Emergent musical properties of a transformer under contrastive self-supervised learning
ISMIR 2025のEmergent musical properties of a transformer under contrastive self-supervised learningをそこそこ読みました。
概要
本研究は、汎用的な音楽表現学習に取り組む。対照学習を用いた従来手法は、global task(曲全体に対する予測タスク)に有用な表現しか得られなかった。local task(曲の一部に対する予測タスク)にも有用な表現を得るために、自己教師あり学習を用いた手法(SSL)が研究されてきたが、ハイパーパラメータの調整などが学習を複雑化している。
本研究では、local taskに有用な表現も得られる対照学習手法を提案。音入力に対応したViTに対し、class token(出力特徴系列の最初のトークン)のみを用いたcontrastive loss(Equation 1)を用いてViTを学習。その後、freezeしたViTが出力したclass tokenやそれ以外のトークン(sequence tokens)を用いて、下流タスクを解く単純なMLPを学習(Figure 1)。
実験の結果、class tokenはglobalな表現を、sequence tokensは主にlocalな表現を獲得することが分かった(Table 1)。また、attentionが主に音の開始時刻(onset)に焦点を当てていることや(Figure 3, Table 2)、sequence tokensがハーモニーやリズムの特性を捉えていることが分かった(Figure 4)。
従来の音楽表現学習手法について
① 対照学習を使用した手法
- CLMR、MULE
- モデルアーキテクチャのせいで、系列全体を総括した大域的な表現しか得られない
- global taskには有用
- global task: 曲全体に対する予測タスク。調推定など
- cf. local task: 曲の一部に対する予測タスク。和音推定など
- モデルアーキテクチャのせいで、系列全体を総括した大域的な表現しか得られない
- 他にも様々な汎用的なSSLが開発されたが、いずれもglobal taskに対する評価しかしていない
- 汎用的なSSLはlocal taskには不適切で、masked modelingなどのSSLが必要だと広く信じられているらしい
② Generative modeling / Masked modelingを用いた(フレームレベルの)手法
- Jukebox, Music2Latent / MERT, M2D, MusicFM
- global task, local taskの両方に有用だが…
- アーキテクチャが巨大だし、様々な学習技法に依存していて複雑
背景
①から②に研究がシフトしつつあるっぽい(前者は2021-2022, 後者は2023-2024辺りの研究)
「①の対照学習を使用した手法も、使い方を工夫すればまだまだ見込みがある。local taskにも有用」というのが本論文の主張
工夫:ViT-1Dに対照学習を使用
- ViT-1D:軽量のViTs(Vision Transformers)を、音を入力するためにちょっと改変したモデル
- Transformer系に対照学習を適用した手法を参考に…
- class tokenのみにcontrastive lossを適用
- class token: 特徴量系列の冒頭にあるトークン。特徴量系列の平均を用いて学習可能。入力系列全体の情報が総括されていることを期待
- contrastive loss: ここではnormalized temperature-scaled cross-entropy loss (NT-Xent)を指す
- attentionマップを見て局所的な特性を分析
- class tokenのみにcontrastive lossを適用
class tokenは時不変なのでglobalな下流タスクに、その後ろのsequence tokensは時同変なのでlocalな下流タスクに有用であることを示す
また、attentionマップに加えて、自己相関行列も分析
提案手法に関する詳細
提案手法

ViT-1Dと下流タスクのMLPは別で学習
NT-Xent
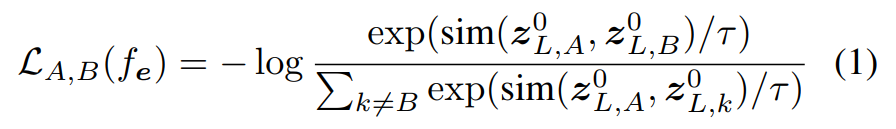
よくあるcontrastive loss
local taskとして拍推定と和音推定を採用
拍や和音の明示的なアライメントが無いので、sequence tokensに拍や和音に関するlocalな情報が入る保証はないのでは?
→本研究では、入ると主張(結果論?)
結果
下流タスクに対する性能評価
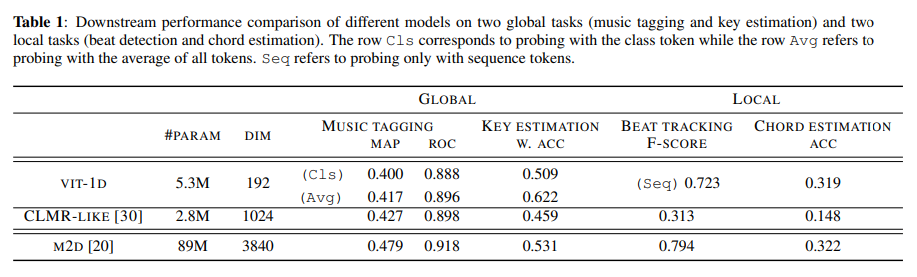
比較手法について
- CLMRはデータ拡張としてピッチシフトを用いて学習してるため、ピッチシフトに関して不変なモデルとなり、調に関するタスクに対する性能が低下
- →CLMRに似たアーキテクチャResNetを、データ拡張なしで対照学習したCLMR-likeをベースラインとした
- M2Dは参考記録
Table 1について
- sequence tokensがlocal taskでいい性能→sequence tokensが局所的・時間的表現を獲得か
- global taskでは全トークンの平均を用いた方がいい性能→class tokenがsequence tokensの全情報を捉えているわけではない。sequence tokensもglobal taskに有用
- class tokenだけをNT-Xentで学習しても、sequence tokensには有用な局所的情報が含まれた
後述のTable 3では、中間層の潜在特徴量も使って予測すると性能が上がることを示している
コメント
- Table 1について、CLMR-likeは最後に射影層を含むが提案手法は含まないとか、埋め込み次元が違うとか、様々なところが違うのであまり厳密な比較はできていない
ViT-1Dのattentionマップ
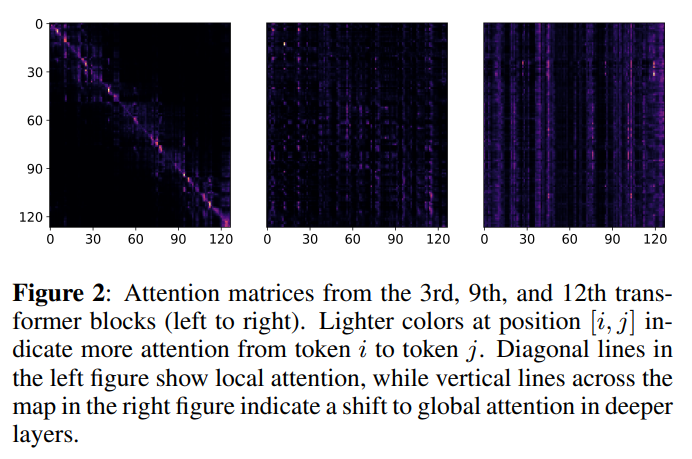
層が深くなるにつれて、attentionは局所的なものから大域的なものになった
これは文章埋め込みのTransformerでも同じらしい
ピアノデータセットを用いた時のattentionマップ(左)
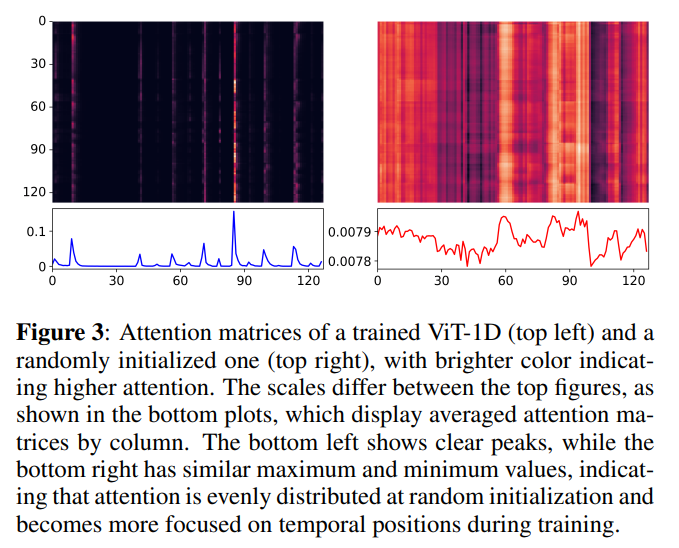
最初はランダムだけど(右)、学習が進むと(左)、時間的な位置にフォーカスしていく
Figure 3のグラフをピークピックしてonsetのf1を計測した結果

時間的位置、とりわけonsetに注目してることが分かった
sequence tokensの自己相関行列
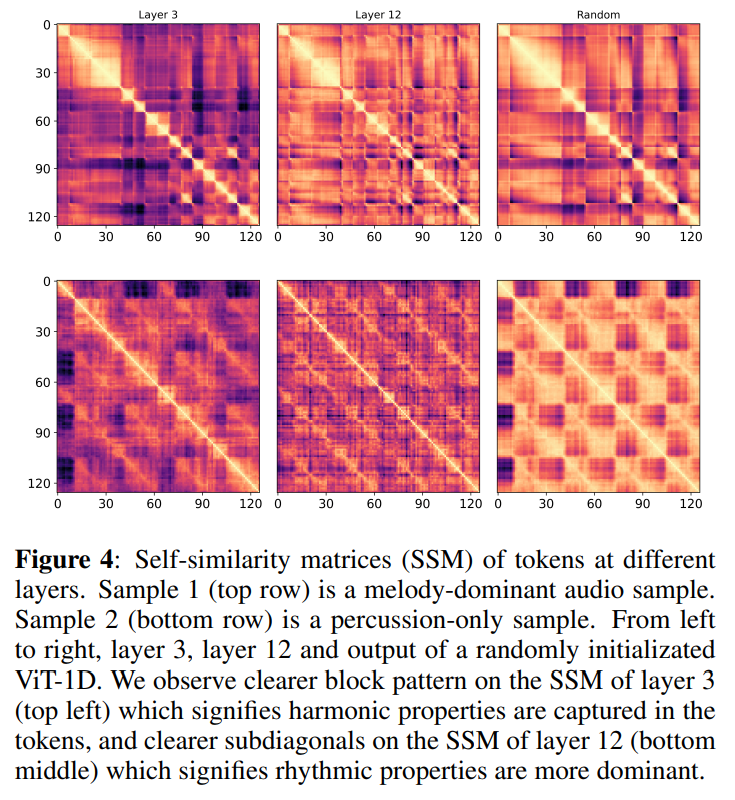
学習が進むにつれて、sequence tokensがハーモニーやリズムの特性を捉えている
感想
class tokenのみを用いたlossを使ってモデルを学習し、明示的なアライメントが無いにもかかわらず、sequence tokensが和音推定などのlocal taskに有用である示唆が得られたのは、非常に興味深い。特に、attentionがonsetに焦点を当てるという知見は、僕が取り組んでいる自動採譜の研究にも応用できそうだと感じた。
また、この論文では従来手法との厳密な比較実験はできていないものの、attentionマップや潜在特徴量の自己相関行列を用いて分析する手法は勉強になった。
- class tokenのみを用いたcontrastive lossで学習するとsequence tokensがlocal taskに有用になるのがやっぱり不思議。そこそこ高次元の潜在空間上での平均ベクトルに対照学習を適用すると、負例から引き離す作用が強力に作用するとか…?
- Table 1をよく見ると、提案手法は潜在特徴量の次元が比較的小さめ。次元が小さいと下流タスクの性能が良くならないイメージがあったが、結果を見るにそういうわけではなさそうなので意外。