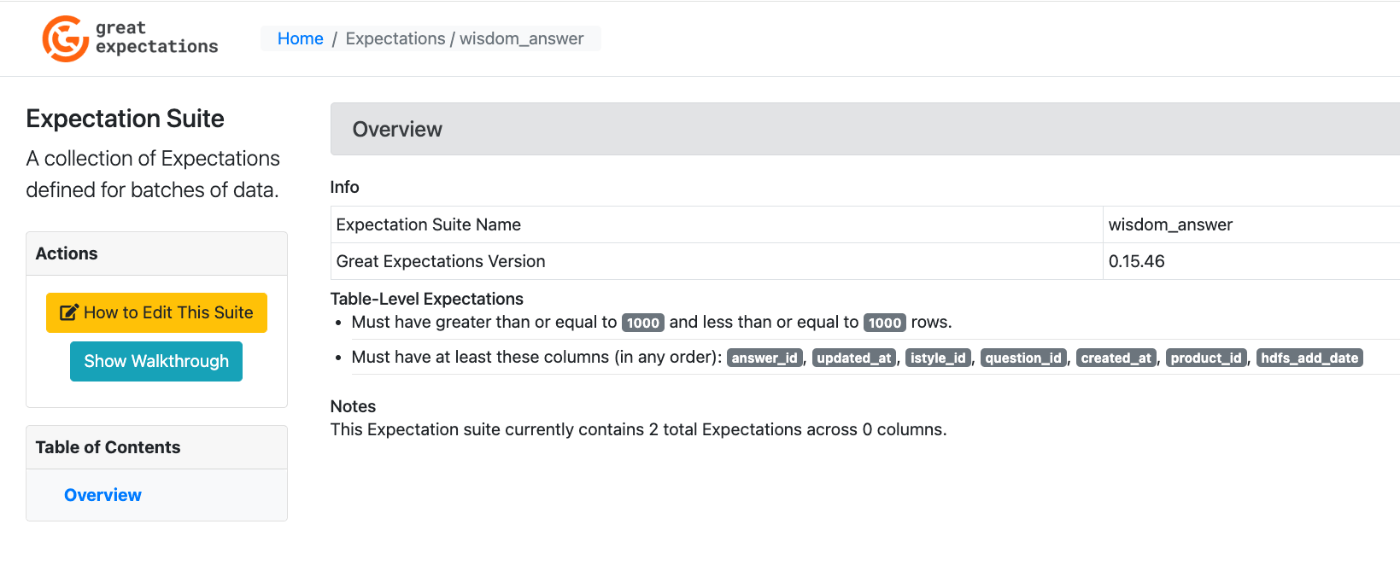
jsonでのバリデーション設定内容
おわりに
少々長くなりましたが、データの品質を担保するためにGreat Expectaitonsはかなり有用だと思います。
導入に迷っている方の参考になれば一人のエンジニアとして非常に嬉しいですし、既に導入されている会社があれば、こんな使い方をしている等、情報交換もぜひできればと思っています。
アイスタイルでは化粧品に関するプラットフォームを形成しているため、多種多様なデータを扱うことが可能です。
Modern Data Stackな基盤の構築に向けて動いておりますので、もし関心があればお気軽にご連絡ください!

Discussion