Open1
SLAP: Siamese Language-Audio Pretraining without negative samples for Music Understanding
ISMIR 2025のSLAP: Siamese Language-Audio Pretraining without negative samples for Music Understandingをざっくり読みました。
概要
タスクはマルチモーダル(ここではテキストと音楽)な対照学習。
従来の対照学習は、負例を増やすためにバッチサイズを大きくする必要があり、メモリがたくさん必要。
提案手法は、2020年にGoogle DeepMindが提案したBootstrap Your Own Latent (BYOL)という自己教師あり学習の枠組みを利用することで、負例なしで高性能なモデルを実現。
自己教師あり学習でよくあるやり方は、あるデータ
対照学習では、負例を使うことでこれを回避。タスクは予測タスクから識別タスクに易化。
BYOLの要点は2つ。
- 予測器
P P(f(x)) f'(x') -
f' f
これで、なぜかcollapsing problemが回避できているらしい。
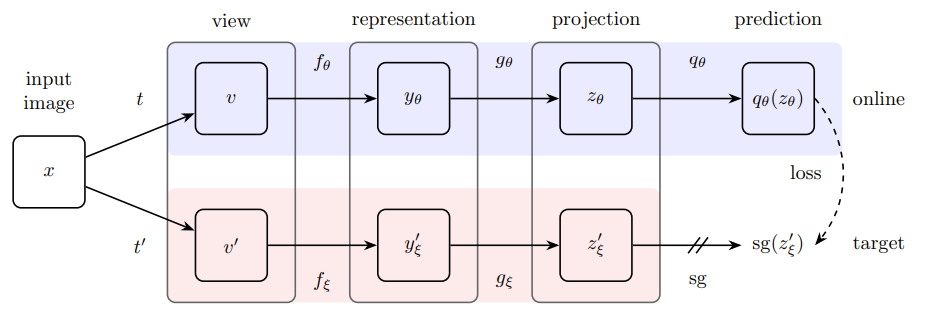
SLAPでは、この流れをそのままマルチモーダル化。
工夫点は、片方のモーダルでのembeddingと、もう片方のモーダルでの予測器の出力を近づける点。

感想
- なぜBYOLがcollapsing problemを回避できるんだろう?→2つのエンコーダが全く同じなら予測器は横流しするだけで済むが、2つのエンコーダが微妙に異なることで、予測器視点では全く未知のエンコーダが出力したembeddingに合わせなきゃとなるので、結果として予測器がちゃんと機能するようになるから、かも
- SLAPでは、BYOLにおける予測器に対し、別モーダルのエンコーダが出力したembeddingにも合わせることを要求している。より複雑なタスクになったのか、あるいはembeddingのデータ拡張として機能したのか分からないけど、今回はこれが上手くはまったんだと思う
- どうでもいいけど、SLAPのS(Siamese)は「シャム(タイの旧名)」「身体が繋がった双子」という意味があるらしい。ここでのsiameseは文脈的に後者の意味だと思うけど、語義を考えるとあんまり良い気分にはならないなと感じた
次に読みたい論文
- BYOL:2006.07733
- 自己教師あり学習の多くがこれを基に構築されているらしい:Cross-view Prediction Framework (Becker and Hinton (1992))
- 対照学習におけるcollapse problemの話