【初心者向け】Simple Storage Service(S3) 入門!完全ガイド
Amazon Simple Storage Service(S3)

☘️ はじめに
本ページは、AWS に関する個人の勉強および勉強会で使用することを目的に、AWS ドキュメントなどを参照し作成しておりますが、記載の誤り等が含まれる場合がございます。
最新の情報については、AWS 公式ドキュメントをご参照ください。
👀 Contents
- Amazon S3 とは
- Amazon S3 の基本
- バケットポリシー
- アクセスコントロールリスト(ACL)
- ライフサイクル
- ストレージタイプ
- バージョニング
- 暗号化
- 静的ウェブサイトのホスティング
- S3 Transfer Acceleration
- アクセスログ
- S3 Select
- Storage Lens
- リクエスタ支払いバケット
- アクセスポイント
- パフォーマンスの最適化
- 📖 他のサービスとの連携
Amazon S3 とは
スケーラビリティ、データ可用性、セキュリティ、およびパフォーマンスを提供するオブジェクトストレージサービスです。
データ耐久性はイレブンナイン(99.999999999 %)です。可用性はストレージクラスによって異なります。
【AWS Black Belt Online Seminar】Amazon S3/Glacier(YouTube)(1:00:33)

【AWS Black Belt Online Seminar】Amazon S3 ユースケースおよびサービスアップデート(YouTube)(56:21)

Amazon S3 の基本
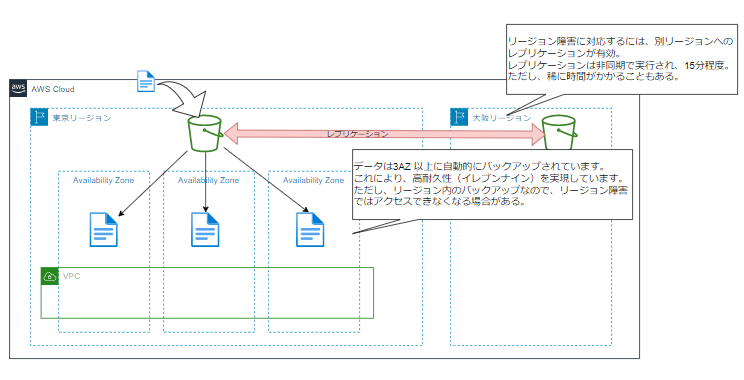
S3 のデータ耐久性はイレブンナイン(99.999999999 %)で、可用性は 99.99 %です(ストレージタイプによって異なります)。
耐久性とは、データが失われないことに対する指標で、可用性は稼働し続けることの指標です。
このイレブンナインという耐久性は、S3 にオブジェクトをアップロードすると、自動的に 3AZ 以上にバックアップが行われることで実現しています。バックアップされるのはリージョン内の AZ なので、リージョン障害時にはアクセスできなくなります。
S3 のオブジェクトキー名には、BucketName/Project/Word123.txt のように指定することが多いです。
Project/WordFiles がプレフィックス、123.txt がオブジェクト名という定義です。
マネジメントコンソールでは、フォルダのような階層で表示されますが、実際は階層というのは存在せず、/ 区切りのプレフィックスをグループ化して表示しており、フォルダという概念をサポートしているだけです。
S3 はリージョンのサービスなので、VPC 内からアクセスするにはいくつかのパターンがあります。
1.EC2(パブリックサブネット)> Internet Gateway

シンプルに、Internet Gateway を通してアクセスします。
2.EC2(プライベートサブネット)> NAT Gateway
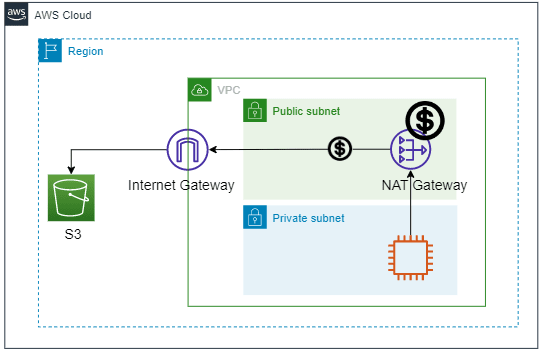
NAT Gateway を利用することでアクセスできます。ただし、NAT Gateway はコストが高めです。
3.EC2(プライベートサブネット)> VPC Endpoint(Gateway タイプ)

S3 や DynamoDB を利用する場合は、コストがかからないのでこちらを使います。
VPC Endpoint(Interface タイプ)と違い、アクセスはグローバル IP です。(通信経路は、AWS 内でのプライベートです)
4.EC2(プライベートサブネット)> VPC Endpoint(Interface タイプ)

プライベート IP でのアクセスが可能です。ただし、VPC Endpoint を起動している時間でコストが発生します。他のサービスでも VPC エンドポイントを使用していると最もコストが高くなるパターンです。
コスト比較
月に 100 GB ほどデータ転送が発生した場合の比較です。
VPC エンドポイントは 24 時間 ×1 か月(30.5 日)使用しているものとします。
| アクセスパターン | コスト | 備考 |
|---|---|---|
| ①EC2(パブリックサブネット)⇒ Internet Gateway | $0.00 | |
| ②EC2(プライベートサブネット) ⇒ NAT Gateway | $51.60 | NAT Gateway*1 台 |
| ③EC2(プライベートサブネット) ⇒ VPC Endpoint(Gateway タイプ) | $0.00 | |
| ④EC2(プライベートサブネット) ⇒ VPC Endpoint(Interface タイプ) | $10.60 |
バケットポリシー
AWS ドキュメント> バケットポリシーの使用
バケットとその中のオブジェクトへのアクセス許可を付与できるリソースベースのポリシーで、JSON で定義します。
同一アカウント内でのアクセスに対する許可設定は、基本的に IAM ポリシーによって制御します。(併用してもよいが設定が煩雑になります)
IAMポリシーとバケットポリシーの両方を使用した場合、どちらかで拒否されていた場合は拒否されます。
{
"Version": "2012-10-17",
"Id": "S3PolicyId1",
"Statement": [
{
"Sid": "IPAllow",
"Effect": "Deny",
"Principal": "*",
"Action": "s3:*",
"Resource": [
"arn:aws:s3:::DOC-EXAMPLE-BUCKET",
"arn:aws:s3:::DOC-EXAMPLE-BUCKET/*"
],
"Condition": {
"NotIpAddress": {
"aws:SourceIp": "192.0.2.0/24"
}
}
}
]
}
AWS ドキュメント> バケット所有者がユーザーにバケットのアクセス許可を付与する
別アカウントからのアクセスを許可する場合は、バケットポリシー(アクセスされる側の S3 に設定)と IAM ポリシー(アクセスする別アカウント側で設定)の両方で許可する必要があります。
AWS ドキュメント> バケット所有者がクロスアカウントのバケットのアクセス許可を付与する
バケットポリシーのサイズには制限があり、20 KB となっています。

アクセスコントロールリスト(ACL)
AWS ドキュメント> ACL によるアクセス管理
「バケット・オブジェクト」への「アクセス」を許可するもので、基本的な読み取り/書き込み許可を他の AWS アカウントに付与するために使用します。
ACL は S3 のサービスが開始された当初からあったアクセス制御の手段ですが、その後 IAM が提供されたため、アクセス制御の手段が複数になりました。
現在では、バケットポリシーや IAM ポリシーのほうが柔軟な制御が可能です。
AWS ドキュメント> ACL ベースのアクセスポリシー (バケットおよびオブジェクト ACL) の使用が適する場合
AWS ドキュメント> バケット所有者が自分の所有していないオブジェクトに対するアクセス許可を付与する
AWS ドキュメント> バケット所有者が所有権のないオブジェクトへのクロスアカウントアクセス許可を付与する
ライフサイクル
AWS ドキュメント > ストレージのライフサイクルの管理
指定した期間が経過したファイルを、別のストレージタイプに移動してコスト削減したり、削除したりできる機能です。
ライフサイクルのルールは、最大 1,000個です。この制限は引き上げができません。
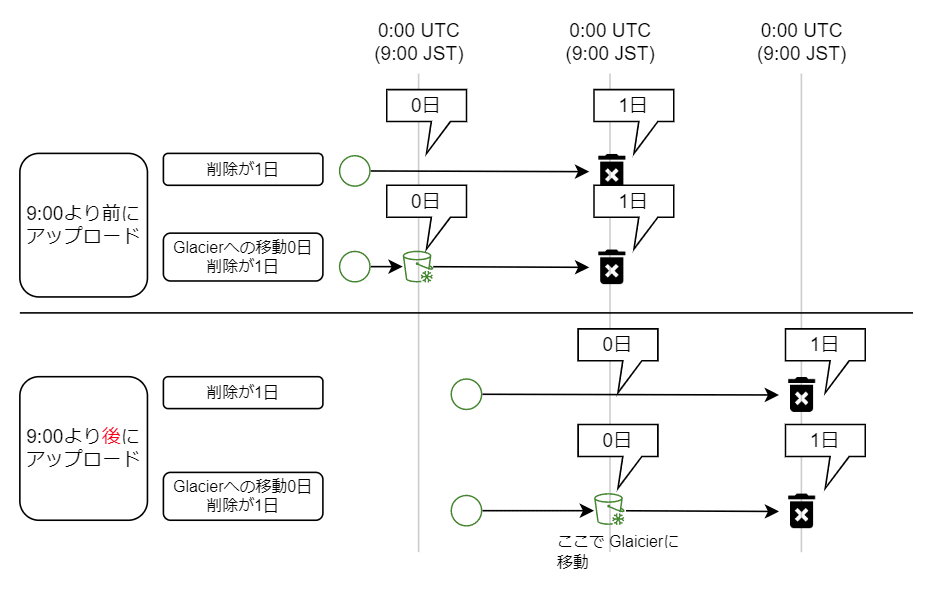
このライフサイクルでオブジェクトが移動されるのは、0:00(UTC)です。日本時間では、午前 9 時となります。
削除日数が 1 日の場合、午前 9 時より前に作成されたものは翌日 9 時、午前 9 時より後に作成されたものは、翌々日の 9 時以降に削除されることになります。
ストレージタイプ
AWS ドキュメント > Amazon S3 ストレージクラスを使用する
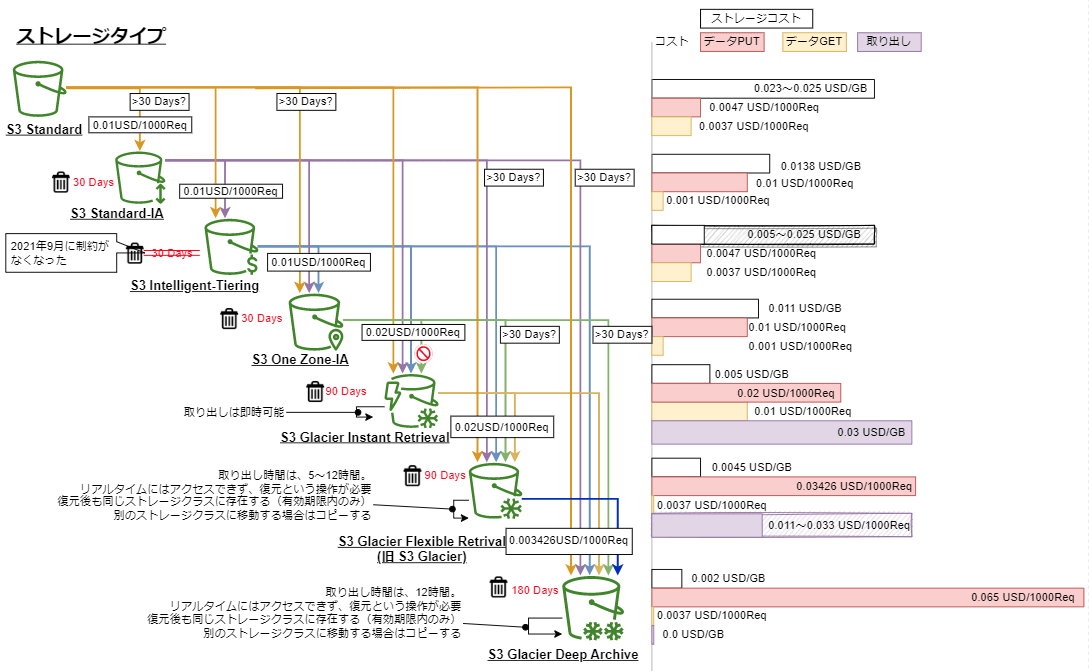
上記画像は、AWS ドキュメントにあるストレージクラス間の移行のためのウォーターフォールモデルに情報を追加したものです。
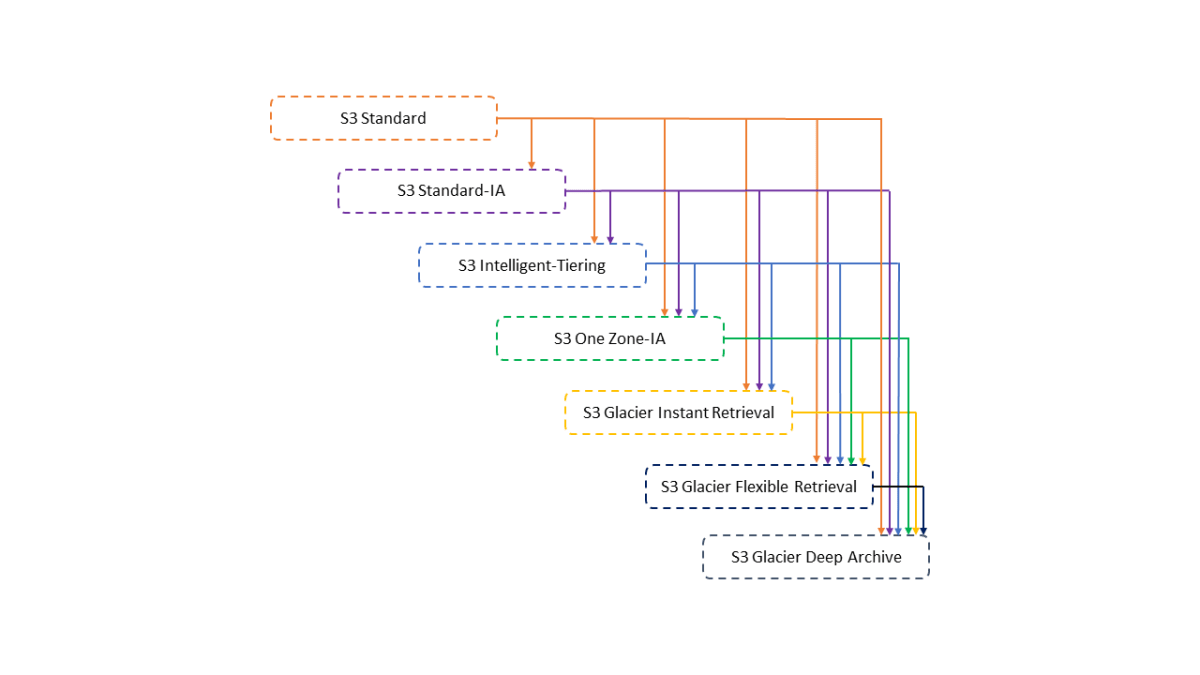
アクセス頻度や削除頻度が不明な場合は、
最低保存期間の制約がない「S3 Intelligent-Tiering」に移動するようにライフサイクルを定義しておけばコスト削減ができます。
- S3 標準(Standard)
- アクセス頻度の高いデータ向けに高い耐久性、可用性、パフォーマンスのオブジェクトストレージです。
- 可用性は 99.99 %
- このストレージクラスから、ライフサイクルによって他のストレージクラスへ移動することが可能です。
- S3 標準 - 低頻度アクセス(Infrequent Access)(Standard-IA)
- アクセス頻度は低いが、必要に応じてすぐに取り出すことが必要なデータに適しています。
- 可用性は 99.9 %
- このストレージクラスから、ライフサイクルによって他のストレージクラスへ移動することが可能です。
- このストレージクラスに格納してから 30 日以内に削除された場合、30 日分の課金が発生します。
- S3 Intelligent-Tiering
- アクセスパターンが不明または変化するデータに対して自動的にコストを削減する
- 30 日間連続してアクセスされなかったオブジェクトを低頻度アクセス階層に移動
- 90 日間アクセスがなければ、アーカイブインスタントアクセス階層に移動
- 可用性は 99.9 %
- 128 KB より小さなオブジェクトは、常に高頻度アクセス階層料金で課金されます。
- S3 1 ゾーン - 低頻度アクセス(S3 One Zone-IA)
- アクセス頻度は低いが、必要に応じてすぐに取り出すことが必要なデータに適しています。
- 他のクラスと違い、一つの AZ のみに保存されているので、Standard-IA より 20% コストを削減できます。
- 可用性は 99.5 %
- このストレージクラスから、ライフサイクルによって他のストレージクラスへ移動することが可能です。
- このストレージクラスに格納してから 30 日以内に削除された場合、30 日に満たなかった分も日割での課金が発生します。
- S3 Glacier Instant Retrieval
- アクセスはほとんどないが、即時取り出しを必要とするアーカイブデータ向け
- S3 Standard と同じミリ秒単位でのデータの取り出し
- 可用性は 99.9 %
- 四半期に一度データにアクセスする場合、S3 Standard-IA に比べて最大で 68%のコスト削減
- このストレージクラスに格納してから 90 日以内に削除された場合、90 日に満たなかった分も日割での課金が発生します。
- S3 Glacier Flexible Retrieval(旧 S3 Glacier)
- 即時アクセスを必要としないアクセス頻度の低い長期データ用
- 可用性は 99.99 %
- 取り出し時間は 数分から数時間
- このストレージクラスに格納してから 90 日以内に削除された場合、90 日に満たなかった分も日割での課金が発生します。
- S3 Glacier Deep Archive
- クラウド上の最も低コストなストレージで数時間で取り出し可能な長期アーカイブやデジタル保存用
- 取り出し時間は 12 時間以内
- 7 ~ 10 年という長期間保存用に設計されており、磁気テープライブラリの理想的な代替策となる。
- このストレージクラスに格納してから 180 日以内に削除された場合、180 日に満たなかった分も日割での課金が発生します。
バージョニング
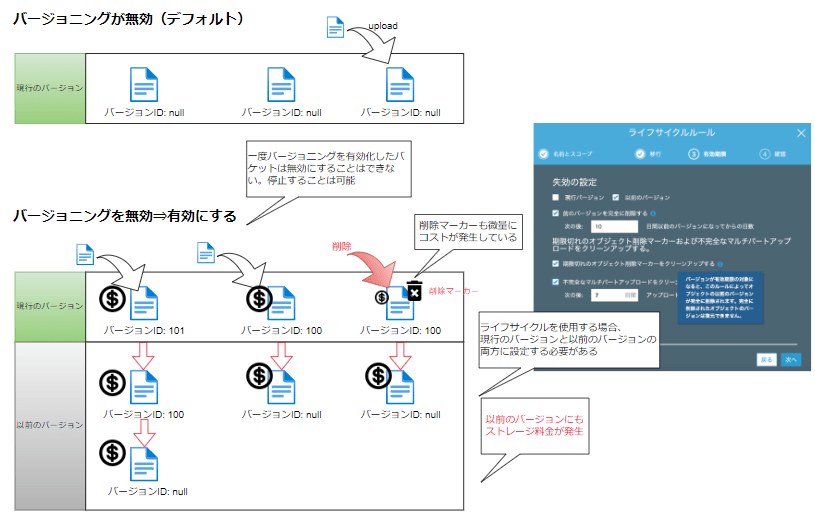
パフォーマンスに影響を与えずに偶発的な上書きや削除から保護するためにアップロードごとに新しいバージョンを生成するオプションです。
削除されたオブジェクトの取得や、過去のバージョンへのロールバックが可能になります。
デフォルトでは無効になっているので利用する場合は、バージョニングを有効にする必要があります。
AWS ドキュメント > S3 バケットでのバージョニングの使用
AWS ドキュメント > バージョニングな有効なバケットへの Amazon S3 リクエストに対する HTTP 503 レスポンスが著しく増加する
暗号化
AWS ドキュメント > サーバー側の暗号化を使用したデータの保護
AWS ドキュメント > クライアント側の暗号化を使用したデータの保護
- サーバー側の暗号化
- S3 データセンター内のディスクに書き込む前に暗号化
- ダウンロードする際に自動的に復号
- Server Side Encryption
- SSE-S3
- S3 によって処理、管理されるキーを使用して暗号化
- 追加料金はなし
- SSE-KMS
- KMS の顧客マスタキー(CMK)を使用して暗号化
- KMS の料金が別途必要
- SSE-C
- 独自の暗号化キーを設定して暗号化
- SSE-S3
- 暗号化は、ディスクが盗難にあった場合でも中身を参照できないようにする目的がある。しかし、AWS のデータセンターに侵入してディスクを盗み出すのはクライアントデバイスより困難だと思われるが・・
- 設定したことによるデメリットがないため、特に要件がない場合でも基本的に SSE-S3 での暗号化はデフォルトで設定しておきます。
- 要件に従い、SSE-KMS や SSE-C などを採用します。
- クライアント側の暗号化
- CSE(Client Side Encryption)
- S3 に送る前にデータを暗号化する方法
- クライアント側暗号化ライブラリ(AWS Encryption SDK)を使用すると暗号化をより容易に実装可能である。
- 機密性が高く、S3 からダウンロードされてしまった場合に情報漏洩されないようにしなければならない場合はこちらを採用する。
- CSE(Client Side Encryption)
静的ウェブサイトのホスティング
AWS ドキュメント > Amazon S3 を使用して静的ウェブサイトをホスティングする
S3 バケット単体で静的ウェブサイトが構築できる機能です。この機能だけでは HTTP アクセスのみですので、HTTPS が必要な場合は他のサービスと組み合わせる必要があります。(CloudFront との併用が最も簡単です)
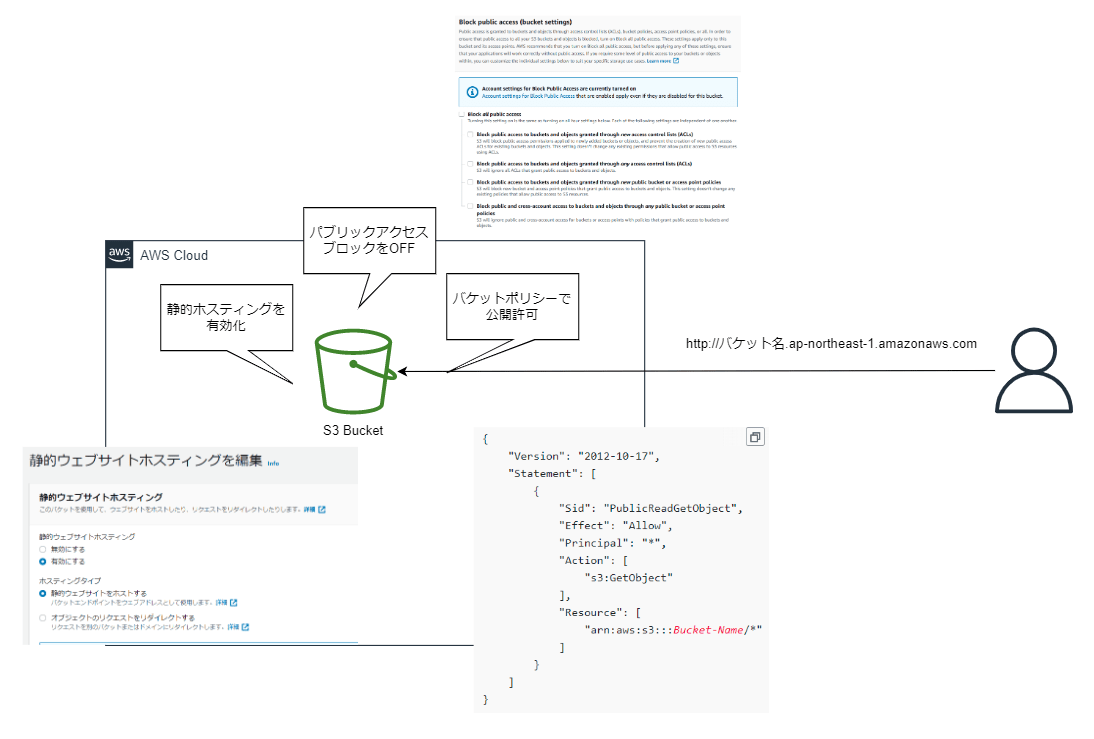
IP 制限をした静的ウェブサイトの設定例

S3 Transfer Acceleration
AWS ドキュメント>Amazon S3 Transfer Acceleration を使用した高速かつ安全なファイル転送の設定

遠方のリージョンからの転送を高速化できます。
同一リージョンで転送する分には問題になりませんが、海外展開している事業で、海外リージョンを利用し、中央リージョンのバケットに対して、世界中からアップロードするようなシステムの場合には、データ転送の距離により遅延が問題になります。
これを解消できる機能です。
大きいオブジェクトの転送の場合、50%から500%まで転送速度を改善することができます。
Transfer Acceleration はバケット単位で有効にします。有効にしたバケットへのファイル転送は、世界中に存在する CloudFront のエッジロケーションを経由してアップロードされます。エッジロケーションから S3 バケットは、AWS 内の最適化されたネットワークで通信されます。
Transfer Acceleration を使用した方が速いと判断された場合は、Transfer Acceleration のエッジロケーションが利用されます。この判定は AWS によって自動的に実施されます。
逆に、遅いと判断された場合は「その転送で使用する S3 Transfer Acceleration の料金を AWS が請求することはなく、S3 Transfer Acceleration システムをバイパスする可能性があります。」と "よくある質問" に記載があります。よって、遅くなるのに無駄に利用してコスト増といったことはないので、安心して利用できます。
ただし、使用するにはいくつか前提条件があります。
例えば、「Transfer Acceleration で使用するバケットは、ピリオド (".") が含まれていない」といったものがあり、使用する場合は既存の状態を確認する必要があります。
その他については、ドキュメントを参照してください。
AWS ドキュメント > Transfer Acceleration を使用するための要件
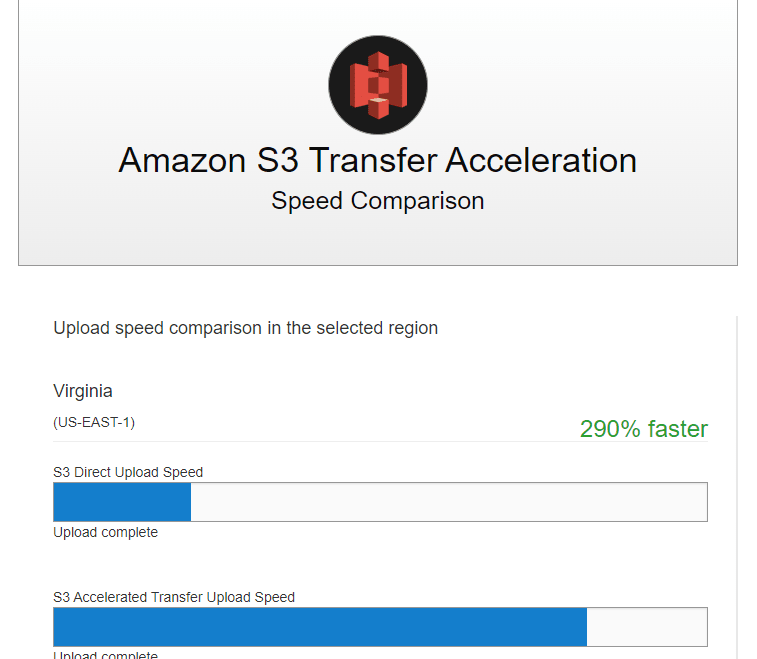
Amazon S3 Transfer Acceleration の速度比較ツール
速度比較ツールを使用すると、高速化した場合と高速化していない場合の Amazon S3 リージョン間でのアップロード速度を比較できます。

ページを開くと計測が開始されます。全部終了するまでに、10 分程度かかります。
このようにマルチパートアップロードによってファイルがアップロードされています。
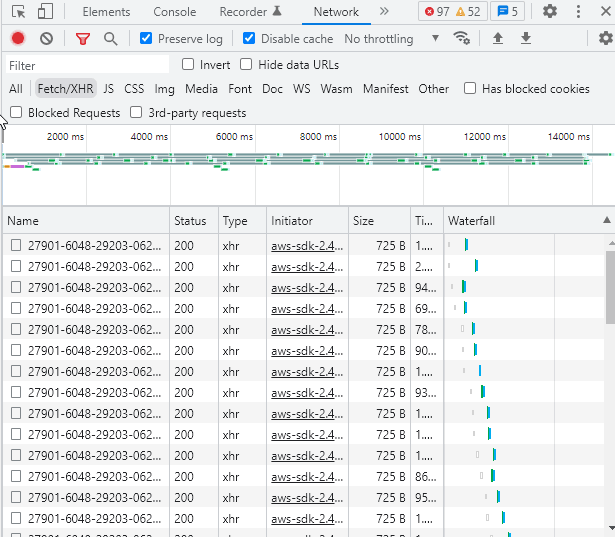
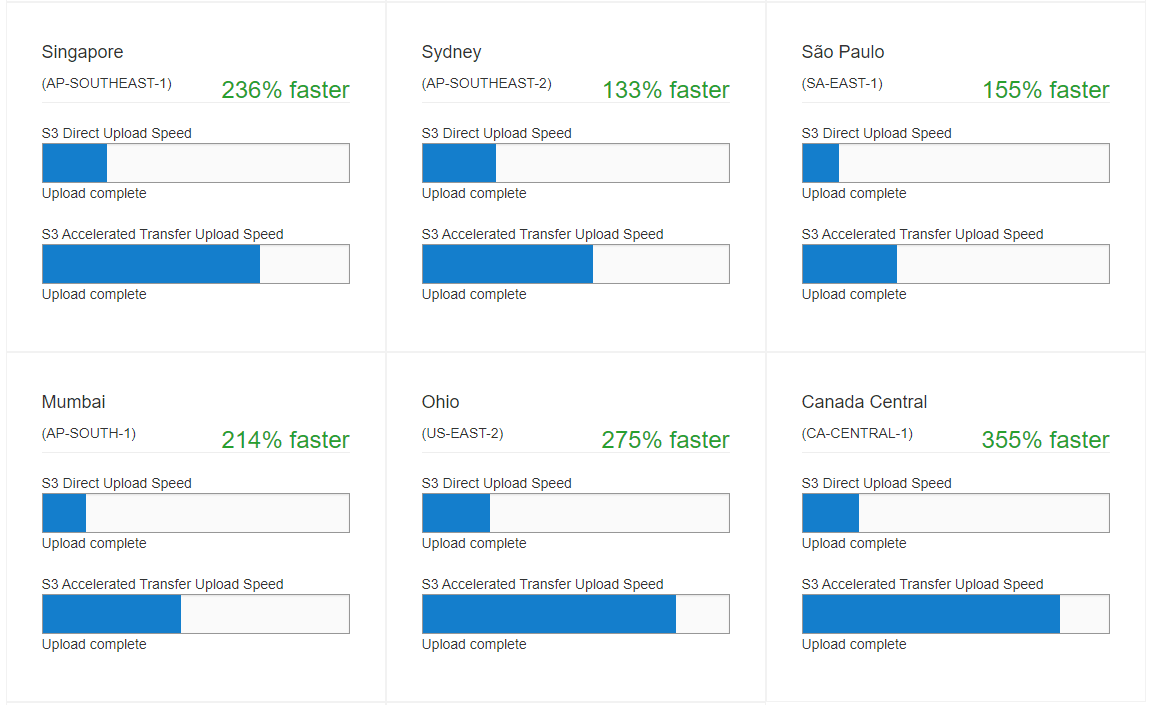
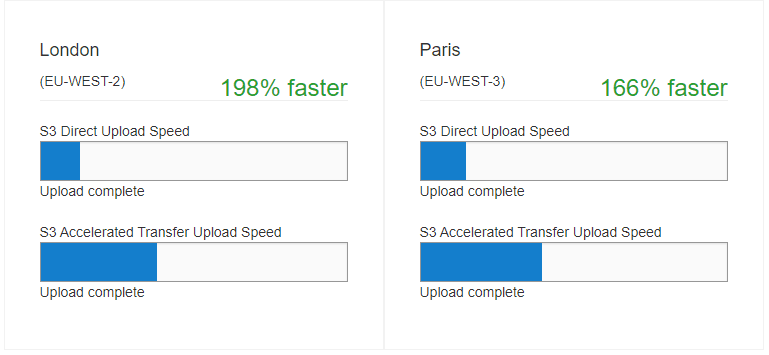
結果はこのように表示されます。
東京 ⇒ 東京リージョンだと、2 %遅くなってます。別のタイミングで実施したら、5%遅くなりました。やはりエッジロケーションを経由する分、遅くなるようです。(実際に利用するときは、AWS が判定を行い、エッジロケーションを経由しない転送にするはず)

リージョンマップにマッピングしてみるとこのようになりました。
リージョン間の距離と比例してスピードアップするわけではなさそうですが、遠方のリージョンの方が明らかにスピードアップしています。
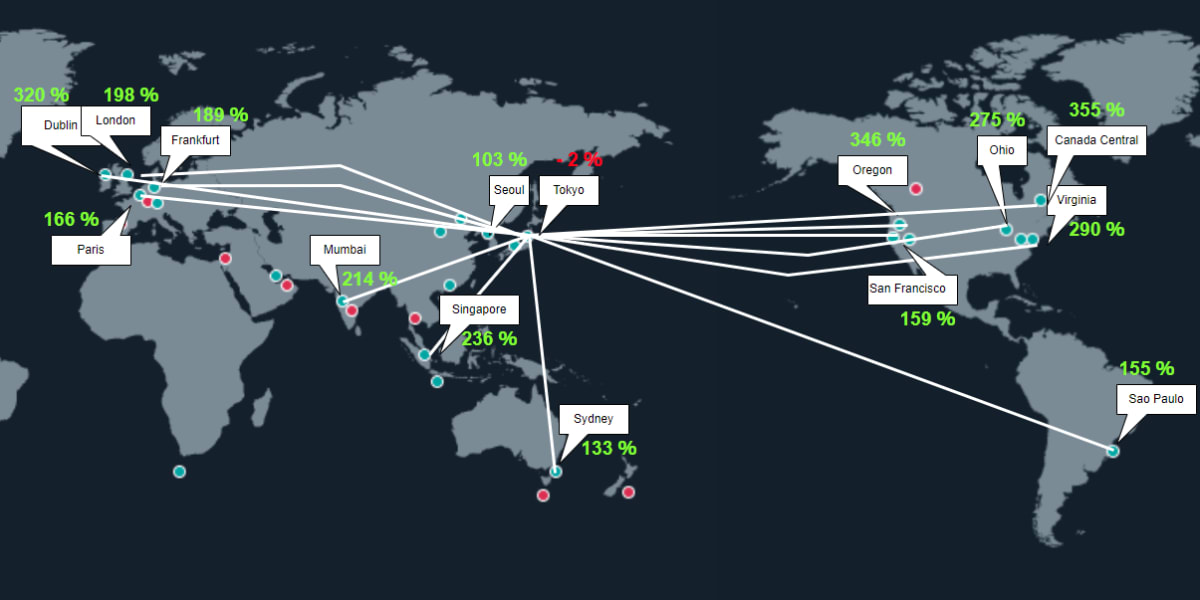
| Rank | Region | ||
|---|---|---|---|
| 1 | CanadaCentral(CA-CENTRAL-1) | 355% | faster |
| 2 | Oregon(US-WEST-2) | 346% | faster |
| 3 | Dublin(EU-WEST-1) | 320% | faster |
| 4 | Virginia(US-EAST-1) | 290% | faster |
| 5 | Ohio(US-EAST-2) | 275% | faster |
| 6 | Singapore(AP-SOUTHEAST-1) | 236% | faster |
| 7 | Mumbai(AP-SOUTH-1) | 214% | faster |
| 8 | London(EU-WEST-2) | 198% | faster |
| 9 | Frankfurt(EU-CENTRAL-1) | 189% | faster |
| 10 | Paris(EU-WEST-3) | 166% | faster |
| 11 | SanFrancisco(US-WEST-1) | 159% | faster |
| 12 | SãoPaulo(SA-EAST-1) | 155% | faster |
| 13 | Sydney(AP-SOUTHEAST-2) | 133% | faster |
| 14 | Seoul(AP-NORTHEAST-2) | 103% | faster |
| 15 | Tokyo(AP-NORTHEAST-1) | 2% | slower |
アクセスログ
AWS ドキュメント > サーバーアクセスログを使用したリクエストのログ記録
バケットに対する監査などの目的で、S3 のサーバアクセスログを別のバケットに保存することができます。

設定する場合、以下に注意する必要があります。
「Amazon S3 バケットについてのサーバーアクセスログを同じバケットにプッシュすることはできますか?」
バケットについてのサーバーアクセスログを同じバケットにプッシュしないでください。
この方法でサーバーアクセスログを設定した場合、ログの無限ループが発生します。
これは、バケットにログファイルを書き込むと、バケットにもアクセスが発生し、別のログを生成するためです。
ログファイルは、バケットに書き込まれるすべてのログに対して生成され、ループが作成されます。
S3 Select
AWS ドキュメント > Amazon S3 Select を使用したデータのフィルタリングと取得
S3 に格納した CSV 形式または JSON 形式のデータをシンプルな構造化クエリ言語 (SQL) の SELECT 文を利用して、検索・集計することができます。
検索対象にできるのは単一のオブジェクトのみです。(Athena のように複数ファイルを対象には出来ません。)
クエリでスキャンされたデータサイズ、返されたデータサブセットのサイズで課金されます。
詳細は以下のドキュメントを参照してください。
AWS ドキュメント > Amazon S3 Select を使用したデータのフィルタリングと取得
AWS WAF のログに対して S3 Select を実行した例です。
WAF のログは 1 行ずつの JSON レコードとなっています。

形式を「JSON」、タイプを「行」、圧縮を「GZIP」とします。
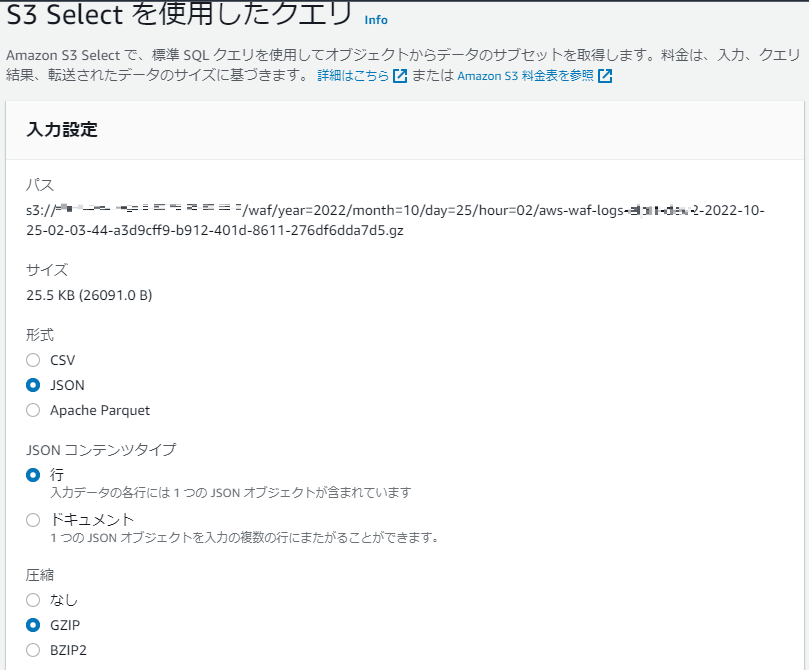
WHERE 句でのカラムの指定は、「s.action」ではなく「s."action"」とする必要がありました。
SELECT * FROM s3object s WHERE s."action" = 'ALLOW' LIMIT 5
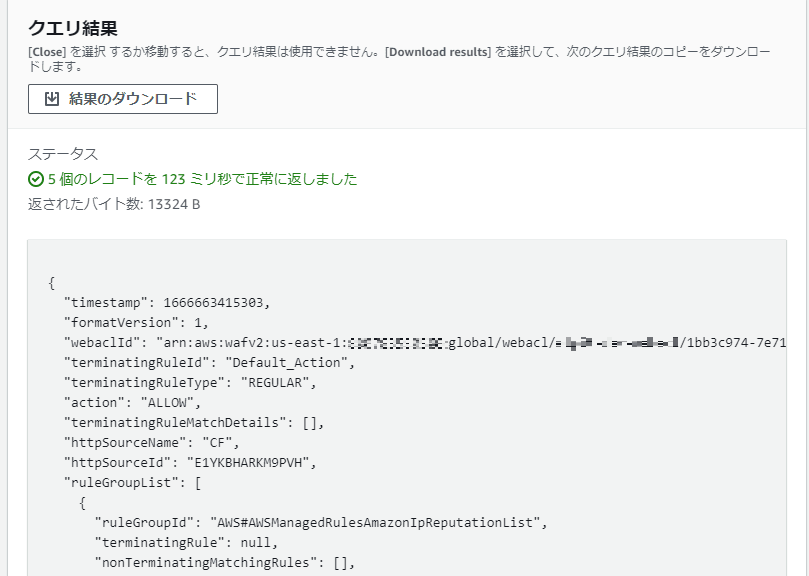
抽出するカラムを絞ってみます(射影)
SELECT s."timestamp", s."terminatingRuleId",s."action" FROM s3object s WHERE s."action" = 'ALLOW' LIMIT 5

対象の日時が特定できている場合は S3 Select を使うことで手軽に検索・集計が可能です。Athena のように事前にテーブル定義を行わなくても検索できるのが便利です。
ただ、対象の日時が特定できない場合や広い範囲を検索したい場合は、Athena を使うほうがよいと思います。
SQL の ORDER が使えないという点も注意が必要です。
単一のファイルという点だと、外部連携ファイルといった単一のファイルであることが多い場合の検索・集計には有用だと思います。
Storage Lens
AWS ドキュメント > S3 Storage Lens
Storage Lens を使うと、オブジェクトストレージの使用状況とアクティビティの傾向を可視化し、ストレージコストの最適化とデータ保護のベストプラクティスの推奨事項を確認することができます。
不要なデータが存在していることや、ライフサイクルが想定通りになっておらず、容量が増加しているなど、分析できます。
デフォルトでは、「default-account-dashboard」というダッシュボードが作成されているので、すぐに分析することができます。
より詳細に分析したい場合は、無料のメトリクスから有料のメトリクスに切り替えることができます。
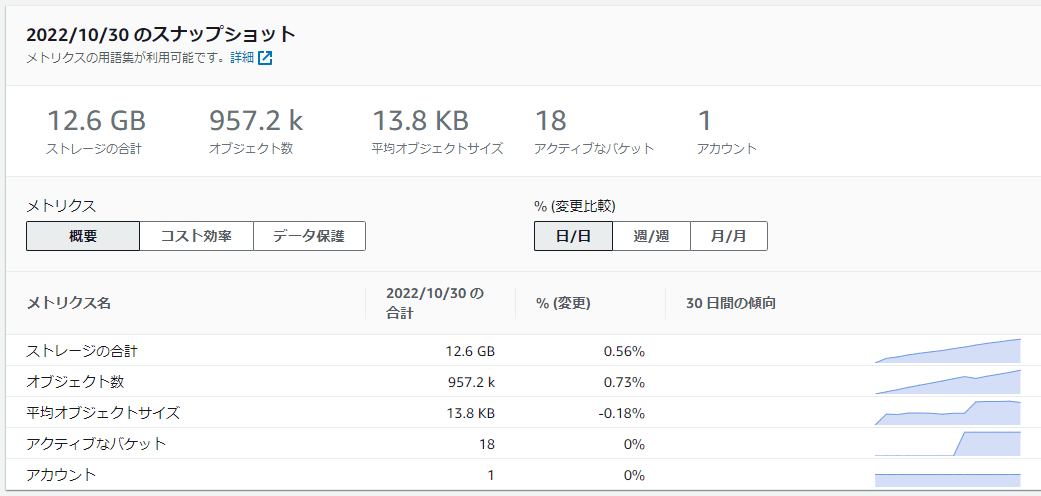
全バケットの概要
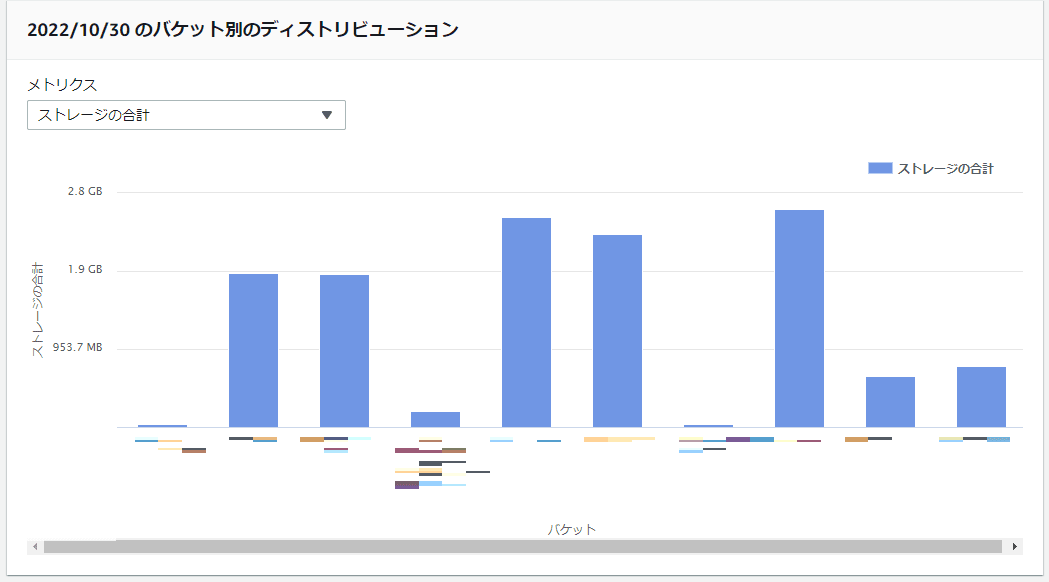
バケットごとの容量推移

バケットごとの現在の容量
現行バージョン、非現行バージョン、削除マーカー、未完了のマルチパートアップロード
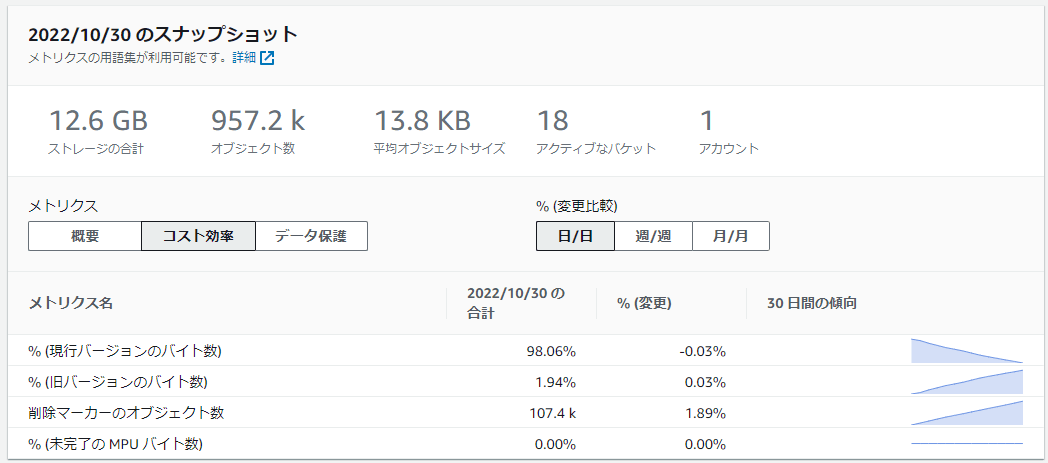
ストレージクラスごと

リクエスタ支払いバケット
AWS ドキュメント > ストレージ転送と使用量のリクエスタ支払いバケットの使用
通常、バケットのデータ保存容量とデータ転送にかかるコストはバケット所有者が負担します。別のアカウントとバケットを共有指定いる場合もバケット所有者が負担します。
共有先からのダウンロードが大量に発生する場合、バケット所有者の負担が大きくなってしまいます。
そのような場合、リクエスタ支払いを行うことで、データを取得した先のアカウントに料金を負担してもらうことができます。
リクエスタ支払いを有効にしたバケットは、所有者を除き、通常の方法ではアクセスできなくなります。
アクセスする場合、HTTP アクセスはリクエストヘッダに"x-amz-request-payer"を付けることで、リクエスタ側が明示的にデータアクセスに対して料金を負担することを了承したことになります。
AWS CLI の場合は、オプションに「--request-player」を付与します。
アクセスポイント
AWS ドキュメント > Amazon S3 アクセスポイントを使用したデータアクセスの管理
バケットに複数のユーザーやアカウントからアクセスがある場合、バケットポリシーでの設定が煩雑になります。
そこで、用途ごとにアクセスポイントを作成することで、アクセスポイントごとのポリシーを定義することができます。
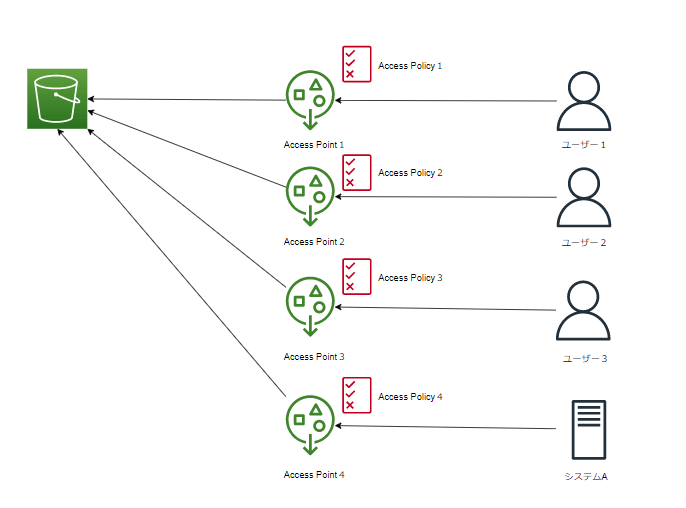
このように、アクセスポイントポリシーを定義できます。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::123456789012:user/Alice"
},
"Action": ["s3:GetObject", "s3:PutObject"],
"Resource": "arn:aws:s3:us-west-2:123456789012:accesspoint/my-access-point/object/Alice/*"
}
]
}
詳しくは、AWS ドキュメント > アクセスポイントポリシーの例を参照してください。
パフォーマンスの最適化
AWS ドキュメント > 設計パターンのベストプラクティス: Amazon S3 のパフォーマンスの最適化
以前は、連続するキープレフィックスのオブジェクトを作成すると、パフォーマンス上の問題がありましたが、現在ではそのような問題は発生しません。
BucketName/2022-11-02/aaa/xxx000000001.log
BucketName/2022-11-02/aaa/xxx000000002.log
BucketName/2022-11-02/aaa/xxx000000003.log
BucketName/2022-11-02/aaa/xxx000000004.log
BucketName/2022-11-03/aaa/zzz000000001.log
BucketName/2022-11-03/aaa/zzz000000002.log
BucketName/2022-11-03/aaa/zzz000000003.log
BucketName/2022-11-03/aaa/zzz000000004.log
以前はこのようにランダムにして対処していました。
BucketName/232a-2022-11-02/aaa/xxx000000001.log
BucketName/5akg-2022-11-02/aaa/xxx000000002.log
BucketName/gsrt-2022-11-02/aaa/xxx000000003.log
:
現在はこのままでも問題はありません。
BucketName/2022-11-02/aaa/xxx000000001.log
BucketName/2022-11-02/aaa/xxx000000002.log
BucketName/2022-11-02/aaa/xxx000000003.log
BucketName/2022-11-02/aaa/xxx000000004.log
さらに、現在は、PUT/COPY/POST/DELETE のリクエストを 3,500 回/秒、GET/HEAD リクエストを 5,500 回/秒 以上を処理できるため、高アクセスを除いて特に問題は発生しません。
だた、高アクセスなシステムの場合、上記敷居値を超えるリクエストを送信すると HTTP 503 が返ってくることがあります。
このようなケースに対応するには、「パーティションされたプレフィックス」を複数使用することを検討します。
上記敷居値は「パーティションされたプレフィックス」ごとの数値であるため、これを並列化することで、よりパフォーマンスを向上できます。
「パーティションされたプレフィックス」とは何かというと、オブジェクトキー名の先頭にある文字列(プレフィックス)です。
下記例だと、「パーティションされたプレフィックス」は 2022-11-02/aaa が該当します。
オブジェクトキー名の最大長 (1,024 バイト)の制限の中で、プレフィックスを増やすことで、並列化によってパフォーマンスを向上させることができます。
BucketName/2022-11-02/aaa/xxx000000001.log
BucketName/2022-11-02/aaa/xxx000000001.log
BucketName/2022-11-02/aaa/xxx000000001.log
BucketName/2022-11-02/aaa/xxx000000001.log
📖 他のサービスとの連携
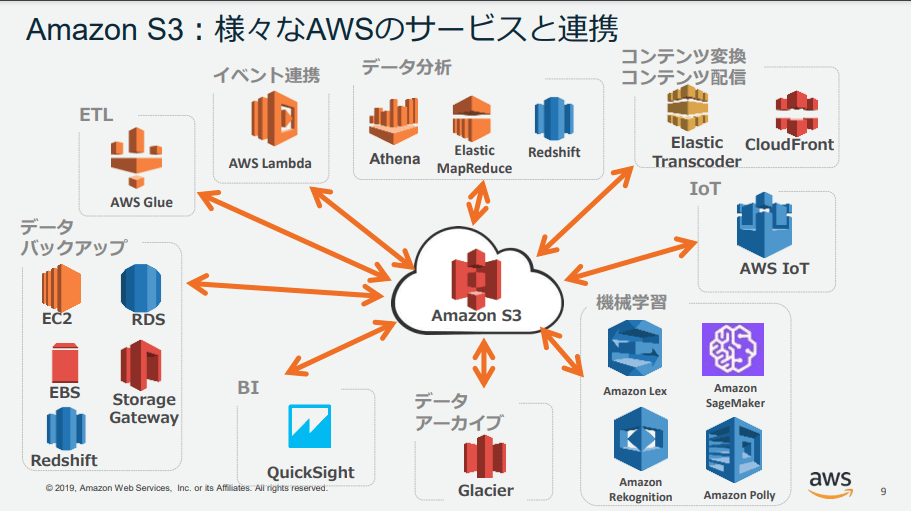
2019 年頃の資料のため、現在では AWS WAF も直接 S3 へログ配信できるようになっているため連携できるサービスが増えています。
Discussion