はじめに
はじめまして、株式会社ispec バックエンドエンジニアの太田です。
今回は、ispecにおけるGraphQLの導入背景とDataLoader実装のアプローチについて紹介します。
GraphQL導入背景
GraphQL導入以前
ispecでAPIを開発する際、GraphQL導入以前はRESTful APIが主流でした。
RESTful APIを使用すると、通常ひとつの画面を表示するために複数のエンドポイントにアクセスする必要があります。
GET /users ... Userの一覧
GET /users/1 ... Userの情報
GET /users/1/tweets ... UserのIDが1のTweet
RESTful APIとしては正しいアプローチですが、ユースケースによっては オーバーフェッチ(不要なデータの取りすぎ) が発生してしまいます。
反対にRESTful思想に近づけず、ユースケースやUI毎にエンドポイントを用意をすると、フロントエンドの変更に応じてAPIを変更する必要があり、かえって保守性が低下してしまいます。
GraphQLによる解決方法
GraphQLを導入することで、/graphqlのような単一のエンドポイントに対してフロント側が欲しいデータを指定すると、その分だけかえってくるようなAPI設計ができます。
query users {
users {
id
name
tweets {
id
text
},
}
}
また、「欲しいデータとして何を指定できるか」を共有するためにGraphQLのスキーマを利用することで、必要なデータをクライアント側が明示的に要求できます。
schema {
query: Query
mutation: Mutation
}
type Query {
user(id: ID): User!
users: [User!]
}
type User {
id: ID!
name: String!
}
...
これにより、オーバーフェッチがなくなり、バックエンドAPIのパフォーマンスも向上します。
GraphQLサーバーでのN+1問題とは
GraphQLのQueryは、取得したいデータのノードを辿って必要なデータを一度に取得できます。
一方でノードが多く、深くなればなるほど、データソースへのアクセス回数が増加してしまいます。
例えば
// 本と著者を10件取得するクエリ
{
books(first: 10) {
title
author {
name
}
}
}
-- 最初にbookを10件取得したあと
SELECT * FROM books limit 10;
-- booksを1件取得する毎にauthorsレコードを1件ずつ取得する
SELECT * FROM authors WHERE id = ?; # ? = 1
SELECT * FROM authors WHERE id = ?; # ? = 2
SELECT * FROM authors WHERE id = ?; # ? = 3
SELECT * FROM authors WHERE id = ?; # ? = 4
SELECT * FROM authors WHERE id = ?; # ? = 5
SELECT * FROM authors WHERE id = ?; # ? = 6
SELECT * FROM authors WHERE id = ?; # ? = 7
SELECT * FROM authors WHERE id = ?; # ? = 8
SELECT * FROM authors WHERE id = ?; # ? = 9
SELECT * FROM authors WHERE id = ?; # ? = 10
-- 一括で取ってきてほしい
SELECT * FROM authors WHERE id in (1,2,3,4,5...);
しかし、GraphQLの場合はどのようなノードの組み合わせでクエリがリクエストされるか分かりません。
全て 先読み込み(Eager Loading) してしまうと、要求されていないノードのデータまで取得することになり、無駄なクエリが走ってしまいます。
N+1問題を解決するDataLoaderとは
そこで登場するのがDataLoader。
遅延読み込み(Lazy Loading) で実際に使うデータだけをロードします。
具体的には、
「一定時間待って、その間に実行されたデータ取得リクエストをバッチ化する」
というアプローチです。
後述するライブラリでは、デフォルトの設定で16ms待機するように設定されています。
リクエストが来てすぐにクエリを作成する場合、DBアクセスが増加してしまいます。
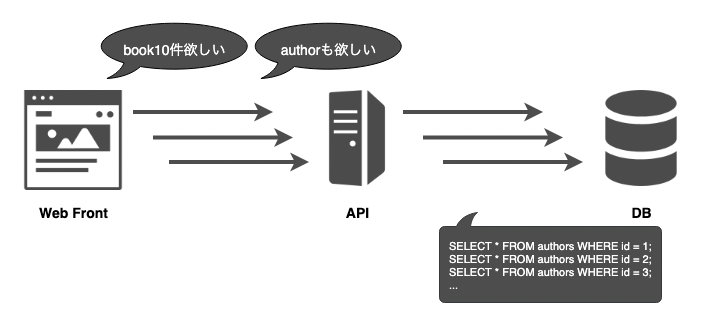
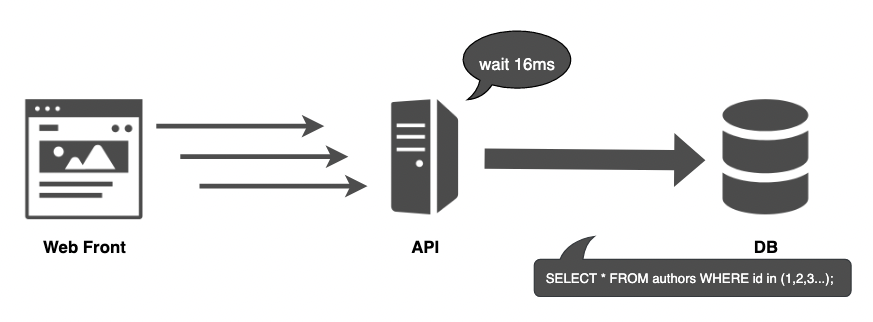
一方、リクエストを16ms待ってからクエリを作成する場合は、クエリをまとめられる為、DBアクセスを減らすことができます。
【コラム】先読み込み vs 遅延読み込み
- 先読み込み
- ORMがサポートしていることが多い為、実装が簡単。
- データを使う場所と、データを読み込む場所がコード上で離れる傾向があるため、
開発をしていくうちに不要なデータを先読みし続けたり、逆に適切に先読みできておらず N+1 SQL が発生したりする。
- 遅延読み込み
- 実際に使うデータだけをロードすることが保証される。
- 必要なリソースの情報をためる特別な機構が必要なので実装が複雑。
- 待機時間が大きくなるとバッチ化できる範囲が広がるが、その分レスポンスタイムが遅くなる。
DataLoaderの実装方法
ispecではモノレポのテンプレートプロジェクトmonorepoをOSSとして公開し、開発を行っています。
今回は、ispecで標準となっているmonorepoを基にした、Dataloaderの実装方法を簡単に解説します。
Dataloaderライブラリはアーキテクチャの柔軟性などを考慮し、ミニマルなAPIを提供しているgraph-gophers/dataloader を採用しています。
-
バッチ関数のセットアップ
指定したKeyに対するデータを取得し、非同期処理を行う関数としてバッチ関数を用意します。
BatchFuncに準拠した関数を用意する必要があります。
graph-gophers/dataloaderから一部抜粋graph-gophers/dataloader/dataloader.gotype BatchFunc func(context.Context, Keys) []*Resultmonorepoでは以下のように実装しています。
引数のkeysは、リクエストされるレコードのIDがstring型の配列として渡されることを想定しています。
ヘルパー関数extractIDsFromKeysを用いて、keysからレコードIDを取得します。
IDを元にDBからレコードを取得し、解決された値をリストに追加して返却します。func batchLoadAuthor(ctx context.Context, keys dataloader.Keys) []*dataloader.Result { // 指定したkeysからレコードのIDを抽出 ids := extractIDsFromKeys(keys) // authorsテーブルから引数に指定したIDのレコードを配列で取得 as := &model.Authors{} err := as.List(ids) // ライブラリに準拠したレスポンスに変換 rs := make([]*dataloader.Result, len(*as)) for i := range *as { rs[i] = &dataloader.Result{Data: (*as)[i], Error: err} } return rs }func extractIDsFromKeys(keys dataloader.Keys) []int64 { ids := make([]int64, len(keys)) for i := range keys { id, err := strconv.Atoi(keys[i].String()) if err == nil { ids[i] = int64(id) } } return ids } -
ContextKeyとバッチ関数を登録
ContextKeyと該当するバッチ関数をmapとして登録しておきます。
こうすることでリクエストが来た際にContextKeyから該当するバッチ関数を呼び出すことができます。type key string const ( authorKey = "author" ) var ( LookUpTable = map[key]dataloader.BatchFunc{ authorKey: batchLoadAuthor, } )func AttatchDataLoader(next http.Handler) http.Handler { fn := func(w http.ResponseWriter, r *http.Request) { ctx := r.Context() for k, f := range loader.LookUpTable { ctx = context.WithValue(ctx, k, dataloader.NewBatchedLoader(f)) } next.ServeHTTP(w, r.WithContext(ctx)) } return http.HandlerFunc(fn) } -
インメモリキャッシュを持つLoaderの実装
Loadメソッドがあちこちで呼ばれてKeyが集まった後(16ms待った後)にSQLで問い合わせを行います。func LoadAuthor(ctx context.Context, id int64) (*model.Author, error) { // ここでContextKeyを元に該当するバッチ関数を取得する ldr, err := getLoader(ctx, authorKey) if err != nil { return nil, err } // thunkが呼び出されると値が解決されるまでブロックする thunk := ldr.Load(ctx, dataloader.StringKey(fmt.Sprintf("%d", id))) data, err := thunk() if err != nil { return nil, err } m, ok := data.(model.Author) if !ok { return nil, ErrLoaderResultTyping } return &m, nil }func getLoader(ctx context.Context, k key) (*dataloader.Loader, error) { ldr, ok := ctx.Value(k).(*dataloader.Loader) if !ok { return nil, fmt.Errorf("unable to find %s loader on the request context", k) } return ldr, nil } -
メソッドの呼び出し時のKey を溜め込むResolverの実装
Authorメソッドを実装したBook Resolverを返却すると、schemaに定義したレスポンスを得られます。type Book struct { book model.Book } func (b Book) Author(ctx context.Context) (*Author, error) { a, err := loader.LoadAuthor(ctx, b.AuthorID) ... }
おわりに
今回は、ispecにおけるGraphQLの導入背景とDataLoader実装のアプローチについて紹介しました。いかがでしたでしょうか。
ispecでは、更なるProductivityの改善に向けて一緒に研究、開発してくれる新しいメンバーを募集しています!
採用サイトでは各求人の詳細だけでなく、ispecで大切にしている価値観や、メンバーの紹介記事も掲載しております。
- 技術へのこだわりやプロダクト愛を活かして働きたい」
- フルリモート、フルフレックス下で最大限のバリューを発揮したい」
- 心理的安全性の高い環境の中、チームで成果をあげてみたい」
そんな思いを持った方がいらっしゃいましたら、ぜひ一度ご応募ください。

参考

Discussion