【CloudFormation/S3/Lambda】S3へのファイルアップロードをトリガーにLambdaを実行する<実装編>





1.はじめに
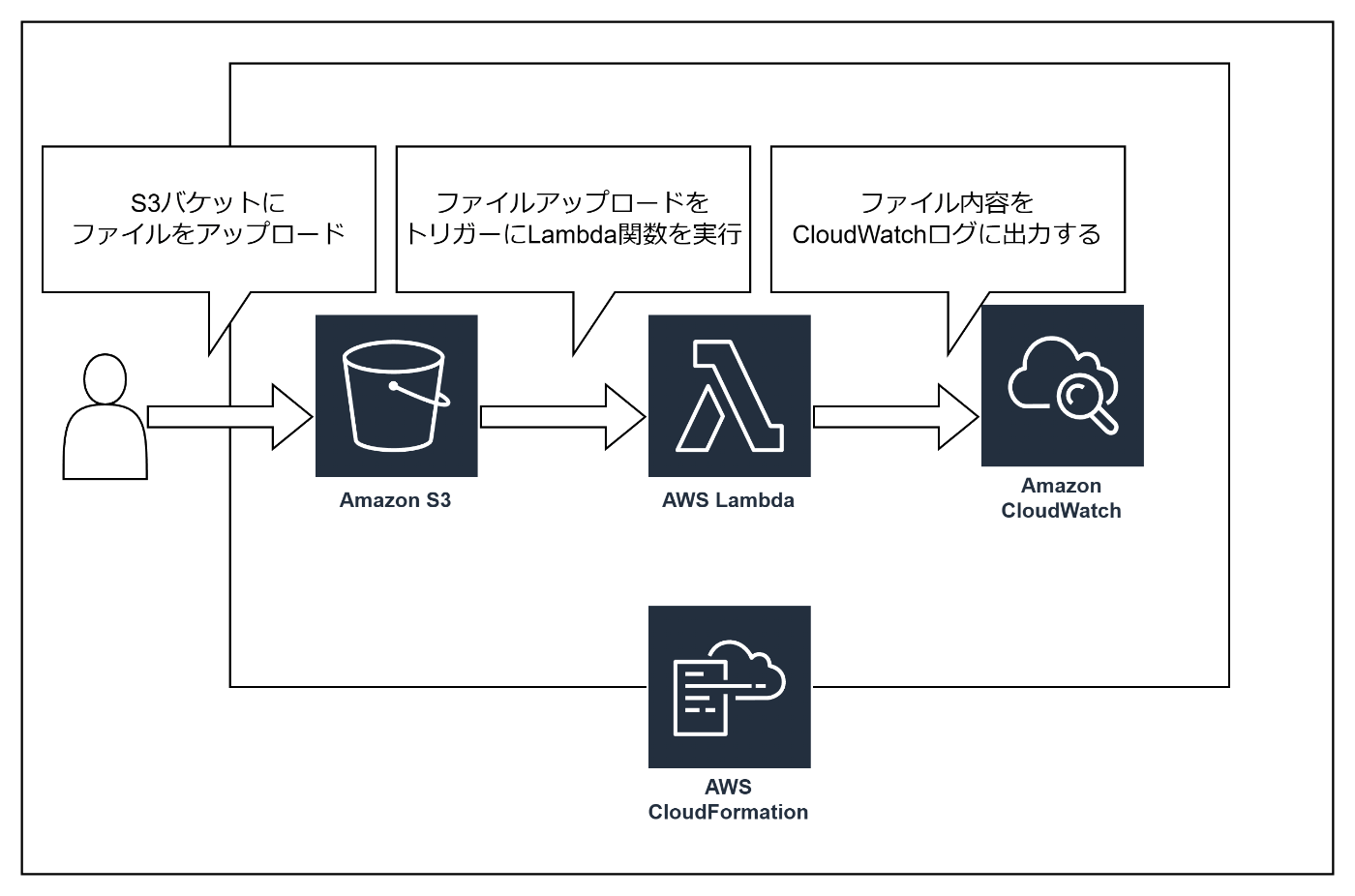
今回はAWSのLambdaを使った簡単なサーバレスアプリケーションを作ってみたいと思います。
実装物の機能イメージは以下の通りです。
- S3にファイルをアップロードする
- ファイルのアップロードを起点にLambda関数を実行する
- Lambda関数上でアップロードファイル内容を取得する
また、各リソース(S3/Lambda)をテンプレート化してCloudFormationでデプロイできるようにします。
この記事は実装編とデプロイ編の2部構成となっています。
- 実装編:PythonでのLambda関数実装が中心
- デプロイ編:「template.yaml」の記述方法・デプロイ後の動作確認方法が中心
今回は実装編ということでPythonでのLambda関数実装を行っていきます。
本記事で実装するものは以下リポジトリに上げています。
2.準備
本記事では以下を前提とします。
- AWS環境があることを前提とします
- Lambda関数の実装はPythonを使用します
- 【実装編では任意】AWS SAMの環境構築を終えていること
- 【実装編では任意】AWS SAM CLI利用の準備
■ ディレクトリ構成
本記事では以下のディレクトリ構成で進めます。
親ディレクトリ
┣ samconfig.toml ← デプロイ編で作成
┣ template.yaml ← デプロイ編で作成
┣ common_layer
┃ ┗ requirements.txt ← 実装編で作成
┗ s3_lambda_functions
┗ lambda_function.py ← 実装編で作成
■ ライブラリ
ここでは実装の前提となるライブラリについて説明します。
今回使用するライブラリは以下の通りです。
※★の付いているライブラリはLambdaの実装で必須級のライブラリです。
| ライブラリ | 説明 |
|---|---|
| ★json | Lambda関数上でレスポンス操作を行う都合上、必須と言えるライブラリです |
| ★aws-lambda-powertools | Lambdaでの実装を支援するライブラリです |
| ★boto3 | AWSの各種サービスを操作するためのライブラリです |
| urllib | 文字コードをデコードするために使用します |
requirements.txtの作成
Lambda関数上で使用するライブラリの準備を行います。
紹介したライブラリを「common_layer」配下に「requirements.txt」として定義します。
※「json」と「urllib」はデフォルトで導入済みのため不要です。
aws-lambda-powertools==2.42.0 ; python_version >= "3.11" and python_version < "3.12"
boto3==1.34.151 ; python_version >= "3.11" and python_version < "3.12"
3.実装
それでは以下の流れで実装の説明を行います。
- ライブラリのインポート
- loggerの定義
- メインメソッドの定義
- eventからS3の情報を取得
- boto3を使ってアップロードファイル内容を取得する
コード全体としては以下の通りです。
全体のコード
import json
from urllib.parse import unquote_plus
import boto3
from aws_lambda_powertools import Logger
logger = Logger()
def lambda_handler(event, context):
logger.info(json.dumps(event))
# バケット名
bucket_name = event["Records"][0]["s3"]["bucket"]["name"]
logger.info(bucket_name)
# オブジェクトキー
object_key = unquote_plus(event["Records"][0]["s3"]["object"]["key"])
logger.info(object_key)
# ETag
etag = event["Records"][0]["s3"]["object"]["eTag"]
logger.info(etag)
# サイズ
size = event["Records"][0]["s3"]["object"]["size"]
logger.info(size)
# S3にアップロードされたファイル内容を取得
s3_client = boto3.client("s3")
response = s3_client.get_object(Bucket=bucket_name, Key=object_key)
file_content = response["Body"].read()
logger.info(file_content)
■ 手順1:必要なライブラリのインポート
はじめに必要なライブラリをインポートします。
import json
from urllib.parse import unquote_plus
import boto3
from aws_lambda_powertools import Logger
■ 手順2:loggerの定義
次に「aws_lambda_powertools」からインポートした「logger」を定義します。
「logger」を定義することでLambda関数のCloudWatchログにログ出力 できます。
logger = Logger()
■ 手順3:メインメソッドの定義
メインメソッドの実装に入ります。
メソッド定義の書き方についてですが以下の形が決まり文句のような記述方法となります。
def lambda_handler(event, context):
| 引数 | 説明 |
|---|---|
| event | Lambda関数が呼び出されたときの引数となるデータです。 今回の場合、S3にアップロードされたファイル情報が与えられます。 |
| context | Lambda関数の実行環境に関する情報が格納されます。今回は使用しません。 |
■ 手順3:eventからアップロードファイル情報を取得
次に「event」からアップロードされたファイル情報を取得します。
引数として与えられる 「event」は以下のようなJSON形式のデータ で与えられます。
eventの中身のイメージ
{
"level": "INFO",
"location": "lambda_handler:11",
"message": {
"Records": [
"s3": {
"s3SchemaVersion": "1.0",
"configurationId": "ダミー",
"bucket": {
"name": "lambda-bucket-20240919",
"arn": "arn:aws:s3:::lambda-bucket-20240919"
},
"object": {
"key": "public/test.txt",
"size": 23,
"eTag": "qawsedrftghyujikolp123456789",
"sequencer": "0123456789ABCDEFG"
}
}
}
]
},
}
Lambda関数ではJSON形式の「event」の各項目に対して、次のようにアクセスするコードを書くことが基本 となります。
# バケット名
bucket_name = event["Records"][0]["s3"]["bucket"]["name"]
# オブジェクトキー
object_key = unquote_plus(event["Records"][0]["s3"]["object"]["key"])
# ETag
etag = event["Records"][0]["s3"]["object"]["eTag"]
# サイズ
size = event["Records"][0]["s3"]["object"]["size"]
※オブジェクトキーだけ「unquote_plus」を使っています。
これは、アップロードファイル名が日本語などの場合、「%E3%81%82」のように文字コードとして取得されるためです。「unquote_plus」を使うことで文字コード→正しい文字列に変換できます。
■ 手順4:Boto3を使ってアップロードファイルのバイナリを取得
最後にアップロードされたファイルのバイナリを「boto3」を使って取得してみます。
まず、boto3クライアントを定義し、引数にAWSサービス名(S3)を与えます。
s3_client = boto3.client("s3")
それでは、実際にboto3を操作します。
S3の格納物取得には、「バケット名」と「オブジェクトキー」を引数として以下の形で取得できます。
response = s3_client.get_object(Bucket=bucket_name, Key=object_key)
実装段階では確認できませんが、loggerに出力されたresponseもJSON形式で出力されます。
responseの中身のイメージ
{
"level": "INFO",
"location": "lambda_handler:32",
"message": {
"Body": "<botocore.response.StreamingBody object at 0xffff813ab820>"
},
}
S3にアップロードされたファイル情報は上記の「Body」に格納されています。
そのため、以下のように更にレスポンスの「body」を取得します。
file_content = response["Body"].read()
すると以下のように「message」部分にファイル内容が出力されます。
bodyの中身のイメージ
{
"level": "INFO",
"location": "lambda_handler:34",
"message": "アップロードファイル内容",
"service": "S3Application",
}
5.おわりに
今回の記事では、S3にアップロードされたファイルをトリガーとしてLambda関数を実行し、アップロードされたファイルの内容を取得するサーバレスアプリケーションの実装手順について説明しました。
この実装により、S3にファイルがアップロードされるたびに、ファイル内容をLambda関数で処理するフローを簡単に構築できます。
次回のデプロイ編では、Lambda関数をAWS環境にデプロイする手順や設定ファイルの記述、デプロイ後の動作確認方法について詳しく解説します。
補足
■ Lambda関数に対してS3トリガー設定を行う方法
template.yamlを使わずに、Lambda関数にトリガーを追加する方法を紹介します。
AWSマネジメントコンソールから「Lambda → 関数 → 対象のLambda関数」に遷移します。
「設定」タブから「トリガーを追加」をクリックします。

以下のように設定し、「追加」をクリックします。
- ソース:S3
- バケット:任意のバケット
- イベントタイプ:すべてのオブジェクト作成イベント
- 再帰呼び出し:チェックを入れる

Discussion