DynamoDBのPITRバックアップをS3に自動でエクスポートする方法
【概要】
DynamoDBのPITRバックアップを自動でS3にエクスポートしたいと思ったことはありませんか??(多分そんな無い。)
本記事では自動エクスポートができるようになるまでの過程をご紹介したいと思います!!
【対象リソース】
\textcolor{red}{※下記の順番で構築します}
-
DynamoDB
-
S3
-
SSMパラメータストア
-
Lambda
-
EventBridgeスケジューラー
【リソース構築】
1. DynamoDB構築
①DynamoDBでテーブルを作成します。
※今回はPITRバックアップをS3バケットにエクスポートすることが目的ですのでテーブル自体の内容は適当で問題ないです。
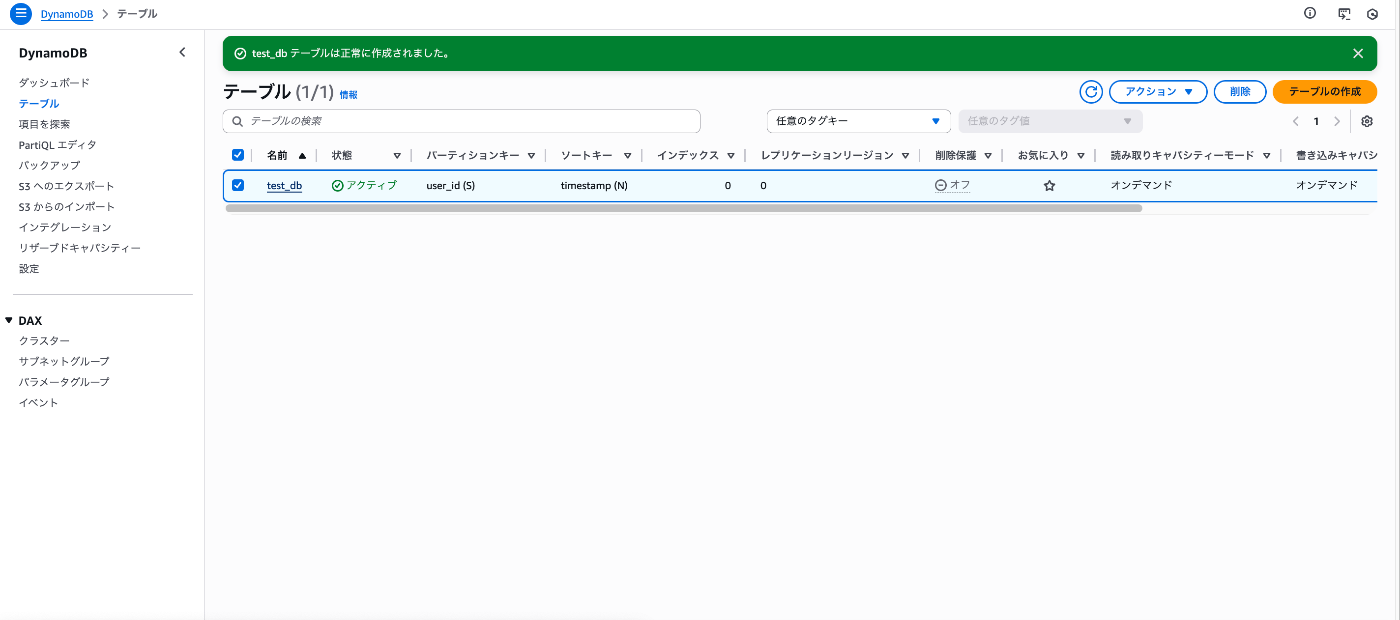
②PITRバックアップを有効にします。

※今回は検証のためバックアップ保持期間を1日間にしています。
注意点として、PITRバックアップは保持期間内にバックアップを削除することができないため、コスト面を考慮して保持期間を設定することをお勧めします。
また、「なぜ、あえてS3に長期保管するのか?」と思われる方もいるかもしれませんが、理由としては下記の例が挙げられます。
- 例)
- コンプライアンス要件のための年単位のアーカイブ
- コスト削減
- S3上のデータをAthenaなどで分析するため
2. S3バケット作成
DynamoDBバックアップ保管用のバケットを作成します。

3. SSMパラメータストア構築
Lambdaの変数を使用することができますが、今回はSSMParametersで変数を管理します。
※今回はCloudFormationで構築しましたので、コード等は別途記事で紹介する予定です。
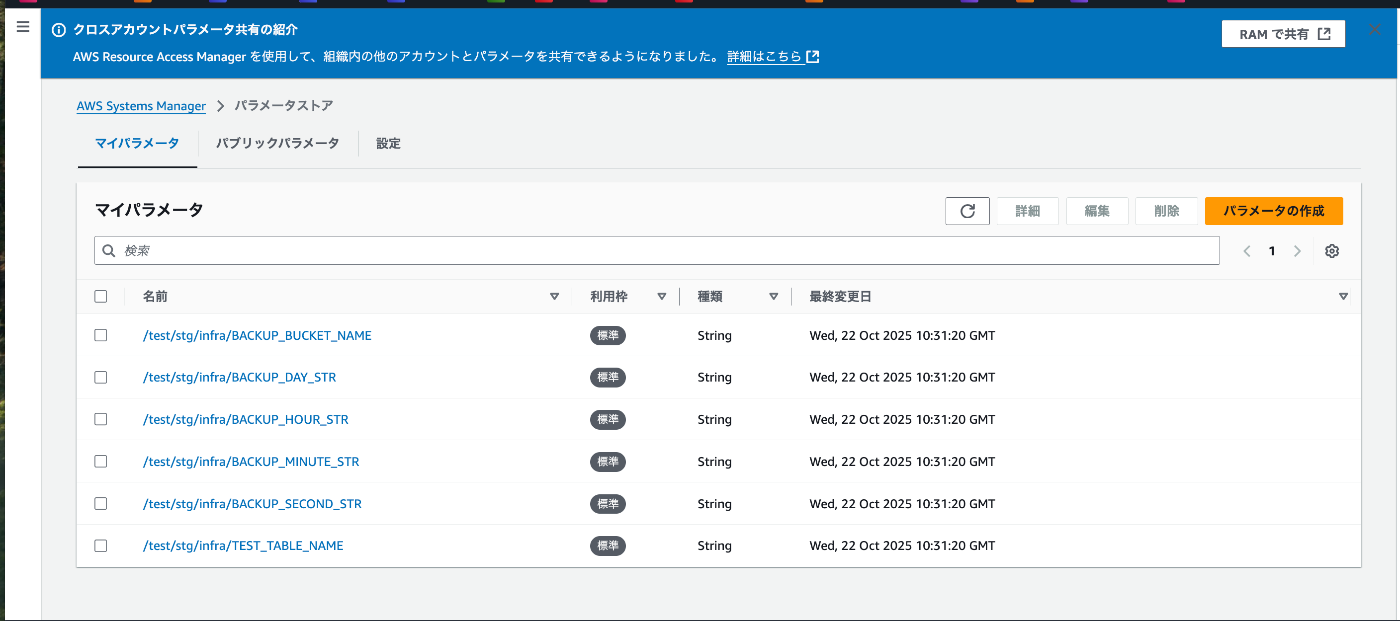
上から紹介していきましょう
- /test/stg/infra/BACKUP_BUCKET_NAME:エクスポート先のS3バケットを指定します
- /test/stg/infra/BACKUP_DAY_STR:バックアップ取得「日」を指定します
- /test/stg/infra/BACKUP_HOUR_STR:バックアップ取得「時」を取得します
- /test/stg/infra/BACKUP_MINUTE_STR:バックアップ取得「分」を指定します
- /test/stg/infra/BACKUP_SECOND_STR:バックアップ取得「秒」を指定します
- /test/stg/infra/TEST_TABLE_NAME:DynamoDBの対象テーブルを指定します
4. Lambda構築/関数作成
①Lambdaの側を構築します。

②Lambda関数を作成します。
- PITRバックアップを対象のS3バケットにエクスポートする関数
# AWS Lambda関数のインポート
import boto3
import os
import logging
from datetime import datetime
import json
from dateutil import tz
from dateutil.relativedelta import relativedelta
from src.ssm import get_ssm_parameter
# ロガーの設定
logger = logging.getLogger()
logger.setLevel(logging.INFO)
# SSMパラメータストアから設定値を取得 (文字列のまま保持)
TEST_TABLE_NAME = get_ssm_parameter('/test/stg/infra/TEST_TABLE_NAME')
BUCKET_NAME = get_ssm_parameter('/test/stg/infra/BACKUP_BUCKET_NAME')
BACKUP_DAY_STR = get_ssm_parameter('/test/stg/infra/BACKUP_DAY_STR')
BACKUP_HOUR_STR = get_ssm_parameter('/test/stg/infra/BACKUP_HOUR_STR')
BACKUP_MINUTE_STR = get_ssm_parameter('/test/stg/infra/BACKUP_MINUTE_STR')
BACKUP_SECOND_STR = get_ssm_parameter('/test/stg/infra/BACKUP_SECOND_STR')
# AWSクライアントの初期化
dynamodb = boto3.client('dynamodb')
sts = boto3.client('sts')
ssm = boto3.client('ssm')
ACCOUNT_ID = sts.get_caller_identity()["Account"]
REGION = boto3.session.Session().region_name
def get_backup_time():
"""
指定された日時のバックアップ時刻を取得する
(BACKUP_DAY_STR が "0" または数値以外の場合は「毎日」=実行日当日 を指定)
Returns:
datetime: バックアップ対象の時刻(JST)
"""
jst = tz.gettz('Asia/Tokyo')
now = datetime.now(jst)
target_day = 0
backup_hour = 0
backup_minute = 0
backup_second = 0
try:
# 時・分・秒 は数値である必要がある
backup_hour = int(BACKUP_HOUR_STR)
backup_minute = int(BACKUP_MINUTE_STR)
backup_second = int(BACKUP_SECOND_STR)
# --- 日(DAY)の判定 ---
try:
# まず数値への変換を試みる
backup_day_int = int(BACKUP_DAY_STR)
if backup_day_int == 0:
# "0" が指定された場合は「毎日」(実行日当日)
target_day = now.day
logger.info(f"BACKUP_DAY_STR が '0' のため、実行日当日 ({target_day}日) を使用します。")
else:
# 1以上の数値が指定された場合は、その日
target_day = backup_day_int
except (ValueError, TypeError):
# "EVERYDAY" など、数値以外が指定された場合も「毎日」(実行日当日)
target_day = now.day
logger.info(f"BACKUP_DAY_STR が数値でないため、実行日当日 ({target_day}日) を使用します。")
except (ValueError, TypeError):
# 時・分・秒 のいずれかが数値でない場合
logger.error(f"BACKUP_HOUR/MINUTE/SECOND_STR が有効な数値ではありません。")
raise ValueError("環境変数 BACKUP_HOUR, BACKUP_MINUTE, BACKUP_SECOND は有効な数値である必要があります")
if target_day <= 0 or target_day > 31:
# 日にちの指定が不正
raise ValueError(f"BACKUP_DAY の値({BACKUP_DAY_STR})が不正です。毎日を指定する場合は '0' を設定してください。")
try:
# replace()で日付を指定
backup_time = now.replace(
day=target_day,
hour=backup_hour,
minute=backup_minute,
second=backup_second,
microsecond=0
)
except ValueError as e:
# 例: 2月30日を指定した場合など、存在しない日付が指定された
logger.error(f"指定された日付 (day={target_day}) が今月 ({now.month}月) に存在しません。")
raise ValueError(f"日付の指定が不正です (day={target_day}): {e}")
return backup_time
def lambda_handler(event, context):
"""
AWS Lambda関数のメインハンドラー
複数のDynamoDBテーブルの毎月指定日時のバックアップをS3にエクスポートする
(S3の保存先は、バックUP指定日の年/月/日とする)
Args:
event (dict): Lambda関数に渡されるイベントデータ
context (object): Lambda関数の実行コンテキスト
Returns:
dict: 処理結果を含むレスポンス
"""
try:
# 環境変数に基づいたバックアップ対象時刻を取得
backup_time = get_backup_time()
# バックアップ対象時刻に基づいてS3プレフィックスを生成 ('YYYY/MM/DD')
s3_prefix_base = backup_time.strftime('%Y/%m/%d')
# テーブル名をリストに格納
table_names = [TEST_TABLE_NAME]
successful_exports = []
failed_exports = []
for table_name in table_names:
try:
# テーブルごとにS3プレフィックスを分ける (例: YYYY/MM/DD/table-A/)
s3_prefix = f"{s3_prefix_base}/{table_name}"
logger.info(f"バックアップをエクスポート開始: テーブル {table_name}, バックアップ時点: {backup_time.isoformat()}")
logger.info(f"S3保存先プレフィックス: {s3_prefix}")
table_arn = f'arn:aws:dynamodb:{REGION}:{ACCOUNT_ID}:table/{table_name}'
response = dynamodb.export_table_to_point_in_time(
TableArn=table_arn,
S3Bucket=BUCKET_NAME,
S3Prefix=s3_prefix,
ExportTime=backup_time,
ExportFormat='DYNAMODB_JSON'
)
export_description = response.get('ExportDescription', {})
export_arn = export_description.get('ExportArn')
logger.info(f"エクスポート開始成功: テーブル {table_name}, Export ARN: {export_arn}")
successful_exports.append({
'tableName': table_name,
'exportArn': export_arn,
'exportTime': backup_time.isoformat(),
's3Location': f's3://{BUCKET_NAME}/{s3_prefix}'
})
except Exception as e:
error_message = f"テーブル {table_name} のエクスポート中にエラーが発生しました: {str(e)}"
logger.error(error_message)
failed_exports.append({
'tableName': table_name,
'error': str(e)
})
# --- 処理結果をまとめて返す ---
# 1つでも失敗した場合はエラーレスポンスを返す
if failed_exports:
return {
'statusCode': 500,
'body': json.dumps({
'message': '一部のテーブルのバックアップエクスポートに失敗しました。',
'successfulExports': successful_exports,
'failedExports': failed_exports
})
}
return {
'statusCode': 200,
'body': json.dumps({
'message': 'すべてのテーブルのバックアップエクスポートを開始しました。',
'exports': successful_exports
})
}
except Exception as e:
# ハンドラ全体で予期せぬエラーが発生した場合
error_message = f"ハンドラ実行中に予期せぬエラーが発生しました: {str(e)}"
logger.error(error_message)
return {
'statusCode': 500,
'body': json.dumps({
'error': error_message
})
}
- SSMパラメータストアから変数を取得する関数
import boto3
from botocore.exceptions import ClientError
import logging
logger = logging.getLogger()
ssm = boto3.client('ssm')
def get_ssm_parameter(parameter_name, default_value=None, with_decryption=True):
try:
response = ssm.get_parameter(Name=parameter_name, WithDecryption=with_decryption)
return response['Parameter']['Value']
except ssm.exceptions.ParameterNotFound:
if default_value is not None:
return default_value
raise
except ClientError as e:
print(f"エラー: パラメータ '{parameter_name}' の取得に失敗しました。 {e}")
return default_value
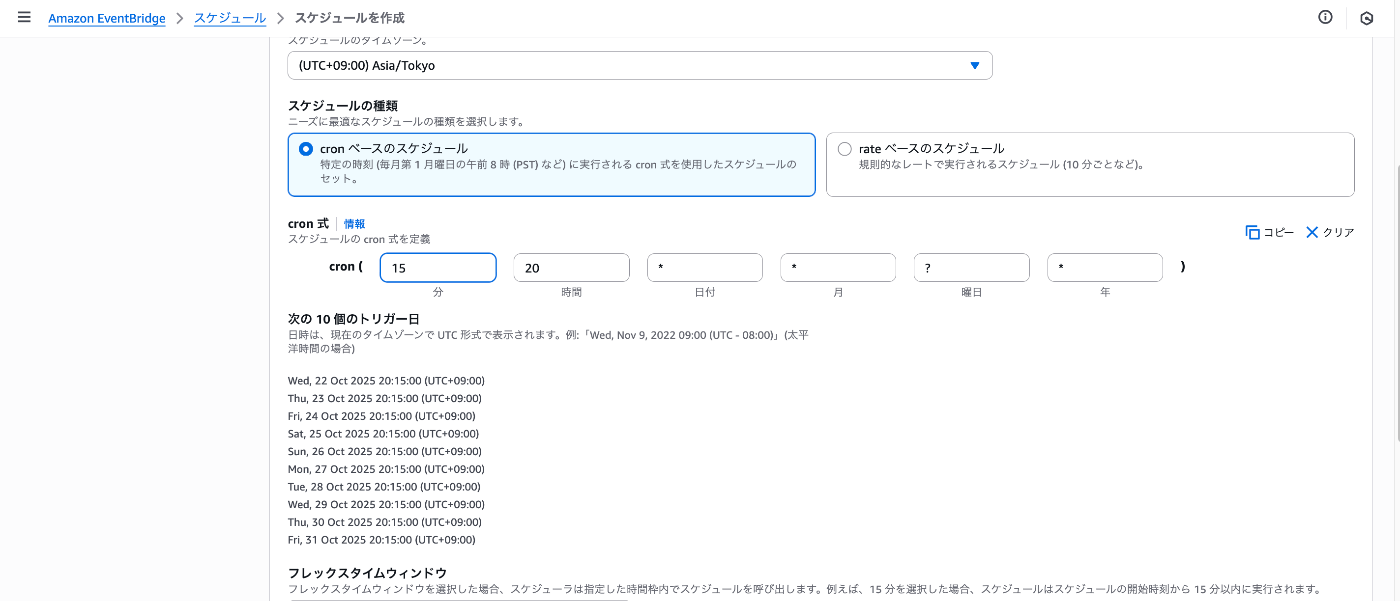
5. EventBridgeスケジューラー構築
Lambdaを起動させるスケジューラを作成します。
6. IAM権限
各リソースを機能させるには下記のIAMロールを作成する必要があります。
-
Lambdaの実行ロール: Lambda関数が他のサービスを操作するための権限です。
- dynamodb:ExportTableToPointInTime(DynamoDBのエクスポートを実行するため)
- s3:PutObject など(S3バケットにバックアップファイルを書き込むため)
- ssm:GetParameter(SSMパラメータストアから設定値を読み込むため)
-
CloudWatch Logsへの書き込み権限(ログ出力のため)
- EventBridgeスケジューラーの実行ロール: EventBridgeがLambda関数を呼び出す (lambda:InvokeFunction)ための権限です。
IAM権限が正しく付与されていないとリソースが動作しませんので、注意してください。
ちなみに筆者は最初の頃、IAM権限に頭を悩まされていました。
何でリソースが動かないんだ!と思ったら大体IAM権限に問題がありました。
【動作結果】
無事にPITRバックアップを自動で対象のS3バケットにエクスポートすることができました。

【注意点】
本記事について、あくまで個人が検証した結果に基づいて投稿しておりますので、
参考にする際は内容を完コピするのではなく、要件や環境に合わせて適宜変更していただきご活用いただくようお願いいたします。
【まとめ】
いかがでしたでしょうか!
今回初めて技術記事を投稿しましたが、こうやってアウトプットすることによって知識の振り返りができ、より一層理解度が深まった感じがします。
これからも最低月1回は投稿していきたいと思いますので、今後とも皆様よろしくお願いいたします。
また、今回各リソースの詳細な設定については説明を省いている形となりますので、別途記事で構築手順を紹介していく予定です!!
ではまた来月お会いしましょう!!
ご覧いただきありがとうございました!!
Discussion