やったらあかんで! AWSアンチパターン
概要
どうも、どすこいです!
先日投稿した 「そのDockerfile、卒業しよう」実務で通用するベストプラクティス が多くの方に読んでいただき、本当にうれしく思っています。
今回取り上げるテーマは、AWSにおけるアンチパターンです。
「AWSは触れているけれど、正直ベストプラクティスが分からないまま何となく動かしている」
「インフラは後から直せばいいと思っていたら、思った以上に深刻な状態になっていた」
そんな経験がある方はきっと共感できる内容だと思います。
この記事では、私自身が実務で遭遇した失敗や、普段のよく目にするやってしまいがちな構成を中心に紹介します。
単なる失敗談ではなく、なぜそれが危険なのか、どう改善すべきなのかまで具体的に解説しています。
この記事で伝えたいこと
開発の現場では 「すでにこの構成で動いているから」 という理由で、負債を積み重ねてしまうケースが後を絶ちません。
気づけば修繕不可能な状態になっていたり、本番障害が起きて初めて問題の大きさに気づいたりします。
アプリケーションコードのリファクタリングならまだ巻き返せますが、インフラは一度作ってしまうと後戻りが難しい領域です。
そんな悲劇を避けるためにも、この記事を通して「どこに落とし穴があるのか」を先に知ってほしいと思っています。
対象読者
- AWSを初めて触る方
- 今までAWSを何となくで構築してきた方
この記事で解説しないこと
- 各種AWSリソースの説明
解決したい課題
初心者や経験が浅いチームがAWSを扱うと、次のような問題が起きがちです。
- 最初のアカウント設計を誤り、後から環境を分離できなくなる
- VPCやサブネットの切り方を間違えて、作り直しが必要になる
- RDSやECSをパブリックに置いてしまい、セキュリティリスクを抱える
こうした状態に陥ると、後から直すには大きな工数やダウンタイムが発生します。
アンチパターン
それでは初心者がよくやりがちなアンチパターンを紹介していきます。
アカウントを分けない
複数の環境を運用する際、本番・ステージング・開発を一つのアカウントにまとめる構成は一見シンプルに見えます。
しかし、サービスが成長するほど運用が複雑化し、権限管理・誤操作・セキュリティなど多くの問題につながります。
インフラは後から分離するほどコストが跳ね上がるため、最初にこの選択を誤ると長期的な負債になります。
🙅♂️ やったらあかん
すべての環境をひとつのアカウントに詰め込む構成。
【例】
AWSアカウント
├── dev
├── stg
└── prd
(すべて同居)
この構成の問題点
- 開発メンバーを安全に参加させられない
- 本番と同じアカウントなので、誤操作のリスクが常につきまとう
- 実験が本番に影響する可能性がある
- IaC でも環境差分を吸収しづらく、コードが破綻しやすい
- 新規メンバーに権限を配るだけでも気を張る必要がある
この構成は最初こそ楽ですが、後から確実に苦しくなります。
🙆♂️ こうしよう
最初から環境ごとにアカウントを分離する。
【例】
AWS Organizations
├── dev-account
├── stg-account
└── prd-account
この構成のメリット
- 開発者にdevやstgだけのアクセス権を渡せる
→ 本番に触れないので安全 - 本番環境が完全に隔離され、誤操作のリスクをほぼゼロにできる
- それぞれのリソースが独立するため、トラブル時の影響範囲が明確
- IAM Identity Centerを使えばアカウント切り替えも簡単で、鍵管理も不要
- IaCの構成も環境ごとに整いやすく、統一しやすい
アカウントの物理的分離は、一番コストが高くても一番効果が大きい「初手の投資」です。
ここを間違えないだけで、後の運用が圧倒的に楽になります。
IAMユーザーをアカウントごとに発行する
マルチアカウント運用を始めた際に、多くのチームがやってしまうのが「各アカウントで個別にIAMユーザーを発行する」という構成です。
最初は何となく自然に見えるのですが、アカウント数が増えるほど管理が破綻しやすく、認証情報が散らばって大きなリスクにつながります。
これはマルチアカウント運用の初期で特に踏みがちなアンチパターンです。
🙅♂️ やったらあかん
各アカウントに個別のIAMユーザーを作り、認証情報を配る運用。
例
prd-account
└── IAMユーザーAさん
stg-account
└── IAMユーザーAさん
dev-account
└── IAMユーザーAさん
この構成で起きる問題
- 認証情報がアカウントの数だけ増える
→ CSVが大量に配られ、誰がどれを使っているか把握不能 - キーを失効させたくても、どのアカウントのキーか分からなくなる
- 退職者・異動者の対応が複雑になり、削除漏れ・権限残りが発生する
- 全アカウントでIAMを管理するため、運用コストが跳ね上がる
- 「あれ、どのユーザーでこのアクセスキー作ったっけ?」が必ず起きる
- 結果的にセキュリティリスクがどんどん積み上がる
🙆♂️ こうしよう
IAM Identity Centerを使い、認証は一元化する。
【参考画像】
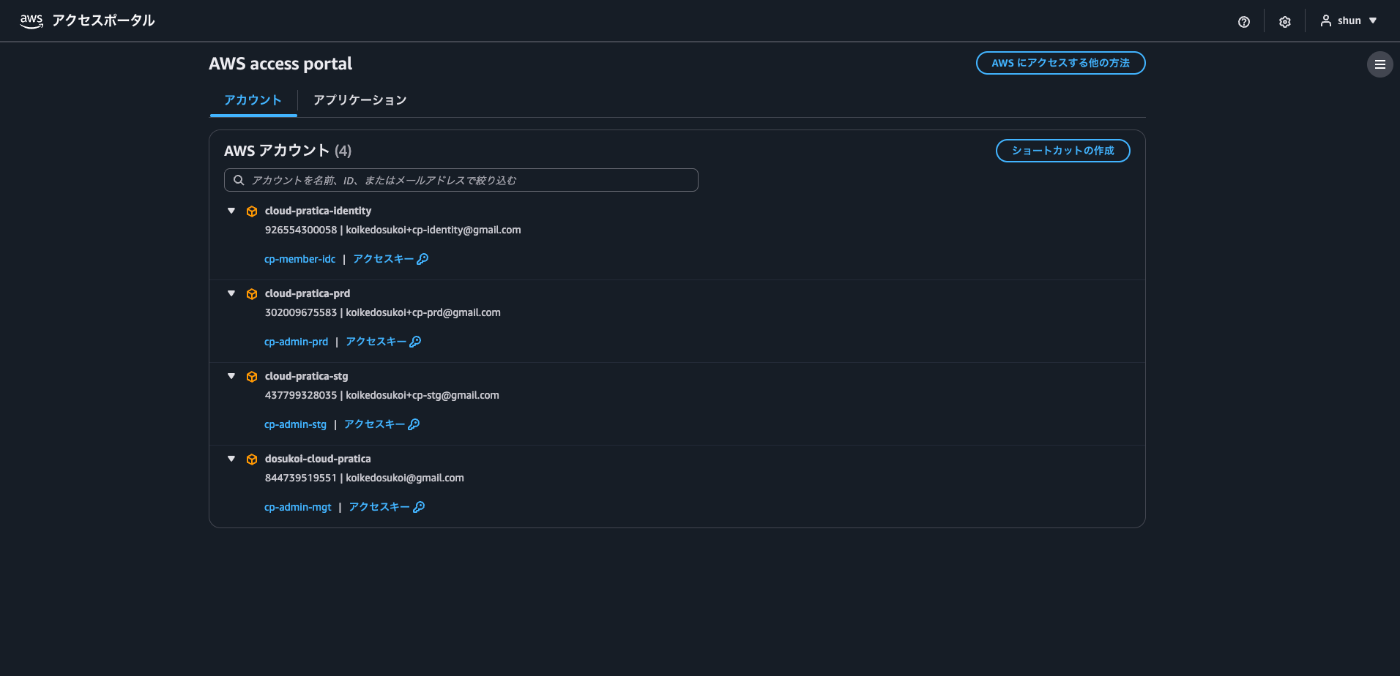
Identity Centerを使うと次のように改善されます。
- 認証情報をアカウント単位で発行する必要がない
→ 「Aさんのユーザー」はIdentity Centerに一つだけで済む - 各アカウントへの権限割り当ては「許可セット」を選ぶだけ
- キーを配らないため、漏洩リスクが根本的に減る
- 退職・異動対応もIdentity Centerのユーザーをオフにするだけで完了
現在では、IAM Identity Centerを使った認証一元化が標準的な運用です。
「アカウント数が増えるほど安全で楽になる」という構造を作るためにも、最初から採用するのが理想です。
詳しい記事は以下の記事を参照してください!後日私で実装してみた解説記事を作成予定です。
GitHub ActionsやSDKをIAMユーザーで認証する
CI/CDやアプリケーションからAWSにアクセスする方法として、IAMユーザーのアクセスキーを発行し、それをGitHub ActionsやSDKに渡して運用するケースは今でもよく見られます。
しかしこの方式は、AWS が現在推奨している方法とは大きく異なり、セキュリティ面でも運用面でも多くの問題を引き起こします。
アクセスキーを発行して貼り付けるだけなので、一見すると手軽に見えますが、長期的には最も危険な選択肢です。
🙅♂️ やったらあかん
IAM ユーザーを作り、アクセスキーをGitHub Actions、CircleCI、GitLab CI、AWS SDKなどに直接渡す構成。
この構成で起こる問題は次の通りです。
- アクセスキーは「流出した瞬間に終わり」で、攻撃者に即悪用される
- キーは永続的に有効なため、定期ローテーションや管理の手間が発生する
- 誰がどのキーを使っているか把握しづらく、権限管理が破綻しやすい
- CIが複数あったりSDKを複数のサービスで使っている場合、キーが散乱する
- 退職者が持っていたキーを把握できず、削除漏れが発生する
🙆♂️ こうしよう
CI/CDやSDKでも、すべて「ロールの一時的な認証情報」でアクセスする。
GitHub Actions → OIDC
他のCI → OIDCまたはAssumeRole
アプリケーション(SDK) → IAM ロール
という流れが現在の標準です。
この構成にすることで次の効果があります。
- アクセスキーを持たないため、漏洩リスクをほぼゼロにできる
- すべてのアクセスは STS による一時的な認証情報になる
→ 時間が来ると自動的に失効するため安全 - SDKもCIも「キーを保存しない」ため管理が不要
- アクセスのたびにロールが明確に分かれるので権限管理が透明になる
- 多数のアプリケーションやCIがあっても、ロール中心の整理された構成になる
現在のAWS運用では、「IAMユーザーのキーを配る」という方法は過去のものです。
CI/CD・SDKのすべてを一時的なロールに切り替えることで、安全で管理しやすい仕組みに移行できます。
また、先日発表されたaws loginコマンドの登場によりローカルからのアクセスも大きく変わっていきそうな予感をしています。
詳しくは以下の記事を参照してください。
リソース名の表記ブレ
AWSの運用が長くなるほど、S3、RDS、ECS、セキュリティグループ、IAM ロールなど、あらゆるリソース名に触れる機会が増えます。
その中で意外と多くのチームが抱えるのが、リソース名に統一ルールがなく、メンバーごとにバラバラな命名をしてしまう問題です。
一つ一つは小さなズレでも、積み重なると「目的のリソースが探せない」「似た名前が大量にできる」「削除していいのか判断できない」といった運用上の負債になります。
🙅♂️ やったらあかん
各メンバーが好きな名前でリソースを作る運用。
【例】
myapp-prod
my-app-production
myapp_production
myappProd
prd-myapp
myApp-PROD
この状態が続くと、次のような問題が起きやすくなります。
- どれが本番で、どれが検証用か名前だけで判断できない
- RDS・ECS・セキュリティグループなどが似た名前で並び、探すのに時間がかかる
- IaCとコンソールの名前が一致せず、管理が二重化する
- 意図しない古いリソースを残しがちで、削除判断が困難になる
- メンバーが増えるほど命名パターンが混在し、統一が不可能になる
- 同じアプリケーションなのに、リソース名の表記揺れで監査や可視化が不正確になる
開発が進めば進むほど、命名のブレは“静かに効いてくる負債”になります。
また、セキュリティグループなどは一度命名してしまうと変更することができません。
🙆♂️ こうしよう
最初に「命名規則」を決め、すべてのリソースをそのルールで統一する。
【例】
<サービス名>-stg
<サービス名>-prd
この方法にすることで次の点が改善されます。
- どの環境・どのシステム・どの役割なのか名前だけで判別できる
- リソースが並んでも読みやすく、整理された構造になる
- IaCの変数やディレクトリ構成とも連動しやすい
- 新規メンバーがすぐ慣れ、命名ミスも減る
命名規則は一度決めるだけで強力な効果があり、インフラ全体の可読性と安全性を大幅に向上させます。
小さな工夫ですが、運用が長期化するほど恩恵が大きくなる分野です。
VPCサブネット設計ミス
VPCを初めて設計するときに多いのが、サブネットの切り方を深く考えないまま作ってしまうケースです。
とりあえず適当にCIDRを割り当てたり、パブリックとプライベートの境目が曖昧だったり、AZを意識しなかったり。
最初は動いているように見えても、サービスが成長するほど「IP が枯渇する」「再設計が必要」「移行が困難」など、大きな負債になります。
VPCの作り直しは本番運用の中で最もコストが高い作業のひとつです。
そのため、最初のサブネット設計は非常に重要です。
🙅♂️ やったらあかん
サブネットの役割やCIDRのサイズを考えずに適当に切る構成。

【例】
10.0.0.0/28 public
10.0.1.0/28 private
10.0.2.0/28 db
AZ も1つだけ
このような構成では次の問題が発生します。
- IP がすぐ枯渇し、EC2・ECS・ALBが追加できなくなる
- AZを分けていないため、単一AZ障害でサービス全体が落ちる
- 将来的にVPC全体の作り直しが必要になり、移行コストが跳ね上がる
特にCIDRのサイズミスは致命的で、今後アプリケーションがグロースした際に拡張するのが難しくなります
🙆♂️ こうしよう
最初から役割・AZ・CIDRを明確に分け、余裕を持った設計にする。
【例】

10.0.0.0/16 (VPC)
10.0.0.0/20 public-subnet-a
10.0.16.0/20 public-subnet-c
10.0.32.0/20 private-subnet-a
10.0.48.0/20 private-subnet-c
この構成なら次のようなメリットがあります。
- IP が十分に確保でき、EC2・ECS・ALB・RDSを追加しても枯渇しない
- AZ を跨いでサブネットを配置するため、可用性が高い構成になる
- パブリック・プライベート・DBの役割が明確で誤配置リスクが減る
- NAT GatewayやVPC Endpointなど、後から最適なネットワーク設計へ拡張しやすい
- 将来サービスが成長しても、サブネット移行や VPC 再構築が必要なくなる
サブネット設計は「最初に手を抜くと後で必ず痛む部分」です。
動けばいいではなく、将来を見据えた余裕のあるCIDRと明確な役割分離が重要です。
RDS/ECSをパブリックサブネットに置く
RDSやECSを初めて触るとき、
「インターネットからアクセスしたいからパブリックに置けばいいか」と考えてしまうケースはどんな方でも一度は思い付いたりしませんでしたでしょうか。
しかし、データベースやアプリケーションの実行基盤をパブリックサブネットに配置するのは、
AWSの中でも特に危険度が高いアンチパターンです。
セキュリティリスクが高いだけでなく、運用や拡張も難しくなるため、この構成は後から確実に後悔します。
また、一度パブリックサブネットに置いたものをプライベートサブネットに配置するにはかなりの工数がかかります。
絶対にダメです!
🙅♂️ 絶対にやったらあかん💢
RDSやECSをパブリックサブネットに直接配置する構成

このような構成には次のような問題があります。
- RDSがインターネットから直接到達可能な状態になり、非常に危険
- ECSにパブリックIPが振られ、攻撃対象領域が不必要に広がる
- セキュリティグループを厳密に閉じる必要があり、管理が難しい
- 実は外部公開する必要がない内部APIまで外部からアクセス可能になる
- 一度パブリックに置いたリソースをプライベートに移行するのは手間が大きい
🙆♂️ こうしよう
RDSとECSは必ずプライベートサブネットに置く。
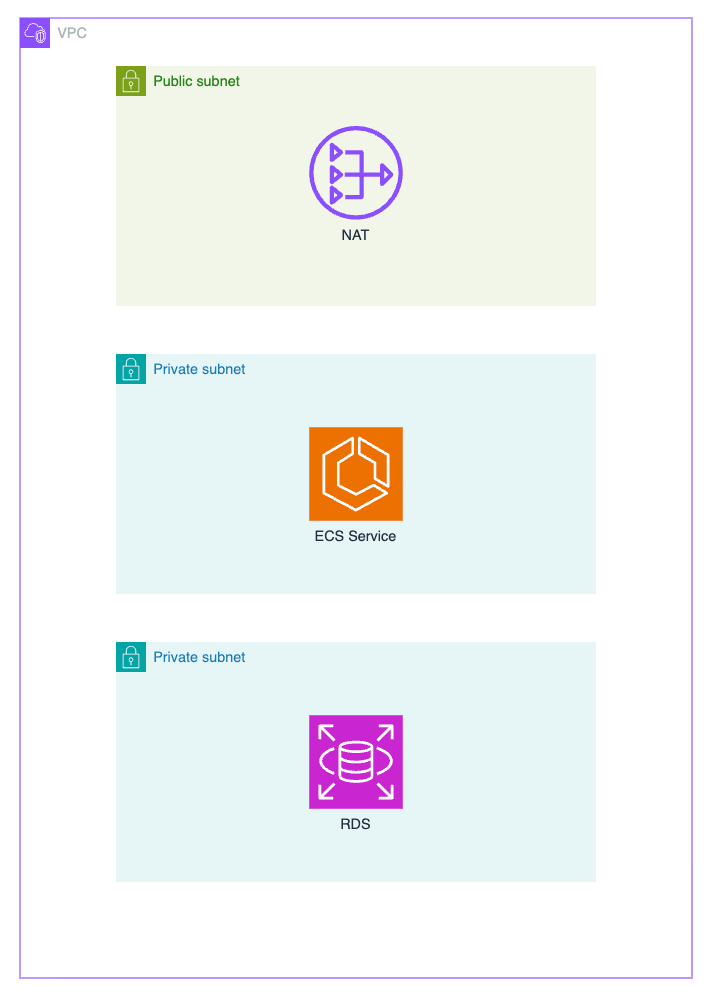
この構成にすることで、次のようなメリットがあります。
- RDSは外部から直接アクセスできなくなり、安全性が大幅に向上する
- ECSタスクはALB経由でのみ外部アクセスを受ける形になる
- IAM、SG、NAT Gatewayを使った自然なネットワーク分離が実現できる
- 内部向けAPIを誤って公開してしまう事故を防げる
もし今のサービスがRDSをパブリックサブネットに置いてしまっていたら…
AWS を触り始めた頃、深く考えずにそのままRDSを作成し、気づいたら「本番DBがパブリックサブネットにある」というケースはあるかもしれません。
実際、私自身もこの状態から移行する場面を経験しました。
ここでは私がどうやってパブリック → プライベートへ移行したかを紹介します。
ただし、この方法があらゆるプロダクトで最適とは限りません。
アプリケーションの特性や停止許容時間などを必ず考慮し、
あくまで「ひとつの例」として参考程度にしてください。
私が実際に行った移行手順(あくまで一例)
-
アプリケーションをメンテナンスモードにして、DBへの書き込みを停止する
読み込みだけ許可するケースもありますが、確実に止めたいので完全停止しました。 -
RDSのスナップショットを取得
-
スナップショットから新しいRDSを作成し、事前に用意しておいたプライベートサブネットに配置する。合わせてセキュリティグループやサブネットグループも新構成に合わせて整えます。
-
アプリケーション側の接続先(ホスト名やエンドポイント)を新しいRDSに差し替える
接続テストを念入りに行い、問題なければメンテナンスを解除して復旧しました。
この方法は「ダウンタイムを伴うスイッチ方式」で、停止可能なサービスであればシンプルに移行できます。
私が思いつく限りで、停止できないサービスの場合は、レプリカ作成 → プライマリ昇格 → 切り替えなどより複雑な手順が必要になります。
PublicからPrivateの移行ではないですが、MySQLをAurora MySQLに移行した下記の記事を上司から紹介されたのを覚えています。
もう一度念押しをしておきます。
RDSをパブリックサブネットに置くのは絶対にやめましょう
S3をPublicアクセスにしてしまう
S3を使い始めた初心者が最もやりがちなのが、「アクセスできないから、とりあえずPublicにする」というやり方です。
S3は便利なストレージですが、公開設定を1つ間違えるだけで世界中にデータが丸見えになるというサービスでもあります。
企業向けプロダクトであれば、漏えいした瞬間アウトの情報(例えば、免許証とかの画像)が入っていることも多く、Public化は絶対に避けたいアンチパターンです。
🙅♂️ やったらあかん
S3バケットの「すべてのパブリックアクセスをブロック」をOFFにしてしまう構成。

URLを貼り付ければ誰でもアクセスできる状態。
この構成が良くない理由
- 画像や PDF、動画が世界中に公開されてしまう
- 悪意あるクローラーに大量ダウンロードされる可能性
- 権限を間違えるとアップロード・削除まで許可される
- バケット名がURLに露出し、攻撃対象になりやすい
「Public ONにすればとりあえず動く」というのがこのアンチパターンの怖さです。
🙆♂️ こうしよう
S3は完全 Private にし、CloudFront + OAC を必ず前段に置く。
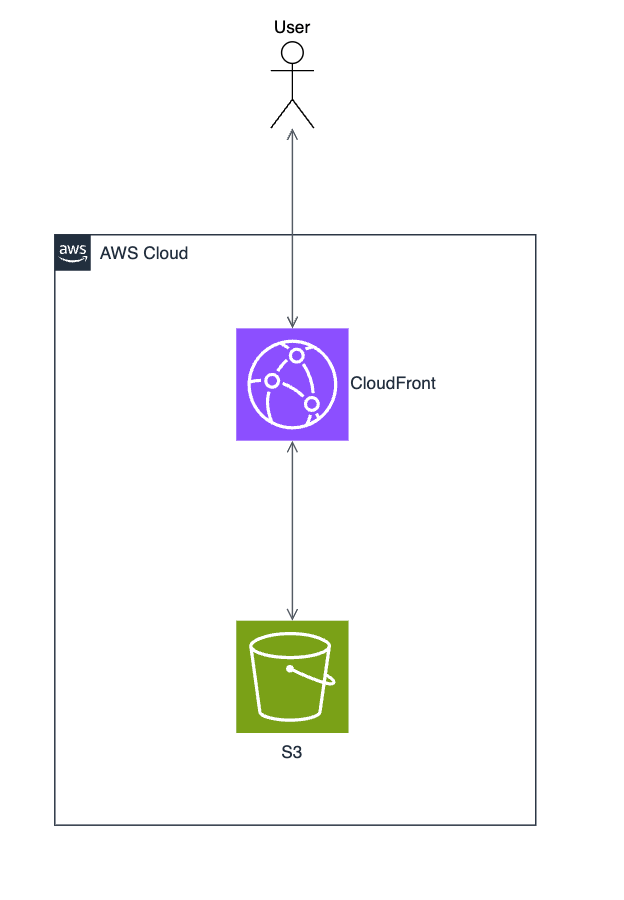
OAC(Origin Access Control)を使うことで、CloudFrontからのリクエストだけS3に届くというアクセス制御が実現できます。
この構成で得られるメリット
- S3 は完全privateのまま安全に公開できる
- S3のURLを知られても直接アクセスは不可能
- CloudFront側にWAF, 署名付き URL / Cookie, キャッシュ制御を載せられる
- 実質これがS3公開の“標準構成”といってよい
CloudFrontを挟むことで、セキュリティ・速度・運用が改善されます。
神セキュリティグループ(なんでも通すセキュリティグループ)
AWSを使い始めて間もない頃に、「よくわからないけど通信が通らない」という場面に直面すると、多くの人が最後に辿り着く禁断の手段があります。
それがいわゆる 神セキュリティグループ です。神クラスのセキュリティグループ版です。
インバウンド・アウトバウンドともに「全てのトラフィックを許可する」という設定で、どんな通信でも通してしまう魔法のSGを指します。
作った瞬間に全部動くので、一見すると便利ですが、これはインフラ運用では最悪レベルのアンチパターンです。
🙅♂️ 絶対にやったらあかん💢
全トラフィック許可のセキュリティグループを、複数サービスで使い回す構成。
【例】


この状態が危険な理由
- どこからどこにアクセスされているのか把握不可
- 本来閉じるべきDBや内部APIが全世界から叩ける状態になる可能性がある
- SGを変更するとどのサービスが落ちるか読めなくなる
- インフラ調整のたびに“賭け”になる
さらに最悪なのは、一度このSGをいろんなリソースにアタッチしてしまうと、剥がせなくなるという点です。
どのサービスがどの方向に通信しているのか分からなくなり、
結局「怖いから神SGのままにしておこう」という沼に落ちます。
🙆♂️ こうしよう
セキュリティグループは必ず 役割単位・サービス単位で分離する。
おすすめの作り方
- EC2の踏み台用
- ECSサービスごと
- Lambda関数ごと
- RDSインスタンスごと
- ALBごと
そして、インバウンドはCIDRではなく必ずアクセス元SGのIDを指定するようにする。
こうすることで「どのサービスがどこに通信しているのか」が明確に表現でき、依存関係が整理されたクリーンな構成になります。
例えば
ALB → ECS
ECS → RDS
であれば、
ALB SG → ECS SG
ECS SG → RDS SG
というように、SG の紐づきだけで“アーキテクチャ図そのもの”が見えるようになります。
【ECSのSGのインバウンドルールの一例】
ターゲットにALBのSGを指定している

なんでもNAT Gatewayに流してしまう
AWSを触り始めてしばらくすると、「プライベートサブネットのECSやLambdaが外部APIを叩けない」「パッケージのダウンロードが失敗する」といった問題に必ず遭遇します。
そこで多くの人が選ぶのがNAT Gatewayをとりあえず1個置いて全部そこに流すという構成です。
動くので便利ですが、実はこのやり方には見落としが多く、特にコストと可用性の観点でアンチパターンになりやすい構成です。
🙅♂️ 絶対にやったらあかん💢
とりあえず1つNAT Gatewayを置き、すべてのプライベートサブネットの通信をそこに集約する構成。
この構成の問題点
-
料金が跳ね上がりやすい
- S3 への大量アクセス
- 外部 API への高頻度アクセス
- コンテナのパッケージ・依存の大量ダウンロード
-
本来privateにできるサービスが、不要にネットを経由している
- S3, DynamoDB, CloudWatch Logsなどは本来VPC Endpointで完結する
初心者〜中級者の現場でよくあるのが、「毎月NAT Gatewayに5〜10万円払ってるのに誰も気づいていない」というパターンです。
🙆♂️ こうしよう
1.「VPC Endpointで済むもの」は絶対NAT Gatewayを通さない
S3、DynamoDB、CloudWatch Logs、ECR、Secrets Manager、SSMなど、
多くの AWS サービスは VPC Endpoint を使えばインターネットを経由せずに通信できます。
これを使うと、
- NAT Gateway経由の通信が激減
- Data Processing料金が下がる
- 通信がAWS内だけで閉じるため安全性も向上
ECS Execを無効化していて、本番デバッグができない
ECSを本番運用していると、必ず一度は「コンテナの中に入りたい」「中で何が起きているか確認したい」という瞬間が訪れます。
しかし、初心者〜中級者の現場でよくあるのが、ECS Exec が有効化されていないせいで、本番デバッグができないという問題です。
🙅♂️ やったらあかん
ECS Execを有効化しないまま本番運用に突入してしまう構成。
この状態の何が問題か
- コンテナ内部で何が起きているか一切わからない
- CPUやメモリだけでは原因が追えない障害で詰む
- 再現性のない本番だけの不具合に弱すぎる
- バッチなど非同期処理のトラブルが致命的になることもある
🙆♂️ こうしよう
ECS Execを有効化し、安全にコンテナへ接続できる仕組みを整える。
この構成で得られるメリット
- コンテナ内部でリアルに状況を確認できる
- 本番のファイル構造・権限・環境変数のチェックが容易
- ネットワークの疎通確認(curl / dig)ができる
- 予期せぬエラーの原因特定が圧倒的に早くなる
- バッチの失敗原因も即座に追える
ECS タスク定義に環境変数ベタ書き
ECSを使い始めると、まず触ることになるのがタスク定義です。そして多くの初心者がやってしまうのが、環境変数をタスク定義に直接ベタ書きするという構成です。
🙅♂️ やったらあかん
タスク定義の environment にアプリの設定をすべて書き込む構成。
【例】
{
"containerDefinitions": [
{
"name": "api",
"environment": [
{ "name": "DB_PASSWORD", "value": "password" },
{ "name": "API_URL", "value": "https://example.com" },
{ "name": "ENV", "value": "production" }
]
}
]
}
この構成が抱える問題
- 機密情報が丸見え
- たとえ IAM で守っていても、修正できる人は全員DBパスワードを閲覧できる
- 複数タスクで値が散らばり、変更が地獄
- API、バッチ、ワーカーなどで同じ環境変数を重複管理
- タスク定義のバージョンが無駄に増え続ける
- 値を変えるたびに新バージョンが作られて追跡不能
- シークレットをローテーションしづらい
- パスワード変更のたびに全タスク定義を作り直す必要がある
- Terraform / CDKと相性が最悪
- 値の更新=コード修正になり、インフラチームの負担が爆増
🙆♂️ こうしよう
環境変数は「非機密」と「機密」で必ず分けて管理する」 というのがECSの基本的なベストプラクティスです。
1.非機密情報はS3またはSSM Parameter Store
環境名、ログレベル、外部APIのURLなどは .env 相当の設定なのでタスク定義ではなく外部ファイルで管理できます。
【例】
- S3のenvironmentFiles
- SSM Parameter Store の
--with-decryption=falseな値 - 「アプリ設定リポジトリ」を作りそこから同期する方法もあり
▫️メリット
- バッチ・API・ワーカーが同じ設定を一括で参照できる
- タスク定義を触らず値だけ更新できる
- IaC とアプリの責務を綺麗に分離できる
2.機密情報は Secrets Manager
DBパスワード、APIキーなどはSecrets Managerにおきます
コンテナ定義では次のように参照します。
"secrets": [
{
"name": "DB_PASSWORD",
"valueFrom": "arn:aws:secretsmanager:ap-northeast-1:xxx:secret:db-main:password::"
}
]
▫️メリット
- タスク定義に値が露出しない
- IAM で最小権限のアクセス制御ができる
- パスワードローテーションが簡単
- Secrets Manager側でJSONにまとめて管理できる
(値ごとにシークレットを分ける必要はない)
ECRのlatestタグで本番デプロイ
Dockerイメージのタグ運用で初心者が最もやってしまうのが、ECR に latestタグを付けて、そのまま本番にデプロイするというやり方です。
検証環境ならまだしも、本番で latest を使うと「どのバージョンがデプロイされているか誰も説明できない」という危険な状況に陥り、障害対応が極めて困難になります。
🙅♂️ やったらあかん
ECRに常に:latestをpushし、ECSもLambdaも本番でlatestを参照する構成。
この構成で起きる問題
- どのコードが本番で動いているか誰もわからない
- デプロイをロールバックできない
- 自動デプロイの失敗原因が特定できない
- 最新タグの上書きで過去のイメージが消える
- ECSのキャッシュがdigestを保持するため、“ズレ”が起きる
- → タスク再起動で謎のイメージpullエラーが発生
🙆♂️ こうしよう
本番デプロイではイミュータブルタグを使うのが必須です。
特におすすめはGitHubのコミットハッシュをタグに使う
【例】
myapp:7e627d10
myapp:a19bd3f2
こうすると、
- どのコミットが動いているかGitHubで一発で追跡できる
- 過去のバージョンに戻したい時もタグだけ戻すだけ
- タグが上書きされず、digestが常に一致
Lambdaのコンソールエディタでコード編集してしまう
AWS Lambdaは“手軽に動くという特徴があるため、初心者がまず触るのがコンソール上のコードエディタです。
数行のテストであれば便利なのですが、これをそのまま本番運用に持ち込むと、後々管理不能になるアンチパターンの代表例になります。
🙅♂️ やったらあかん
Lambdaのマネジメントコンソール上でコードを直接編集し、そのまま本番で運用してしまう構成。
この状態が危険な理由
- コードレビューができない
- GitHub / GitLabを通らないので品質担保が不可能
- 誰が何をいつ変更したか分からない
- エディタのコードが唯一の真実になる(超危険)
- リポジトリとLambdaのコードが乖離していく
- ランタイム更新に追従できない
🙆♂️ こうしよう
Lambdaのコードは必ずリポジトリで管理し、CI/CDでデプロイする。
その際のベストプラクティスはコンテナイメージ化して運用することです。
この構成のメリット
- LambdaのコードがGitでレビュー・管理できる
- デプロイが常に再現性を持つ
- IaC(Terraform / CDK)はLambdaのメタ情報だけ管理すればよい
- ランタイム更新の影響を最小化できる
- チーム全体でコードの一貫性が保てる
RDSのバックアップ保持期間デフォルト7日の罠
RDSは自動バックアップ機能を持っており、何も設定しなくても毎日スナップショットを取得してくれます。
そのため、初心者は「デフォルトでも十分守られている」と思いがちです。
しかし、RDS のバックアップ保持期間はデフォルトで7日間に固定されています。
一見、問題なさそうですが、実はこれが非常に危険で、長期運用しているサービスほどリスクが高まるアンチパターンです。
🙅♂️ やったらあかん
バックアップ保持期間を7日間のまま放置した構成。
この構成が危険な理由
- バックアップを取っていても8日前には戻れない
- 誤操作やデータ破損が1週間前に起きていた場合は詰む
- アプリケーションのバグが気づかぬうちにデータを破壊する可能性
- → 7日という短さでは手遅れになるケースがある
- 法的・業務的に長期保管が必要な業種では完全にアウト
- 医療、金融、基幹システムなどは1〜12ヶ月を推奨します
🙆♂️ こうしよう
バックアップ保持期間をサービスの性質に合わせて伸ばす。
特に法的・業務的に長期保管が必要なサービスは十分なバックアップが必要です
RDS自動マイナーバージョンアップの事故
RDSには便利な自動マイナーバージョンアップ機能があります。
マイナーバージョンに対しては互換性のあるアップデートなので、「有効のままで良い」と思いがちです。
🙅♂️ やったらあかん
自動マイナーバージョンアップを有効化したまま、本番で運用を続けてしまう構成。
この設定が危険な理由
- アップデート中は RDS が一時的に停止する(数秒〜数十秒)
- 本番APIが全部500/timeout
- アプリケーションのコネクションが切れ、復帰に失敗することがある
- ORマッパーや接続ライブラリが再接続に弱い場合は壊滅的な挙動になる
- アップデートによってパラメータの挙動が変わるケースもある
- 実質マイナーではなくメジャー相当の変更になることも
- メンテナンスウィンドウを深夜に設定していると深夜に不可解な障害が起きるかも
実際の事故としてよくあるのが、「深夜3時にAPIが数分間全部落ちていたが理由がわからない」
→ RDSイベントを見たらマイナーバージョンアップだったというパターンです。
実際に私も経験したことがあります。深夜にDBの接続が失敗していて大慌てしたことがあります。そのサービスは他チームから引き継いですぐでRDSの自動アップデートをONにしていることを把握していなかったのです。
🙆♂️ こうしよう
本番環境では自動マイナーバージョンアップを無効化するのが一般的です。
代わりに次の運用へ移行するのが安全です。
1. マイナーバージョンアップは「自分たちでコントロールして実施」
- 検証環境 → 本番の順で確認して、問題なければ本番に適用する方式。
2. 本番アップデートは「業務停止の影響が最小の時間帯に“手動”で実施」
- 全ての API の挙動監視
- 事前に接続数を確認
補足:本当に自動アップデートでもいいケース
以下のような 小規模・非クリティカル用途であれば、有効化も選択肢に入ります。
- 個人開発
- 深夜の数分停止が許容されるサービス
- 一時的なDB
S3バージョニング無効(デフォルトのまま使ってしまう罠)
S3 は非常に安定したストレージで、「とりあえず置いておけば消えない」という安心感があります。
しかし初心者がやってしまいがちなのが、バージョニングを無効のまま(デフォルト)で運用してしまうという構成です。
🙅♂️ やったらあかん
S3をバージョニング無効のまま本番運用に使ってしまう構成。
この構成が危険な理由
- 誤って上書き保存したら最後、復旧できない
- 誤削除が発生したら、そのまま永遠に消える
- アプリのバグでオブジェクトが壊れても元に戻せない
- 運用者が “何をいつ壊したか” の証跡すら残らない
- バッチ処理が失敗して不正なファイルを書き込んでも追跡不能
- 障害調査で「前のファイルに戻す」という一番基本的な操作が不可能
実際の現場では、「誰かが間違えて画像を上書きした」「古いデータに戻したい」というトラブルは頻繁に発生します。
バージョニング無効のままだと、どれも復元不可能になります。
🙆♂️ こうしよう
S3 は原則としてバージョニングを有効にする。
この構成のメリット
- 誤って上書きしても旧バージョンに戻せる
- 障害調査で“壊れる前の状態”を確認できる
- 思わぬ上書き事故が起きてもレベルの低い復旧で済む
開発初期からバージョニングを ON にしておくと、後からの移行コストもゼロで済むため特におすすめです。
ただし注意:バージョニングは「永遠に増える」
バージョニングは安全性の代わりに ストレージコストが増える 仕組みです。
そのため以下のように運用を組み合わせるとベストです。
おすすめの運用
- Lifecycle で古いバージョンを一定日数で削除
- 長期バックアップはGlacierに移行する
- 不要ファイルを自動削除するルールを設ける
このようにすることで保険としての巻き戻し能力を維持とコストを最適化の両立ができます。
EBSの削除し忘れ(静かに請求を積み上げる罠)
EC2 を操作していると、「インスタンスを消したから全部片付いた」と思いがちですが、AWSのEC2はインスタンスとEBSが別物として管理されています。
そのため初心者が特にやってしまうのが、EBS ボリュームだけが残り続けて、気づいたら請求が膨らむというパターンです。
🙅♂️ やったらあかん
EC2 を削除しただけで満足し、紐づいていたEBSが孤立したまま放置される構成。
この状態が危険な理由
- 使っていないEBSの分だけ、常に料金が発生する
- gp3 / gp2 は容量に対して固定課金
- 100GBなら毎月数千円が永遠に発生
- スナップショットも別料金で積み上がる
- 古いスナップショットが大量に残り続ける
- 何の用途か誰も把握していない謎ボリュームが残り続ける
- 消していいか判断できないボリュームが増える
- → 何年も放置される典型パターン
- 大規模環境だと請求への影響が甚大
- 月数万円〜数十万円レベルの無駄につながる
🙆♂️ こうしよう
1. EC2 作成時はDelete on terminationを必ず有効化
EC2 のルートボリュームはDeleteOnTermination = trueにしておけば、インスタンス終了時に自動で消えます。
特に検証環境・スポットインスタンスでは必須です。
2. 不要になった EBS は定期的に棚卸し
やるべきこと
- AWSコンソールで“未アタッチ”のボリュームを確認
- 所有者タグ(Owner / Project)を必ず付ける
- 「誰のかわからない=削除できない」状態を作らない
- 月 1 回の棚卸しが効果的
3. IaC による管理に統一
Terraform / CDK で EC2 と EBS をまとめて管理することで、
- インスタンス削除 → ボリューム削除の流れを一貫してコード化できます。
属人的な EBS の残骸が減り、管理しやすくなります。
4. スナップショットもライフサイクルを設定
手動スナップショットが残り続けるのもかなり危険です。Lifecycle Manager を使って、
- 古いスナップショットを自動削除
- 重要データだけ長期保管
といったルール化ができます。
おわりに
今回はAWSにおけるアンチパターンを紹介してきました。
何度も言いますが、インフラの手戻りは大幅に工数がかかるうえ、ダウンタイムも発生します。
この記事を読んで事前に悲劇を防いで欲しいです。
もし、すでにアンチパターンを踏んでしまっている方は負債が大きくなる前に修正するのを強く推奨します。
理由は負債は複利だからです。返済できるなら気づいたあなたが何とかして返済しましょう!
それが次に入ってくるエンジニアのためないし、顧客の価値提供にもつながります!
ごっちゃんでした!!
Discussion