【読書会】「AWSではじめる生成AI」12章:生成AIのマネージドサービス Amazon Bedrock
Contents
- はじめに
- 本書の目次
- 12 章 生成 AI のマネージドサービス Amazon Bedrock
- 12.1 Amazon Bedrock の基盤モデル
- 12.2 Amazon Bedrock の推論 API
- 12.3 大規模言語モデル
- 12.4 微調整
- 12.5 エージェント
- 12.6 マルチモーダルモデル
- 12.7 データプライバシーとネットワークセキュリティ
- 12.8 ガバナンスと監視
- 12.9 まとめ
- まとめ
はじめに
本記事は、オライリー・ジャパンより 2024/8/2 に発売された「AWS ではじめる生成 AI―RAG アプリケーション開発から、基盤モデルの微調整、マルチモーダル AI 活用までを試して学ぶ」を使った社内読書会用の資料となります。内容の一部を簡略化したり、誤りが含まれている可能性があります。また、サンプルコードは一部変更している部分があります。詳細は書籍をご参照ください。

本書の目次
- 1 章 生成 AI のユースケース、基礎、プロジェクトライフサイクル
- 2 章 プロンプトエンジニアリングとコンテキスト内学習
- 3 章 大規模言語モデル
- 4 章 メモリーと計算リソースの最適化
- 5 章 微調整と評価
- 6 章 パラメーター効率的微調整
- 7 章 人間のフィードバックからの強化学習を用いた微調整
- 8 章 モデルのデプロイの最適化
- 9 章 RAG とエージェントにより文脈に応じた論理的判断を行うアプリケーション
- 10 章 マルチモーダル基盤モデル
- 11 章 Stable Diffusion による生成の制御と微調整
- 12 章 生成 AI のマネージドサービス Amazon Bedrock ←★ 本記事の対象 ★
- 日本語版付録 生成 AI 搭載アシスタント Amazon Q
12 章 生成 AI のマネージドサービス Amazon Bedrock
12 章では、Amazon Bedrock の基盤モデルや API へのアクセス方法について具体的なユースケースやコードを使用した実装方法を学びます。
12.1 Amazon Bedrock の基盤モデル
ここでは、Amazon Bedrock の基盤モデルについての説明があります。
Amazon Bedrock には Amazon が提供している基盤モデルに加え、さまざまなサードバーティの基盤モデルが使用できます。使用可能なモデルはコンソールで確認するか、AWS CLI や AWS SDK からもアクセスできます。
コンソールでモデルの一覧はこのような表示になります。
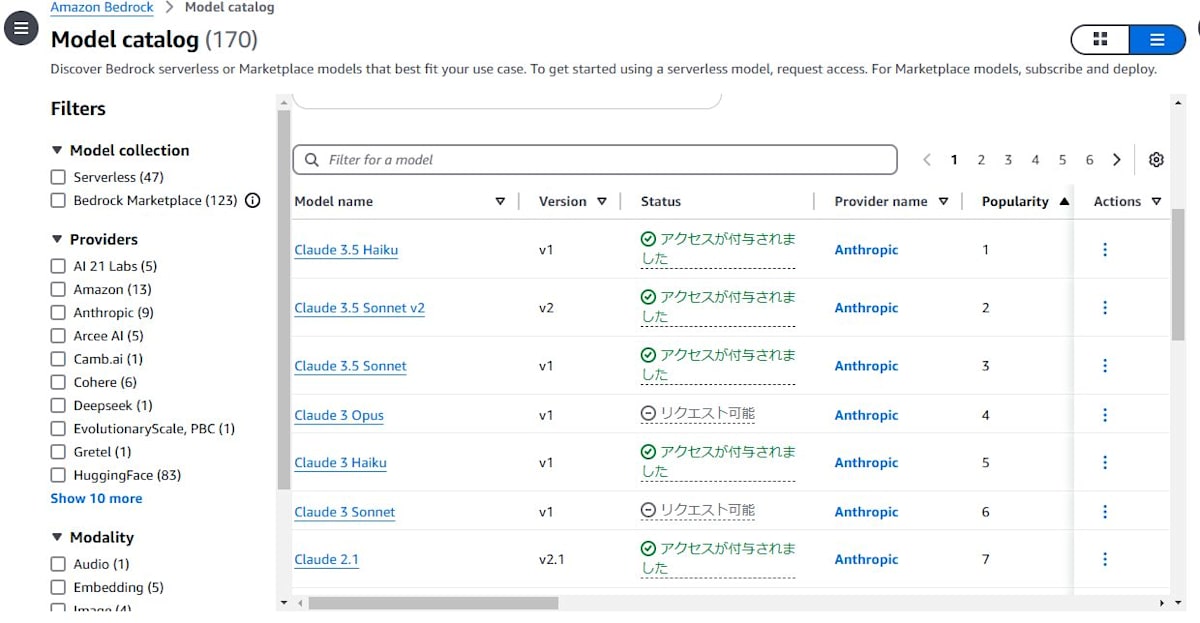
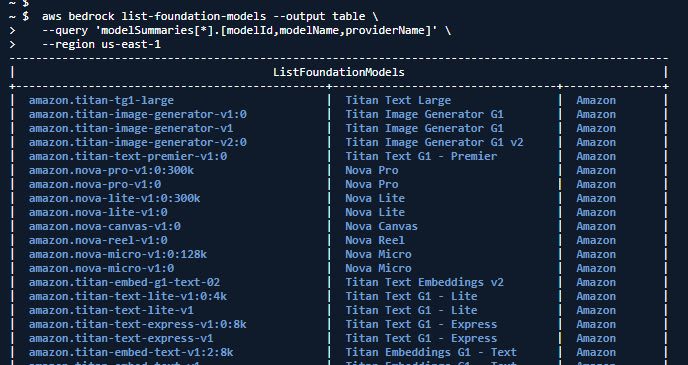
AWS CLI の場合は、[bedrock list-foundation-models]を使います。
aws bedrock list-foundation-models --output table \
--query 'modelSummaries[*].[modelId,modelName,providerName]' \
--region us-east-1
AWS SDK(Python)の場合は、[list_foundation_models]を使います。
import json
import boto3
from logging import getLogger, INFO, DEBUG
logs = boto3.client('logs')
logger = getLogger()
logger.setLevel(INFO)
# Bedrockクライアントの初期化
bedrock = boto3.client('bedrock')
def lambda_handler(event, context):
# 利用可能な基盤モデルの一覧を取得
# list_foundation_models() はBedrockで利用可能なすべてのモデルを返します
response = bedrock.list_foundation_models()
# レスポンスからモデル情報を取得
# modelSummariesには各モデルの基本情報(ID、名前、プロバイダーなど)が含まれます
models = response["modelSummaries"]
logger.info("Got %s foundation models.", len(models))
# 各モデルの情報をログに出力
for model in models:
model_id = model["modelId"] # モデルの一意識別子
model_name = model["modelName"] # モデルの表示名
logger.info("Model ID: %s, Model Name: %s", model_id, model_name)
return {
'statusCode': 200,
'body': json.dumps(models)
}
テキストを扱うモデルで、オンデマンドのものだけを抽出するには次のように条件を指定できます。これによって、ほしいモデルだけリストアップできます。
# テキスト処理に特化したオンデマンドモデルのみを取得
client.list_foundation_models(
byOutputModality="TEXT", # 出力モダリティを「テキスト」に限定
byInferenceType="ON_DEMAND" # オンデマンド推論が可能なモデルに限定
)
これらのモデルは、モデルプレイグラウンドを使ってマネジメントコンソール上で試すことができます。
10 章にあった画像生成の例文「草の上に寝そべる犬の写真を作成してください」を入力した場合は、このような結果になります。
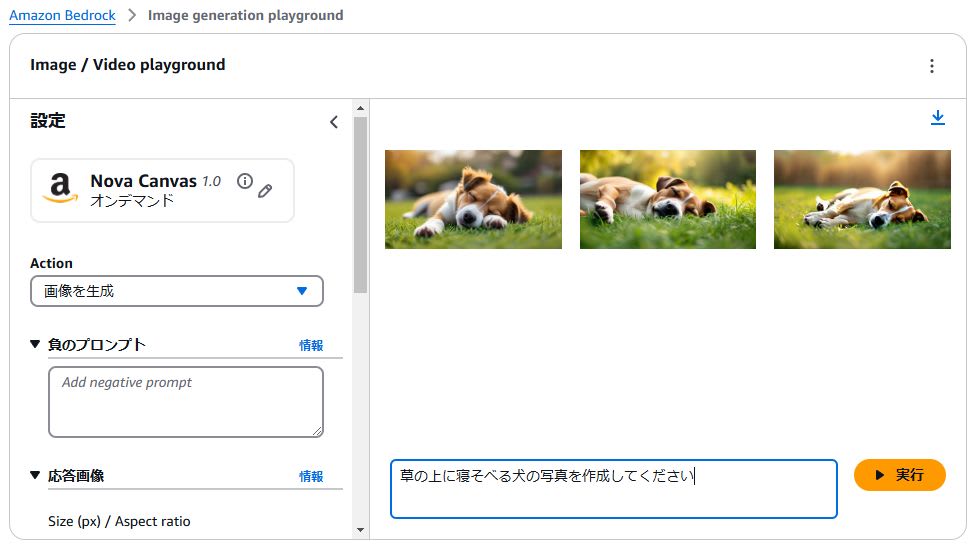

生成された画像を選択すると、「バリエーションを生成/Remove object/Replace backgroupd/Replace object/背景を削除」というアクションを追加で実行できます。 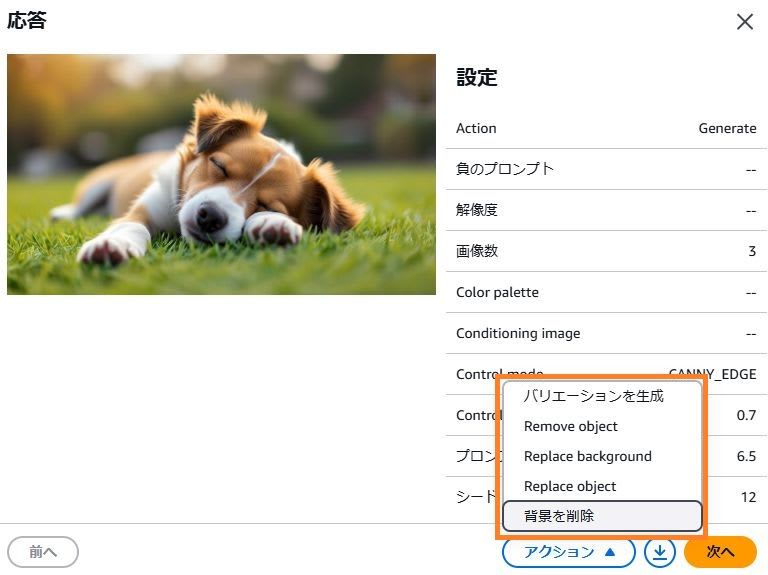
さらに、以下の基盤モデルについての説明があります。詳細は、公式サイトなどを参照するとよいでしょう。
- Amazon Titan 基盤モデル
- Amazon が提供する高性能基盤モデル
- 詳細は公式サイトを参照
- Stable Diffusion 基盤モデル
- Stability AIが提供するテキスト画像生成モデル
余談
「Yahoo!ニュース:2024/1/31)全世界が驚いた中国製生成 AI「DeepSeek-r1」は何がどうすごいのか」で話題のモデルも選択できます。

今のところサーバーレスでの利用ができませんので、デプロイする必要があります。
具体的な方法は、次の記事を参照してください。
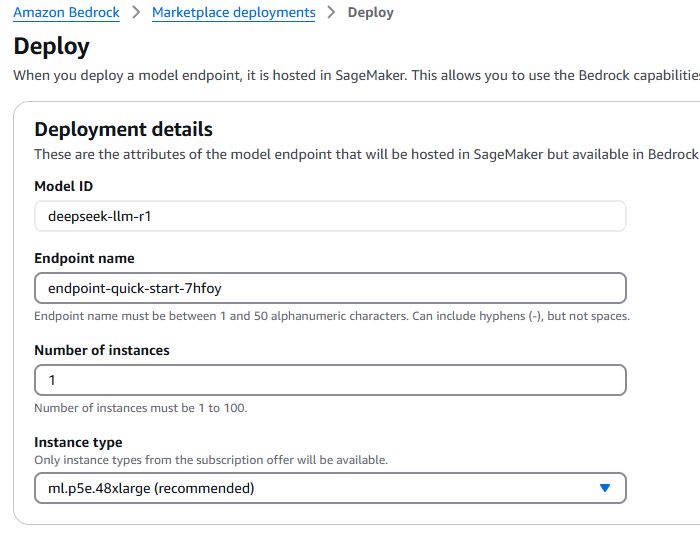
インスタンスには、vCPU 192、メモリ 2TiB、GPU メモリ 1,128 GB HBM3e というびっくりなスペックの ml.p5e.48xlarge が必要です。料金については、EC2 Capacity Blocks for ML pricingを使う必要がありますので参照してください。
デプロイではなく S3 に自分で配置したモデルをインポートできます。インポート方法については、 AWS ブログ:Amazon Bedrock で DeepSeek-R1 Distilled Llama モデルをデプロイするを参照してください。
12.2 Amazon Bedrock の推論 API
ここでは推論 API の呼び出し方法について説明があります。
Python SDK(boto3)を使う場合は、[invoke_model()]を使って推論 API に対してリクエストを実行します。
import boto3
# Bedrock Runtime クライアントの初期化
# 注:推論には bedrock-runtime を使用します(bedrock ではありません)
bedrock_runtime = boto3.client('bedrock-runtime')
# リクエストヘッダーの設定
accept = "application/json"
contentType = "application/json"
# モデルを使用して推論を実行
response = bedrock_runtime.invoke_model(
modelId='anthropic.claude-3-5-sonnet-20240620-v1:0', # 使用するモデルのID
body={ # モデルに送信するリクエストボディ
"prompt": "富士山の高さは?", # プロンプトテキスト
"max_tokens": 1000, # 生成する最大トークン数
"temperature": 0.7 # 「創造性」や「予測不能さ」を調整するパラメータ(高いほど創造的、低いほど決定的)
},
accept=accept,
contentType=contentType
)
# レスポンスの処理
response_body = json.loads(response.get('body').read())
# レスポンスからメッセージを抽出
answer = response_body["content"][0]["text"]
return {
'statusCode': 200,
'body': json.dumps({
'prompt': prompt,
'message': answer
})
}
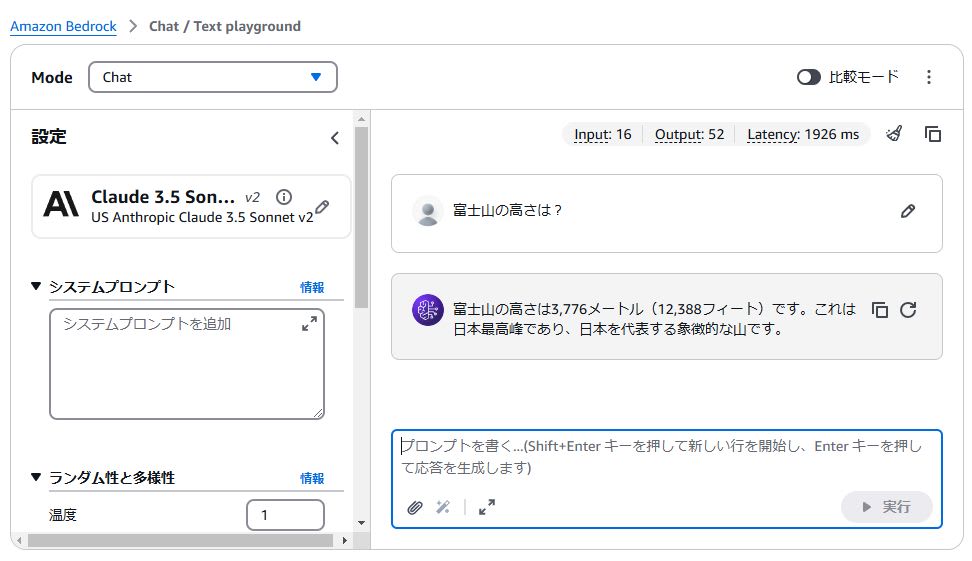
answerに格納される回答例は次のようになります。
富士山の高さは、3,776メートル(12,388フィート)です。
この高さは、日本の国土地理院による最新の公式測定結果に基づいています。富士山は:
1. 日本で最も高い山
2. 日本の象徴的な景観の一つ
3. 活火山(現在は休火山状態)
4. ユネスコ世界文化遺産に登録(2013年)
富士山の高さは、時代によって若干の変動があります。これは火山活動や地殻変動などの自然現象によるものです。しかし、大きな変化はなく、3,776メートルという高さは長年にわたって広く認識されている数値です。
このほかに、[InvokeModelWithResponseStream]という API があります。これはレスポンスがストリームとして送信されます。
12.3 大規模言語モデル
ここでは推論 API の使い方について、生成 AI のよくあるユースケースについての説明があります。
- SQL コードの生成
- テーブルの情報を与えて、どういった SQL を生成してほしいか指示する
- テキストの要約
- 与えた文章の要約を生成する
- 埋め込み
- 入力を埋め込みと呼ばれる数値ベクトルに変換
- ユースケース:セマンティック検索、推薦、分類
- 画像を比較し視覚的な類似性を判断、テキストと画像を比較し関連性を判断など
※セマンティック検索とは?
- 検索文の意味を理解して、関連性の高い情報を提供する技術
- 埋め込みに変換(ベクトル化)→ 既存のベクトルと照合 → 関連性に基づいて結果をランク付け
- 参考:セマンティック検索 - AI 用語集 - ソフトバンク
SQL コードの生成
import boto3
import json
bedrock_runtime = boto3.client('bedrock-runtime')
def lambda_handler(event, context):
try:
prompt = '''
「id」、「age」、「year_enrollment」、「subject」、「grade」という各フィールドがある「students」というテーブルがあります。
一番「age」が高い「id」を返すSQLクエリーを書いてください。
'''
modelId = "anthropic.claude-3-5-sonnet-20240620-v1:0"
accept = "application/json"
contentType = "application/json"
body = json.dumps(
{
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 1000,
"messages": [
{
"role": "user",
"content": prompt
}
]
}
)
response = bedrock_runtime.invoke_model(
body=body,
modelId=modelId,
accept=accept,
contentType=contentType
)
# レスポンス
response_body = json.loads(response.get("body").read())
# レスポンスからメッセージを抽出
answer = response_body["content"][0]["text"]
print(answer)
except Exception as e:
print(e)
得られる回答は次のようになります。
この回答は、本書の例文をそのまま使用して得られたものです。実際には、実用的な SQL クエリが返ってきたかどうかをしっかり確認し、必要に応じて詳細な指示が必要です。
以下のSQLクエリを使用して、「students」テーブルから最も年齢が高い学生のIDを取得できます:
SELECT id
FROM students
WHERE age = (SELECT MAX(age) FROM students)
LIMIT 1;
このクエリの説明:
1. サブクエリ (SELECT MAX(age) FROM students) で、テーブル内の最高年齢を取得します。
2. メインクエリでは、この最高年齢と一致する学生の ID を選択します。
3. LIMIT 1 を使用して、結果を 1 行に制限します。これは、同じ最高年齢の学生が複数いる場合に、そのうちの 1 人の ID のみを返すためです。
注意点:
- 同じ最高年齢の学生が複数いる場合、このクエリはそのうちの 1 人の ID をランダムに返します。
- すべての同年齢の学生の ID を取得したい場合は、LIMIT 1 を削除してください。また、データベースによっては、以下のような別の方法も使用できます:
SELECT id
FROM students
ORDER BY age DESC
LIMIT 1;
このクエリは年齢で降順にソートし、最初の結果(最高年齢の学生)の ID を返します。
テキストの要約
import boto3
import json
bedrock_runtime = boto3.client('bedrock-runtime')
def lambda_handler(event, context):
try:
prompt = '''
以下のテキストの要約を提供してください。
下のテキスト内で言及されていない情報は1つも付け加えないようにしてください。
<text>
AWSはお客様のフィードバックを全て受け止めています。そして本日、
基盤モデルをAPIを通じてアクセス可能にする新サービス
Amazon Bedrockを発表できることを喜ばしく思います。
Amazon Bedrockは、基盤モデルを用いて生成AIベースのアプリケーションを
開発しスケールさせるための、お客様にとって最も簡単な方法であり、
すべての開発者のみなさまに向けて基盤モデルへのアクセスを民主化するものです。
</text>
'''
modelId = "anthropic.claude-3-5-sonnet-20240620-v1:0"
accept = "application/json"
contentType = "application/json"
body = json.dumps(
{
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 1000,
"messages": [
{
"role": "user",
"content": prompt
}
]
}
)
response = bedrock_runtime.invoke_model_with_response_stream(
body=body,
modelId=modelId,
accept=accept,
contentType=contentType
)
# レスポンス
stream = response.get("body")
output = []
# レスポンスからメッセージを抽出
if stream:
for event in stream:
chunk = event.get('chunk')
if chunk:
chunk_json = json.loads(chunk.get("bytes").decode())
print('chunk_json: {}'.format(chunk_json))
if chunk_json["type"]=="content_block_delta":
text = chunk_json["delta"]["text"]
output.append(text)
print(''.join(output))
return {
'statusCode': 200,
'body': json.dumps({
'prompt': prompt,
'message': ''.join(output)
})
}
except Exception as e:
print(e)
chunk_json で得られる内容は次のとおりです。content_block_start ~ content_block_stop の間が回答内容になっています。
{'type': 'content_block_start', 'index': 0, 'content_block': {'type': 'text', 'text': ''}}
{'type': 'content_block_delta', 'index': 0, 'delta': {'type': 'text_delta', 'text': 'ここにテキスト'}}
{'type': 'content_block_delta', 'index': 0, 'delta': {'type': 'text_delta', 'text': 'ここにテキスト'}}
:
{'type': 'content_block_delta', 'index': 0, 'delta': {'type': 'text_delta', 'text': 'ここにテキスト'}}
{'type': 'content_block_stop', 'index': 0}
{'type': 'message_delta', 'delta': {'stop_reason': 'end_turn', 'stop_sequence': None}, 'usage': {'output_tokens': 156}}
{'type': 'message_stop', 'amazon-bedrock-invocationMetrics': {'inputTokenCount': 244, 'outputTokenCount': 156,
具体的には、次のような応答内容を結合することになります。
{'type': 'content_block_delta', 'index': 0, 'delta': {'type': 'text_delta', 'text': '要'}}
{'type': 'content_block_delta', 'index': 0, 'delta': {'type': 'text_delta', 'text': '約:'}}
{'type': 'content_block_delta', 'index': 0, 'delta': {'type': 'text_delta', 'text': '\n\nAWSが'}}
{'type': 'content_block_delta', 'index': 0, 'delta': {'type': 'text_delta', 'text': '新'}}
{'type': 'content_block_delta', 'index': 0, 'delta': {'type': 'text_delta', 'text': 'サ'}}
{'type': 'content_block_delta', 'index': 0, 'delta': {'type': 'text_delta', 'text': 'ービス'}}
:
:(略)
:
{'type': 'content_block_delta', 'index': 0, 'delta': {'type': 'text_delta', 'text': 'を反'}}
{'type': 'content_block_delta', 'index': 0, 'delta': {'type': 'text_delta', 'text': '映して'}}
{'type': 'content_block_delta', 'index': 0, 'delta': {'type': 'text_delta', 'text': '開'}}
{'type': 'content_block_delta', 'index': 0, 'delta': {'type': 'text_delta', 'text': '発されました。'}}
最終的に得られる回答は次のようになります。
要約:
AWSが新サービスAmazon Bedrockを発表しました。これは以下の特徴を持つサービスです:
1. 基盤モデルをAPIを通じてアクセス可能にする
2. 生成AIベースのアプリケーションを開発・スケールさせるための最も簡単な方法
3. すべての開発者向けに基盤モデルへのアクセスを民主化する
このサービスはお客様のフィードバックを反映して開発されました。
埋め込み
Amazon Titan Text 埋め込みモデルを使った実装例です。
import boto3
import json
bedrock_runtime = boto3.client('bedrock-runtime')
accept = "application/json"
contentType = "application/json"
def get_embedding(body, modelId):
response = bedrock_runtime.invoke_model(
body=body,
modelId=modelId,
accept=accept,
contentType=contentType
)
response_body = json.loads(response.get('body').read())
embedding = response_body.get('embedding')
return embedding
def lambda_handler(event, context):
try:
prompt = '富士山の高さは?'
body = json.dumps(
{
"inputText": prompt
}
)
modelId = "amazon.titan-embed-text-v1"
embedding = get_embedding(body, modelId)
print(embedding)
return {
'statusCode': 200,
'body': json.dumps({
'prompt': prompt,
'message': embedding
})
}
except Exception as e:
print(e)
埋め込みベクトルは次のようになっています。
[1.3671875, 0.392578125, 0.23828125,..., -0.216796875, 0.42578125]
ほかの実装例として、ヒートマップ生成がありました。
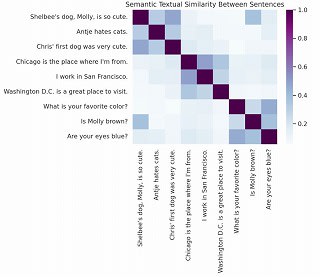
12.4 微調整
ここでは、微調整についての説明があります。
微調整とは、基盤モデルを独自のラベル付きトレーニングデータセットでカスタマイズして、モデルの精度を高めてより専門性を持たせることです。
専門性とは、例えば以下のようなものです。
- 特定の業界用語の理解
- 社内文書の分類や要約
- 専門分野での質問応答
微調整はコンソールや SDK で実行できます。本書籍内では Python SDK(boto3)を使用した例が記載されています。
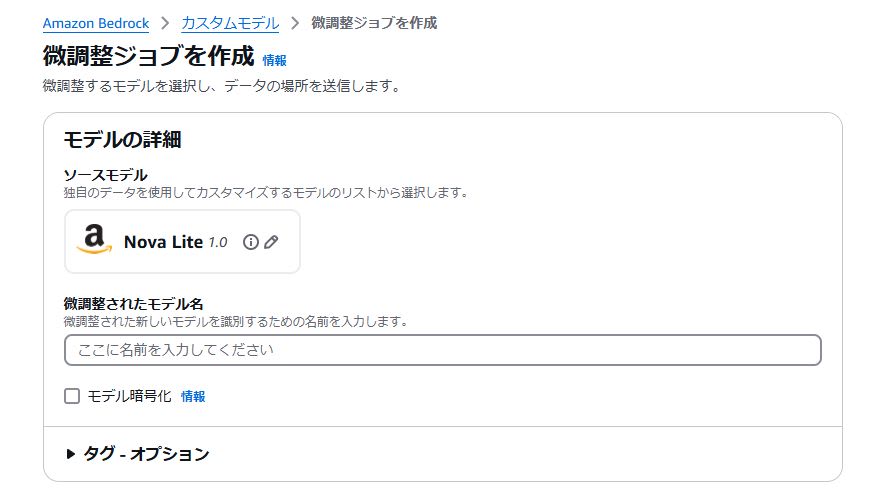
12.5 エージェント
ここではエージェントについての説明があります。
生成 AI を活用する際、チャットは最も一般的な利用形態の 1 つです。しかし、精度の高い回答を得るためには、ユーザーが詳細な指示を与える必要があります。これを毎回実施することや、組織内で統一した品質の指示を維持することは困難です。
「エージェント」は、このような課題を解決するため、特定のタスクや目的に対して、事前に定められた手順や判断基準に基づいて自律的に処理を実行する仕組みです。
AWS 公式ページに記載されているエージェントの仕組み
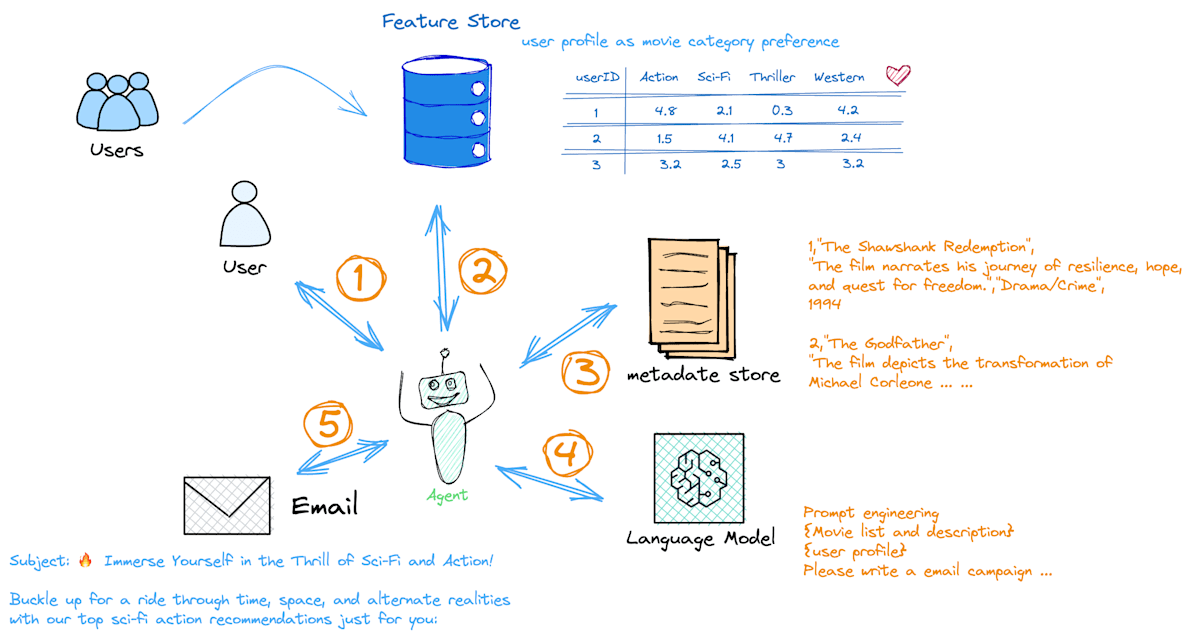
エージェントの主要な構成は次のとおりです。
-
ベースプロンプト
- ここでの指示だけでもエージェントを利用可能
あなたは優秀なAIアシスタントです。ユーザーからの質問や指示に対して以下の手順で適切な回答を提供してください。 1. xxxxxx 2. xxxxxx 3. xxxxxx 4. xxxxxx -
アクショングループ
- エージェントが実施すべき行動を定義する
- 例えば外部サイトに情報を取得するなど、回答の精度を上げる処理を追加する
- 「思考の連鎖(CoT)」によって基盤モデルの動作を拡張可能
-
ナレッジベース
- 参照させたいドキュメントがある場合に利用する
エージェントの仕組みを理解するには、「Amazon Bedrock 生成 AI アプリ開発入門」の以下が参考になります。
- 「5.3 Agents for Amazon Bedrock とは」
- 「5.4 ハンズオン Agents で AI エージェントを作ってみよう」

※IT エンジニア本大賞 2025 技術書部門ベスト 10にも選出されていますのでおすすめです
参考:マルチエージェント
エージェントは非常に便利な機能ですが、エージェントに実施してほしいタスクが多くなると1つのエージェントの責務が肥大化していきます。その結果、プロンプトやコードが複雑化し、実装やテストが困難になるという課題があります。
この課題を解決する1つの方法として、マルチエージェントが発表されました。
AWS re:Invent 2024 にて発表された Amazon Bedrock の新機能「マルチエージェントコラボレーション」
簡単にいうと、複数の AI エージェントがタスクを分担して実行し、結果を議論することで単一のエージェントよりも良い結果を返すための手法です。
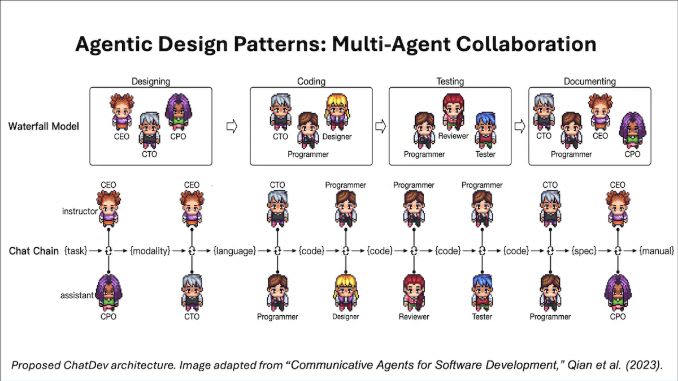
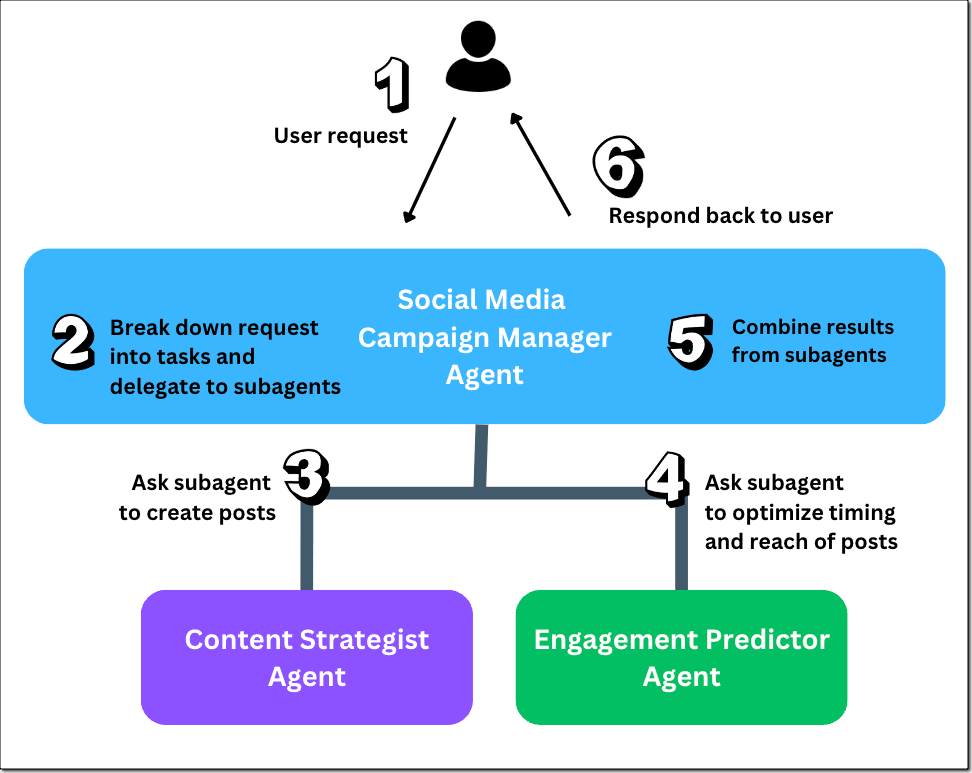
マルチエージェントにはいくつかの実装パターンがありますが、Bedrock のマルチエージェントは「Supervisor」パターンになります。
1 人のリーダーがメンバーをコントロールし、意見を集約するようなイメージです。
12.6 マルチモーダルモデル
ここではマルチモーダルモデルについての説明があります。
マルチモーダルモデルとは、異なる種類の情報をまとめて扱うことができるモデルのことです。
- 画像+音声+テキスト → 環境を判断
例えば、映像と音から、音の発生がどこからなのか判断する、といったことができるようになります。
逆に、シングルモーダル(または、ユニモーダル)では単一のデータしか扱えません。
- 画像 → 顔認識
- 音声 → 文字変換
- テキスト → 要約
12.7 データプライバシーとネットワークセキュリティ
ここでは Amazon Bedrock のデータプライバシーとネットワークセキュリティについての説明があります。
まとめると、Amazon Bedrock のセキュリティは以下の 3 つの観点で確保されています。
- データプライバシー
- AWS Bedrock のプロンプトやモデルは AWS アカウント内のアクセスで非公開である
- データがサードパーティーと共有されることはない
- 欧州連合の一般データ保護規則(GDPR、General Data Protection Regulation)
- 通信およびネットワークセキュリティ
- 通信は TLS 1.2 以上で暗号化
- VPC エンドポイントでプライベートな接続を実現できる
- 企業ネットワークとは、AWS Direct ConnectやAWS Site-to-Site VPN利用
- データセキュリティ
- 保存データはAWS KMSでの暗号化
12.8 ガバナンスと監視
ここでは Amazon Bedrock のガバナンスと監視についての説明があります。
まとめると、Amazon Bedrock の運用管理は以下の 3 つの仕組みで実現されています。
- アクセス制御
- AWS IAM によるアクセス制御
- 監査ログ
- AWS CloudTrail による API アクティビティの記録
- モニタリング
- Amazon CloudWatch や Amazon S3 を使用したログの記録
- メトリクスによる利用状況の可視化
12.9 まとめ
ここでは、12 章で学んだことの総括が書かれています。
まとめ
12 章は、マネージドサービスである Amazon Bedrock の使い方について、具体的なユースケースやコードを示して解説した内容でした。
以下の情報を参照すると Amazon Bedrock について、より理解が深まります。
- 生成 AI アプリケーション開発をもっと身近に、簡単に !Amazon Bedrock をグラレコで解説
- Amazon Bedrock Overview 【Amazon Bedrock Series #01】【AWS Black Belt】
- Amazon Bedrock モデル推論 a.準備編 【Amazon Bedrock Series #02a】【AWS Black Belt】
- Amazon Bedrock モデル推論 b.実践編 【Amazon Bedrock Series #02b】【AWS Black Belt】
- Amazon Bedrock Agents 自律型 AI の実現に向けて: 検討編 【Amazon Bedrock Series #04a】【AWS Black Belt】
- AmazonBedrock BlackBelt Agents 自律型 AI の実現に向けて: 動作理解編 【Amazon Bedrock Series #04b】【AWS Black Belt】
- Amazon Bedrock Agents 自律型 AI の実現に向けて: 開発・運用編 【Amazon Bedrock Series #04c】【AWS Black Belt】
- Amazon Bedrock Knowledge Bases【AWS Black Belt】
さらに、実際に手を動かすハンズオンを実施すると、理解が深まります。
-
builders.flash
- Amazon Bedrock でチャットボットを作ってみた!
- Amazon Bedrock を利用して、画像生成アプリケーションを開発してみた!
- Amazon Bedrock で企業会計基準チャットボットを作ってみた !
- Amazon Bedrock と Claude でインスタ投稿自動化に挑戦
- 生成 AI を活用したニュース 3 行要約を配信するシステムをマネージドに作成する
- 生成 AI を用いたヘルプソリューションを作成する
- AWS IoT と 生成 AI を使って自宅の消費電力を測定・予測してみよう
- Dify と Amazon Bedrock を使って、簡単にセキュリティオペレーション自動化
- Amazon Bedrock を活用した Web ページ作成をアシストする仕組みの構築
- JP Contents Hub
Discussion