Pandas のコードを高速化する方法



はじめに
データサイエンスやAIで多用されるPandasライブラリですが,最適なデータの代入方法ができていますか?
この記事はRod Mulla氏のMake Your Pandas Code Lightning Fastを日本語でまとめたものになります.1次情報はリンクを参照してください. ハンズオンでの説明なので,実際にデータフレームを触りながら高速化について学ぶことが出来ます.
google colaboratoryにRod Mulla氏のテストコードをまとめましたので,ハンズオンで試したい方はご活用ください.
データ
pandasのデータフレームで['age', 'time_in_bed', 'pct_sleeping', 'favoraite_food', 'hate_food']のindexを持つデータを扱います.
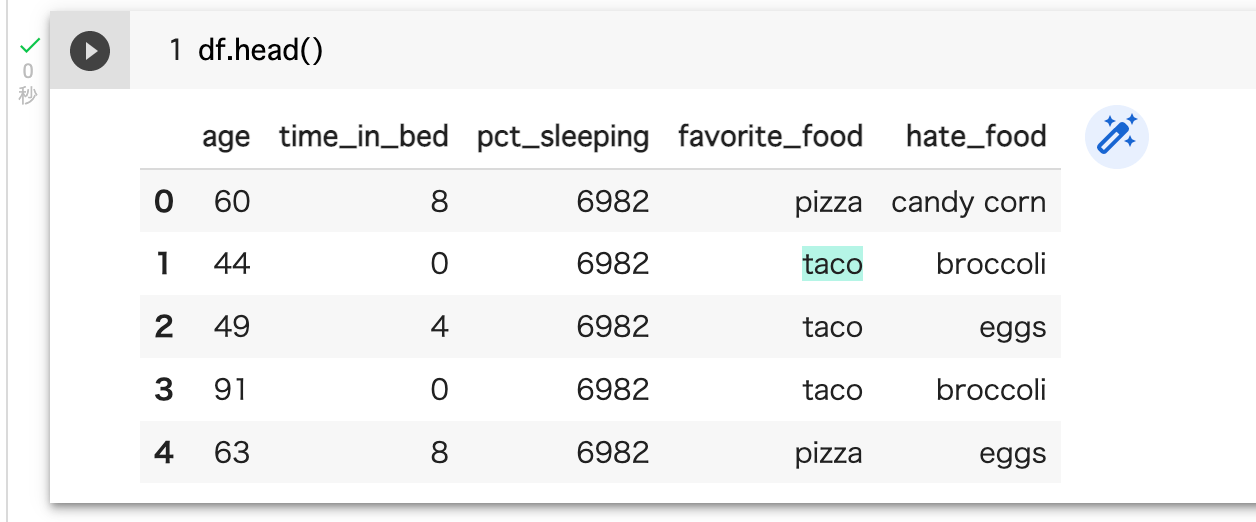
- age : 年齢
- time_in_bed : 睡眠時間(ベッドにいた時間)
- pct_sleeping : 実際に寝ていた時間の割合
- favorite_food : 好きな食べ物
- hate_food : 嫌いな食べ物
どこを高速化できる?
特徴量エンジニアリング(特徴量の抽出)やデータフレームに新たな情報の列を追記したいときどのように記述していますか? 以下にそのデータの代入手法について3つの例を示し,処理速度を比較します.
新たに条件にあったデータを追加する
今,以下の条件に合ったデータをrewardという要素名で新たに追加したいと考えています.
- 睡眠時間(
time_in_bed)が5時間より大きく,実際に寝ていた時間の割合(pct_sleeping)が0.5より大きい場合には,reward=favoraite_foodとする- 90歳以上の場合には
reward=favoraite_foodとする- それ以外は,
reward=hate_food
条件にあったデータを返す関数としては,以下のreward_calc関数が一例として考えられます.
def reward_calc(row):
if row['age'] >= 90:
return row['favorite_food']
if (row['time_in_bed'] > 5) & (row['pct_sleeping'] > 0.5):
return row['favorite_food']
return row['hate_food']
Level 1 - Loop
上記のreward_calc関数を用いてrewardの列にデータを繰り返し(Loop)挿入する方法です.
for index, row in df.iterrows():
df.loc[index, 'reward'] = reward_calc(row)
10000件のデータに対して操作を行なうと以下の時間で終了したことがわかります(%%timeit)
5.92 s ± 70.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Level 2 - Apply
apply関数を用いる方法です.引数に関数名と,追記する場所をaxisで明示します.
df['reward'] = df.apply(reward_calc, axis = 1)
10000件のデータに対して操作を行なうと以下の時間で終了したことがわかります(%%timeit)
172 ms ± 1.65 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
Level 3 - Vectorized
条件式を用いて True/falseに合わせ代入操作を直接行なう方法です. 具体的には以下のようなコードです. df.loc[ , ]の第1引数に条件式を記述し,第2引数に対象となる要素名rewardを明示し代入操作を行います.これにより,条件に当てはまる行(row)にデータが挿入されます.
df['reward'] = df['hate_food']
df.loc[ ((df['pct_sleeping'] > 0.5 ) & (df['time_in_bed'] > 5) ) | (df['age'] > 90) , 'reward'] = df['favorite_food']
10000件のデータに対して操作を行なうと以下の時間で終了したことがわかります(%%timeit)
2.34 ms ± 74.8 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
速度差の比較
上記の時間結果をもとに以下の処理速度平均のグラフが得られます

まとめ
3つのデータ挿入方法の処理速度を確認しました.明らかにvectorizedの手法が早く処理を行えるものの,複雑な条件式でこの手法を用いる場合にはコードの可読性を意識すると悩ましいところですね.
apply関数については速度もはやく,処理速度と可読性を両立した手法のように思われます.
apply関数の高速性についてはこちらの記事などで述べられています.
Discussion