なぜソフトウェアをCleanにする必要があるのか?
(このテーマで社内エンジニア向けに発表したいのでまとめる)
弊社のバックエンドはClean Architecture をベースとしたアーキテクチャでGo言語を使って実装しています。
ではなぜこの様なソフトウェアアーキテクチャが必要なのでしょうか?
ソフトウェアをCleanにするとはどういうことなのでしょうか?
自分が学び、実践するなかでの現時点の理解をアウトプットします。
Clean Architecture はRobert C. Martin(Uncle Bob)が提唱したアーキテクチャです。
以下では彼のブログ、書籍を参考にしつつ自分なりに噛み砕いて概要を説明します。
詳細を知りたい場合は参考元を読んでみてください。
Clean Architecture 概要
下図は Claen Architecture の象徴的な図[1]です。同心円状に4つのレイヤーに分けられ、円の内側は外側に依存しないというアーキテクチャの方針を表しています。
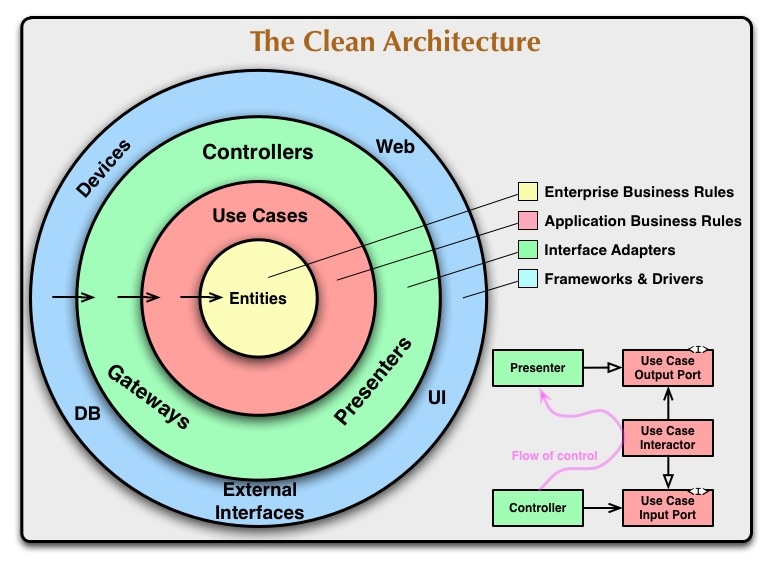
では何を内側・外側に実装するのかというと、内側にはプロダクトにおいて最も重要なものを、外側には比較的そうでないものを実装します。プロダクトにおいて最も重要なものは、ビジネスを成功させることです。そのため現実世界のビジネスの中で決められたルールを内側に実装します。このようなルールに基づいて処理を行う仕組みのことをビジネスロジックと呼び、例えば銀行口座は振込のために「口座AからはN円減らし、口座Bに同額のN円を足す」というビジネスロジックを提供します。このようなルールはアプリケーションとして実装せずとも必要なビジネス上のルールです。
外側に実装するのはアプリケーションとして成立させるために必要な仕様を実装します。例えばHTTPリクエストで処理を呼び出す、PostgreSQLに保存する、ORMのようなフレームワークを使うというのはアプリケーションとして実装する時に登場する事柄です。これらは現実世界のビジネスの中で決められたルールではなく、代替・交換可能であるため重要ではないと位置づけられます。
このようなアーキテクチャは変更容易性を担保し、柔軟で保守しやすい開発を可能にします。UI・DB・フレームワークは円の外側に実装されていて、その変更が内側の実装には影響を与えません。内側の実装は外側に対して独立しているためテストが容易です。外側の要素は交換可能であり、テストに際してモック化することも可能です。
概念は分かったものの、どのような時に起こる課題を解決してくれるのでしょうか?抽象的であまりピンとこないかもしれません。具体化するためにCleanではない場合に何が起こるのか見ていきましょう。そのためにまずは Clean Architecture とは違った方針によって実装されるケースについて知ることが近道です。その例としてRailsを取り上げます。
まずはRailsの概要としてRailsガイドで解説されているものを以下で説明します。
Rails はMVCの方針で実装
RailsはMVC(Model-View-Controller)というアーキテクチャパターンに従う規約になっています。下図はMVCの概念図[1]です。モデル、ビュー、コントローラの3つの要素で構成されます。以下ではこれらの構成要素をRailsでどのように実装するのか見ていきます。
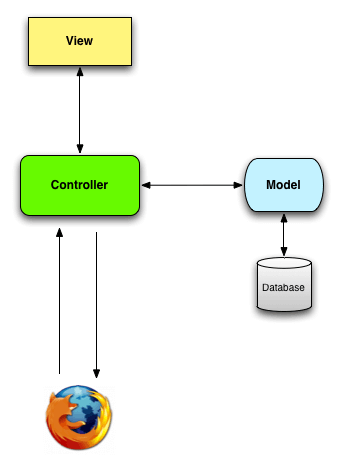
まずはモデルです。モデルは定義するデータ構造をそのままDB上のテーブルと同じ構造で扱います。
以下のようなコマンドでArticleモデル(title, bodyを持つ)を生成すると、同時にArticleテーブル(title, bodyを持つ)を作成するためのマイグレーションファイルが生成されます。
$ bin/rails generate model Article title:string body:text
このモデルに対してビジネスロジックを実装していきます。
class Article < ApplicationRecord
has_many :comments
validates :title, presence: true
validates :body, presence: true, length: { minimum: 10 }
VALID_STATUSES = ['public', 'private', 'archived']
validates :status, inclusion: { in: VALID_STATUSES }
def archived?
status == 'archived'
end
end
DBとのやりとりもこのモデルの機能に含まれています。以下のように新しいモデルインスタンスを生成し、DBに対してInsertができます。
irb> article = Article.new(title: "Hello Rails", body: "I am on Rails!")
irb> article.save
(0.1ms) begin transaction
Article Create (0.4ms) INSERT INTO "articles" ("title", "body", "created_at", "updated_at") VALUES (?, ?, ?, ?) [["title", "Hello Rails"], ["body", "I am on Rails!"], ["created_at", "2020-01-18 23:47:30.734416"], ["updated_at", "2020-01-18 23:47:30.734416"]]
(0.9ms) commit transaction
=> true
次にビューです。ビューはデータを好みの書式で表示します。HTMLで表示したい場合は以下のようになります。このときモデル(@articles)を利用することも出来ます。
<h1>Articles</h1>
<ul>
<% @articles.each do |article| %>
<li>
<%= article.title %>
</li>
<% end %>
</ul>
最後にコントローラです。コントローラーはリクエストされたユーザーの入力を受け取ってそれに応じたモデルの操作を実行します。以下ではArticleモデルに対して全レコードを取得して @articles に代入しています。この処理の後にビューが呼び出され、上記のように @articles が利用できます。
class ArticlesController < ApplicationController
def index
@articles = Article.all
end
end
このようなRailsに対してClean Architectureの方針との比較を見ていくと、RailsのモデルはDBに依存していることが大きな違いであることが分かります。ではClean Architectureではなぜこの依存を避けているのでしょうか?
DBへの依存によるデメリット
ここで"RailsのモデルがDBに依存している"というのは、具体的にはモデルとテーブルが1対1構造になっていることを指します(上記のモデル生成コマンド参照)。このような構造は、初期の開発では問題にはなりません。その問題が顕在化するのはアプリケーションがリリースされた後、機能追加が繰り返された後です。
よく目にするケースが、Userモデルの肥大化です。ユーザー本人が持つ情報は多岐に渡ります。姓名、生年月日、電話番号、住所、出身大学、自己紹介、プロフィール画像、会員ステータス、ロール、サブスクリプションプラン、などなど挙げればきりがないほどです。開発初期において、これらを上手くモデリングできるでしょうか?時にはリリースを急いで、色々なものをUserモデルに追加してしまうこともあるかもしれません。また予めUserDetailモデルとしてプロダクトのコアとなる機能には関係のない情報を分けたとします。それは将来もずっとそのような条件を満たしますか?
肥大化に含まれる意味合いはそれだけではありません。モデルには ビジネスロジック が実装されます。これらはモデル自身の持つ情報に対して実装されるため、その情報の量が多いほど実装は肥大化します。このような問題はファットモデルとして有名です。
この課題はClean Architectureであっても直面します。ただしClean Architectureでは比較的容易に解消が可能です。以下で具体例を示します。
Clean Architecture でのファットモデル解消法
以下はUserモデルの例です。本来解決したい課題はファットモデルの解消ですが、ここでは説明のために簡単なモデルとして定義します。
type User struct {
ID int // ユーザーID
FirstName string // 名前
LastName string // 苗字
Email string // メールアドレス
PhoneNumber string // 電話番号
}
Userモデルが肥大化したため、責務の分割を行います。
type User struct {
ID int // ユーザーID
FirstName string // 名前
LastName string // 苗字
}
type UserContact struct {
UserID int // ユーザーID
Email string // メールアドレス
PhoneNumber string // 電話番号
}
このような分割は、仮にRailsでやろうとするとテーブル自体を分割する必要があります。よほど上手くやらない限り、テーブルマイグレーションのためにプロダクトをメンテナンスに入れて作業する必要があるでしょう。
Clean Architectureではどうでしょう?モデルはRepositoryというDBとのデータアクセスを担うレイヤーで構築されます。
func (r *UserRepository) GetUser(id int) (*models.User, error) {
query := "SELECT id, name, email, password FROM users WHERE id = ?"
row := r.DB.QueryRow(query, id)
var user models.User
err := row.Scan(&user.ID, &user.Name, &user.Email, &user.Password)
if err == sql.ErrNoRows {
return nil, nil
} else if err != nil {
return nil, fmt.Errorf("could not find user: %v", err)
}
return &user, nil
}