はじめに
株式会社ispecのSREの丸山です。本記事では、サービスのリリースに向けて負荷テストを実施して,得た知見について紹介します。
ispecは、スタートアップのゼロイチ開発に特化した受託事業を行なっています。支援させていただいているサービスの中には、リリース初期から広告やキャンペーン等で多くのアクセスが見込まれる場合があります。その際、せっかくのユーザー獲得のチャンスを逃してしまう可能性があり、ビジネス的にクリティカルな問題となりかねません。負荷テストをリリース前に実施することで、QAでは見抜けないボトルネックを発見することができます。
また、受託事業という業態のため、クライアント様にシステムを完全にお渡しすることになったことも考慮し、将来のアクセス増加も考えた場合に現行のシステムが
- どれくらいの負荷に耐えられる構成なのか
- アクセスの増加した場合にインフラコストがどのように増加するか
を事前に報告したいことがあります。今回はこれらを評価するためにも、負荷テストを実施しました。
負荷テストの計画
負荷テストの目的
負荷テストの目的には、一般的に以下のようなものがあります。
(出典:Amazon Web Services負荷試験入門 ――クラウドの性能の引き出し方がわかる Software Design plusシリーズ)
- 各種ユースケースの応答性能を推測する
- 高負荷時の性能改善を行う
- 目的の性能を提供することができるハードウェアをあらかじめ選定する
- システムがスケール性を持つことを確認する
- システムのスケール特性を把握する
特に今回のテストでは、
- 実装や仕様上ボトルネックになるエンポイントの発見とその改善
- ECSやRDSのスケール性の確認・スケール特性の把握
- 想定負荷でシステムが耐えられることの確認
- 想定負荷の時のシステムリソースとその料金コストの見積もり
を調べることをスコープとして、負荷テストを行いました。
ツールの選定
Apache Bench, JMeter, Locust などがありますが
- シナリオテストができる
- 比較的使えるエンジニアが多いJavaScriptで書ける
という理由から、k6を選定しました。
k6は、Grafana Labsが開発している負荷テストツールです。
Open Sourceとして提供されていますが、SaaSとして提供されているk6 Cloudもあります。k6 Cloudは、テスト結果のダッシュボードやテストの実行環境が提供されるため、手っ取り早くテストを実施するのには非常に優れています。しかし、Teamプランで$424/月と少々コスト面で厳しいことと、仮想ユーザ数やテストの実行回数の上限などのリソースの上限があることから、Open Sourceを活用して、自前でテスト基盤を構築することにしました。
テスト基盤
実行基盤
社内システム用のEKSクラスターが元々立っていて、他のプロジェクトで負荷テストをする場合でも同じ環境を使いまわせるので、テスト基盤には、EKSを採用しました。
また、k6には、k6-operatorというk8sのカスタムリソースがOpen Sourceとして公開されています。テストを複数のJobに分割し、実行・管理してくれるリソースです。これにより、簡単にk8s上で簡単にテストを実行することができます。
ダッシュボード
負荷テストでは、様々なメトリクスを監視して、テストの結果を分析するためのダッシュボードが必要です。今回は、Grafana + influxdbを採用しました。k6が計測するリクエストの回数や仮想ユーザの数、レスポンスの時間などのメトリクスや、テスト対象のECSのCPU稼働率やRDSのコネクション数などのメトリクスを一覧で表示できるようにします。
k6が計測するメトリクスは、各k6 jobがinfluxdbへ送信し、テスト対象のメトリクスはCloudWatch Metricsを連携して取得します。
実行基盤とテスト対象
負荷テストの基盤は、テスト対象と同一VPC上ではなく、社内の共通EKS基盤上に構築しました。
前述した通り、他のプロジェクトで負荷テストをする際でも、同じ環境を使いまわせて効率的だからです。
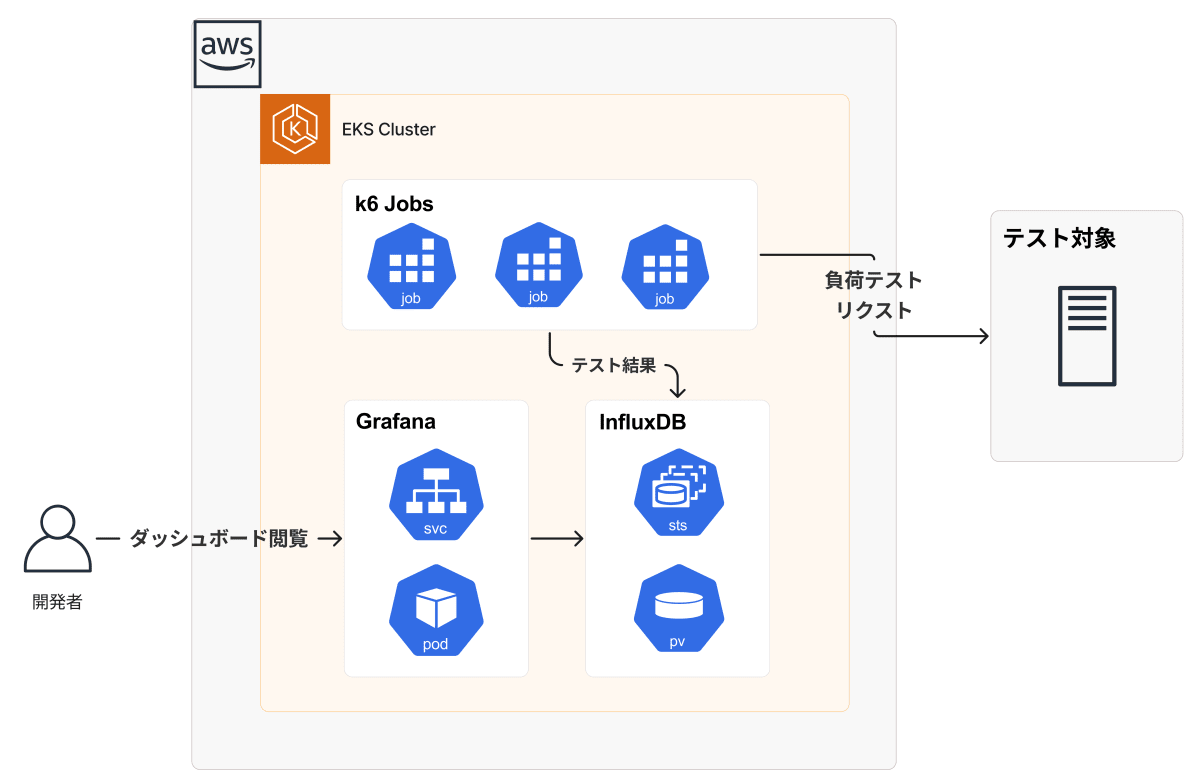
負荷テストの概要
負荷テストの流れ
負荷テストの大まかな流れは、次の通りです。
- 負荷試験の目標の設定
- シナリオ構成の作成
- 攻撃対象サーバーの準備
- インフラやアプリケーショーンのビルド
- ダミーデータの作成
- 負荷テストの実施
- レポートの作成
実施する負荷テスト
- 参照系の性能テスト:参照系のエンドポイントに対して負荷をかける
- 更新系の性能テスト:更新系のエンドポイントに対して負荷をかける
- シナリオテスト:一般的なユーザのシナリオに従って、負荷をかける
- スケールアップ・アウトテスト:ECSにオートスケールを設定し、負荷をかけ、スケール性の確認・スケール特性を把握する
- 限界性能テスト:負荷を増加させ、システムの限界性能を計測することと、高負荷の環境で起きる不具合や挙動を確認することを目的とします。
を実施しました。
システムのボトルネックを見つけやすくするために、参照系・更新系の性能テスト、シナリオテストでは、ECSのタスク数を1に固定します。
スケールアップ・アウトテストと限界性能テストでは、ECSにオートスケール設定をして、テストを行います。
負荷テストの目標設定
負荷テストの目的の1つに、想定負荷に耐えられるかを確認するというものがありました。
今回のテストでは、
- ユーザ数10万人、デイリーユーザ数1万人
- 1日のうち80%が2時間に集中する
- 1日で1ユーザあたり、4シナリオを実行する
という仮定を設定し、想定負荷(スループット)を
10,000 * 0.8 * 4 /2h = 16,000/h = 4.44シナリオ/s
としました。
致命的にUXを損ねるレイテンシとして、0.1sを目標値とし、ユーザ10万人についてのダミーデータを作成し、テストで使用するDBに追加しました。
ボトルネックの発見と改善
仕様の欠陥によるボトルネックの発見
参照系のエンドポイントで、レスポンスサイズが膨大になり、OOMでバックエンドが落ちることがありました。バックエンド側で対応できる範囲ではないので、開発担当者と相談し、システムの仕様から改善することができました。
MAUを想定してシミュレーション実験行い、致命的なボトルネックとなるMAUを定量的に示せたため、説得力を持ってテコ入れを提案できました。
RDSリソースの限界
現状、RDSのスケーリングが設定できていないため、性能限界テストを実施すると、ECSタスクだけが水平スケールし、必然的にRDSがボトルネックになります。
それがどれくらいの想定ユーザで、限界値を迎えるのかを測定し、1台で運用する場合のDBインスタンスのスペックを決定することができました。しかし、今後のスケーリングやコスト面で考えると、リーダーインスタンスを立てるスケーリング戦略の方が賢いことも発見できました。
本番とのシステム差異による落とし穴
対象システムが外部サービスへのアクセスをする仕様になっていましたが、事情により開発用のアカウントを準備することができず、スタブを用いてテストを行いました。そのため、外部APIを扱う処理がボトルネックとなっていたことに気が付きませんでした。
このボトルネックは、負荷テストではなく検証環境でのQAテストで指摘され、Redisを使ってパフォーマンスが改善されました。
また、外部サービスを扱う途中で使われるDBアクセス処理の中で、不必要にDBとのコネクションが張られる実装になっており、これに負荷テスト段階で気がつくことができませんでした。
このようにスコープ外のボトルネックについて、
- チーム内で事前に共有し、異変があったときにすぐに当たりが付けられるようにすること
- 負荷テストで計測できる環境をちゃんと準備すること
が必要だと感じました。
負荷テストの計画
レイテンシの目標や想定ユースケース、シナリオについて、しっかりと準備する必要があると感じました。
今回の想定ユースケースは、通常時の1日で最もアクセスが集中する時間帯のみでした。例えば、キャンペーン開始時やプレスリリース時のスパイク等が考慮されていませんでした。これらについて、エンジニア内外と積極的にコミュニケーションを取りながら、練っていきたいところです。
おわりに
負荷テストを実施してみて、ECSタスクやRDSのスペックの限界値の限界値を見つけることだけでなく、実装やアーキテクチャ、仕様の問題などを定量的に評価することができ、ボトルネックの改善につなげることができました。
今後の課題としては
- ボトルネックをより詳細に発見するために pprofなどのプログラム内部のプロファイルを計測をする
- CIに負荷テストを導入し、ボトルネックを継続的に見つけていく
- 外部サービスを含めた負荷試験を行う
等を行っていきたいと考えています。
ispecでは更なる事業拡大を見据え、エンジニア職にて新しいメンバーを募集しています。
採用サイトでは各求人の詳細だけでなく、ispecで大切にしている価値観や、メンバーの紹介記事も掲載しております
- 技術へのこだわりやプロダクト愛を活かして働きたい
- フルリモート、フルフレックス下で最大限のバリューを発揮したい
- 心理的安全性の高い環境の中、チームで成果をあげてみたい
そんな思いを持った方がいらっしゃいましたら、ぜひ一度ご応募ください!


Discussion