Investigating an Overfitting and Degeneration Phenomenon in Self-Supervised Multi-Pitch Estimation
ISMIR2025のInvestigating an Overfitting and Degeneration Phenomenon in Self-Supervised Multi-Pitch Estimationをざっくり読みました。
概要
Multi Pitch Estimation (MPE) の従来手法の多くはsupervisedである。しかし、MPEではアノテーション付きデータを収集するのが困難であるという課題がある。self-supervisedな手法も存在するが、これらの手法は依然としてsupervisedな手法に劣る。
そこで、supervisedな従来手法と同様のモデルに、ピッチ不変およびピッチ同変な特性に関するself-supervisedなlossを追加した。実験の結果、1, 2時間のデータしか訓練に使っていないにもかかわらず、ほとんどのケースで従来手法の性能を上回った。
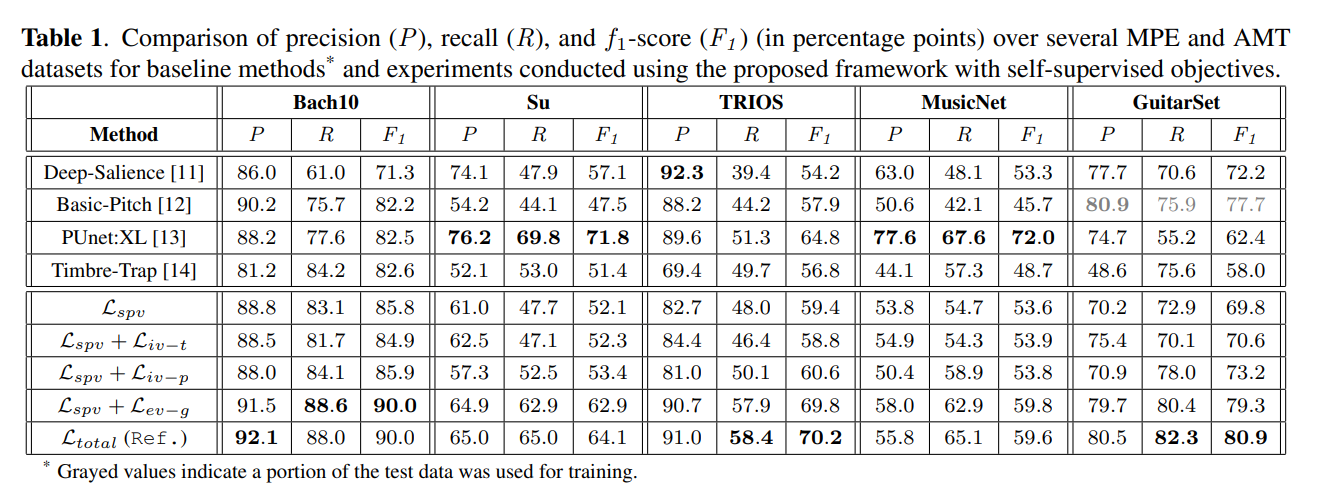
上段:従来手法、下段:提案手法。従来のsupervised loss
一方、訓練データとは異なるラベルなしのデータを各バッチに少しだけ追加して、そのデータに関してはself-supervisedなlossのみを計算するようにして学習を進めたところ、元の訓練データに対しては性能が維持されたが、ほかの評価用データセットに対しては性能が崩壊した。そこで、入力・出力特徴量のエネルギーに注目した別のself-supervised lossを追加したところ、崩壊はしなくなったが依然として性能は低下した。
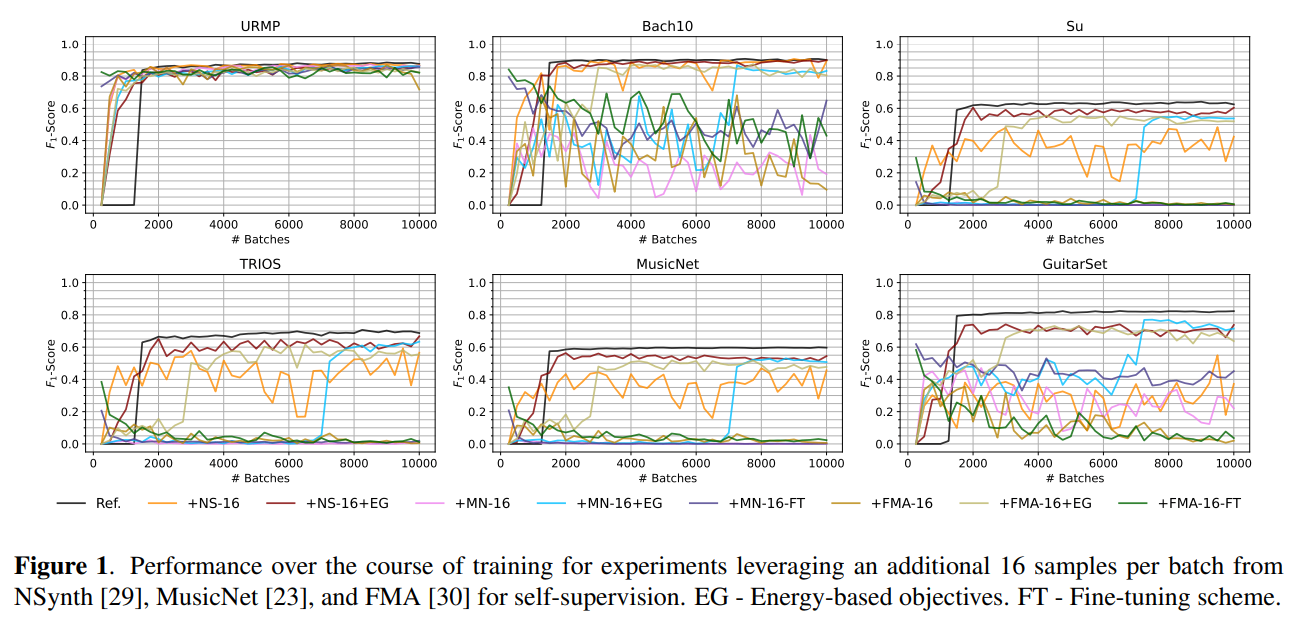
性能が崩壊している様子。黒線が追加前、その他の線が追加後
追加実験の結果、ラベルなしデータを追加するほど性能が低下することが分かった。また、性能の低下は、教師あり学習に使うデータとラベルなしデータの分布の違いには起因しないことが分かった。まとめると、無音を予測するなどの自明な解をラベルなしデータが誘発してしまうことが、根本的な問題であると考えられる。予測結果に何らかの意味のある内容が存在することを強制するような、新しい目的関数が必要かもしれない。
少しややこしいところの整理
| supervised lossの計算に用いたデータ分布(データセット)とself-supervised lossの計算に用いたデータ分布が一致しているか | あるイテレーションにおいて、supervised lossの計算に用いたデータとself-supervised lossの計算に用いたデータが同期しているか(同じデータを用いているか) | |
|---|---|---|
|
|
✅ | ✅ |
| 性能が崩壊したときのモデル(Section 3.4で述べられている実験。Figure 1の黒線以外) | ❌ | ❌ |
| 性能崩壊はしなくなったが依然として性能が低いモデル(Section 4.2で述べられている実験) | ✅ | ❌ |
多分こうだと思います。
感想
- 結局、教師あり学習に使ったデータに対応するデータをself-supervised lossの計算に用いる必要があるので、MPEにおけるデータ不足は解決していなさそう。
- 教師あり学習に使うデータとラベルなしデータの分布が同じであっても性能が低下していることから、self-supervised lossが自明な解へ引き寄せる可能性があったとしても、supervised lossがその動きを相殺し、モデルを正しい方向へ導いていたと考えられる。