Pythonのlistをもっと便利に +α 【大規模ソフトウェアを手探る】
これは何?
この記事は、東京大学工学部電子情報工学科/電気電子工学科の後期実験「大規模ソフトウェアを手探る」のレポートとして作成されました。この実験では、各班がOSSを1つ選び、開発技法を学びながら新たな機能追加やバグ修正などを試みます。私たちの班(@irungo_ic, @yutyan_ut, @ncrpy)はCPython を選びました。
CPythonとは
プログラミング言語であるPythonの、C言語による実装です。つまり、C言語で書かれたPythonのインタプリタです。
CPythonを選んだ理由
班員全員にCとPythonの経験があり、言語処理系などの基盤的なソフトウェアに興味があるメンバーが集まったためです。特にCPythonは公式ドキュメントが非常に充実していること、Buildの方法がそれほど大変ではないことなども選択の大きな理由になりました。
追加した機能
私たちの班は次の2つの機能を追加しました:
-
listに対する高階関数の適用をMethodとして書ける機能 -
numpy.ndarrayのように、tupleでlistの要素を参照できる機能 -
typing.TypeVarにdefault値を追加する(PEP696)
これらがどのようなもので、なぜ嬉しいのか、どう実現したのかを説明していきます。
1. 高階関数(map, filter等)をlistのMethodとして使う
モチベーション
商品を表す以下のようなClassがあるとします。
class Product:
def __init__(self, name: str, price: int, weight: float) -> None:
self.name = name
self.price = price
self.weight = weight
このClassのInstanceを1つの要素とするlistに対して、例えば以下のような操作を考えます 「名前に“apple”という単語が含まれている商品の中で、価格が500(円)以下であるような商品の重さの総和を求める。」
これを実装する際の思考順序は
- nameにAppleが入ってるかでFilterする
- 価格の上限でFilterする
- WeightのAttributeだけ取り出す
- 総和を取る
というnarrow downしていく方向になるかと思います。
これをPythonで実現しようとすると以下のようなコードになります。
# 従来
products = [
Product("apple", 100, 12.2),
Product("apple_watch", 50000, 123.4),
Product("apple_juice", 400, 32.2),
Product("grape", 120. 120.5),
Product("orange_cake", 1000, 10.0),
]
sum_of_price = sum(
map(lambda p: p.weight, filter(
lambda p: p.price <= 500, filter(
lambda p: "apple" in p.name, products)
)
)
)
しかしPythonの既存の枠組みでは、上記コードのように思考順序と逆転した順序で実装をする必要があります。これを次のように実装できたらどうでしょうか?
# 変更後
sum_of_price = products \
.filter(lambda p: "apple" in p.name) \
.filter(lambda p: p.price <= 500) \
.map(lambda p: p.weight) \
.sum()
これは思考順序に沿っているためユーザフレンドリです。さらに、後ろにMethodをチェインして書けることは、従来の書き方に比べて括弧のネストがなくなる、インデントが浅くなる、など可読性の向上にもつながります。
機能の仕様
今回追加したMethodはlist.map(func), list.filter(func), list.sum(), list.max(), list.min()になります。
list.map(func)
listの各要素にfuncを適用し、戻り値からなるlistを返します。
list.filter(condition)
listの各要素のうち、condition(boolを返す関数)を満たす要素のみからなるlistを返します。
list.max(), list.min(), list.sum()
それぞれ標準組み込み関数の挙動と同じです。
実装の概略
いずれも既に組み込み関数に実装されていますが、組み込み関数はPythonのIterableに対する挙動のために非常に長い実装になっていることから、listというコンテナ型に閉じた実装にすべく、一からすべてロジックを実装しました。
まず、 list に関わる関数がどこで実装されているかをgdbを用いて調べ、 listobject.c に存在することを確認しました。関数がどのようにして実装されているかは、Extending Python with C or C にほとんど書いてあり、これから既存の実装を追うことが出来ました。いきなり完成形を目指すのではなくdone is better than perfectの方針で、小さな完成物を徐々に最終形に近づけるという方式でコードを着実に書いていきました。具体的には
- 実際にメソッドを追加して、呼び出してみる(中身はDummy)
- 関数の中身を簡単な形で実装してみる(例えば、mapでは引数の数字を全要素に加えるといった実装を行いました)
- 実際の機能を実装する
- テストを通じてバグ修正 & エラーハンドリングの追加(ここは不完全ですが…)
という形で行っていき、完成させました。
map関数の実装
実際に、上のフローをコミットにしたがって見ていきます。
まずは、関数を追加してみます。具体的には、ヘッダーファイルにPyDocや関数の仕様などを書き、 listobject.c に関数の本体と辞書にメソッドを追加します。
次に、中身をちょっとそれっぽく変えてみます。
最後に、実際の機能を追加します。(以下はまだ完成形ではありません。)
エラーハンドリングは例えば実際に呼び出し可能な関数が来ているかなどを確かめます。
色々問題な箇所などをリファクタリングして以下のように完成させました。
このようにして新たに list.map methodを追加することができました。
同様の手順で filter, sum, min, max の実装を行いました。
実装上苦労したポイント
lambda関数の扱い方
list.map 及び list.filter ではlambda関数を取り扱わなければなりません。このlambda関数の取扱については中々情報がなく、この実装上1番手が止まった部分でした。結果としては、実行時に与えられたものであればそれが関数であれ有無を言わずPyObjectとして引数に渡ってくるため、適切なAPIから呼び出すことで解決しました。APIは他にlambda関数を使用するであろう list.sort 関数の実装の中で見つけることが出来たため、これを使用することで実装が出来ました。
参照カウントの扱い方
CPythonでばGarbage Collectionのために参照カウント法を用いています。参照カウントを見ることで、これが0になったらメモリから消去して良いと判断して消去するなどしています。逆にあるオブジェクトを生成したりするときはこれを増やさないといけません。CPythonではPyINCREF, PyDECREFというAPIで増減することができます。
もし、勝手に減らせばいつの間にかメモリ上から消去され、SegmentationFaultの原因となりますし、勝手に増やせば、適切なタイミングで消去されず(あるいは一生残り続けて)、メモリリークの原因となります。
概念自体は調べれば出てくるので難しくありませんが、実際の実装ではどのタイミングで、APIを呼び出すか、が難しい部分でした。
余談: なぜこのような機能が既に存在しないのか?
このような機能は他の言語でも見られますが、何故Pythonには無いのでしょうか?公式のDesign and History FAQにて、
Why does Python use methods for some functionality (e.g. list.index()) but functions for other (e.g. len(list))?
という質問が投稿されていました。これに対するCommunityの回答は、本質的には今回のような機能の存在意義に関連しています。
理由1: "postfixよりprefix/infixの方が読みやすい"
(a) For some operations, prefix notation just reads better than postfix – prefix (and infix!) operations have a long tradition in mathematics which likes notations where the visuals help the mathematician thinking about a problem. Compare the easy with which we rewrite a formula like x*(a+b) into xa + xb to the clumsiness of doing the same thing using a raw OO notation.
班としては、私達が感じていたものと真逆のことのため、ただの個人差では?という感想に終わってしまいました。
理由2: "methodの場合、Classの定義の仕方によっては混乱を招く"
When I read code that says len(x) I know that it is asking for the length of something. This tells me two things: the result is an integer, and the argument is some kind of container. To the contrary, when I read x.len(), I have to already know that x is some kind of container implementing an interface or inheriting from a class that has a standard len(). Witness the confusion we occasionally have when a class that is not implementing a mapping has a get() or keys() method, or something that isn’t a file has a write() method.
これは、ユーザー定義のClassを組合せた場合に生じる混乱です。mappingを実装していないのにget()やkeys()を持っていたり、fileでもないのにwrite()というmethodを実装していたり、コンテナlikeなClassでもないのにlen()を実装していたり、などの場合が該当します。
もし今回追加した機能のようなスタイルが標準になっている場合、Classのユーザはlen()というMethod名からそのClassの意味を読み取ることができてしまいます。すると、そのClassのlen()というmethodが"標準的なlen()を実装しているコンテナlikeなClassなのか"を確かめる必要がでてきます。これは余計な思考と言えるでしょう。
一方で、現在のPythonのようにlen()やmap()、sum()という組み込み関数を用意することで、わざわざ確かめなくとも中の引数が(ユーザー定義であっても)コンテナLikeであることをユーザはすぐに理解できます。「標準の組み込み関数の引数に入ってるんだから、自然なClassなはずだよね!うん!」と思うことができるからです。そのため現在のスタイルの方が良い、という主張のようです。これは理解できます。
個人的意見: 動的型付けだから?
そもそもPythonのlistは型の違う要素でも入れることを許容している点などから、"T型の配列"というような扱いをされていないのではないかと思います。
実用上は、listの中に入れる要素の型は全て同じである場合が大半でしょうし、Type AnnotationではList[int], List[MyClass]といった記法が高頻度で使われています。しかし、listというObjectの言語の中での位置づけとしては、このような型の揃ったList[T]ではなく、List[Any]であるというギャップがあるように思います。
今回のような高階関数は、引数に取る関数の型U->Vと、コンテナの要素の型に関する情報がfixしていないと期待される挙動をする保証がありません。標準でList[Any]になってしまう可能性があるlistというObjectに対して特別にMethodとして高階関数の機能を提供しないのは、このような型に関する保証をRuntimeでしかすることができない(動的型付け)からではないかと思います。
個人的には、実用上listはList[T]として使われているし、mypyなどの静的型検査ツールの利用が一般的になっているのだから、このようなMethodを追加しても良いのではないかとも思います。一方で同時に標準で許容されている機能はユーザに全て使われ尽くす想定をしなければならないのは確かであるため、難しい点だと思います。
Limitation
毎回のMethod呼び出しの度に新しいlistを返しています。組み込みの関数mapなどはイテレータで扱っているためメモリ効率が良いのですが、今回はlistというコンテナに閉じてMethodを追加するという方針で取り組んだため、この辺りはLimitationといえます。
2. NumPyのようにlistのIndexingをする
モチベーション
Pythonの多次元リストの要素は次のように参照することができます。
ls = [[1, 2, 3], [4, 5, 6], [7, 8, 9],]
# (1, 2)番目の要素の参照
ls[1][2]
このような配列参照の方法にはいくつかのデメリットがあります。
listの次元の一般化が大変
例えば、あるn次元リストtensorと、そのリストの1要素を示すIndex idxを受け取り、そのIndexが表す要素をinplaceに2倍する関数を考えます。
def double_element_in_tensor(tensor: List[Any], idx: Union[Tuple[int], int]) -> List[Any]: ...
これは従来のPythonでは、「n次元リストを1段階だけ参照してn-1次元リストを得る」を繰り返すことで実現できます。
def double_element_in_tensor(tensor: List[Any], idx: Union[Tuple[int], int]) -> List[Any]:
ndim = len(idx)
a = tensor
for dim, i in enumerate(idx, 1):
if dim == ndim:
# reference to target element
a[i] *= 2
else:
# depth+1
a = a[i]
しかしこれはやや複雑です。その原因は「n次元listの要素をUniqueに特定する方法が段階的である」ことにあります。n次元listの要素を一発で指定できるような書き方ができればこのような問題はなくなるはずです。そこで、次のような参照方法が可能になったらどうでしょうか?
#(1, 2)要素目
ls[1, 2]
これはNumPyのArrayやPyTorchのTensorで可能な方法です。 このような書き方ができると、先ほどdouble_element_in_tensor関数は以下のように簡潔に実装できます。
def double_element_in_tensor(tensor: List[Any], idx: Union[Tuple[int], int]) -> List[Any]:
tensor[idx] *= 2
コード量が激減し、直感的な実装になっていますね!
機能の仕様
上の例で述べた通り、idxをn次元のTuple[int]型だとすると、n次元listlsに対して、ls[idx]はlsの要素への参照を返します。インデックスにはintだけでなくsliceも指定することができます。参照先がlistである限り参照し続けることができます。
例えば以下のように書くことが出来ます。
ls = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
# (1, 2)番目の要素の参照
ls[1, 2] # 6
# (1, )番目のlistの逆順
ls[1, ::-1] # [6, 5, 4]
実装の概略
1.と同様に list の参照に関わる関数をgdbを用いて調べたところ、 listobject.c 内の list_subscript という関数が参照時に呼ばれていることを確認できました。実装を見たところ、 list_subscript 関数では引数として与えられた値がリストのインデックスあるいはスライスとして適当であるかチェックし、適当であれば参照した値を、適当でなければエラーを返す、というような処理が行われていました。そこで、引数をチェックするところの分岐に tuple の場合を追加し、引数として受け取れるようにしました。その上で引数が tuple であった場合の処理を追加することで、 tuple によるリストの参照を実現しました。また、リストの要素への代入操作は list_ass_subscript という別の関数が担っていることが後から分かったので、こちらも同様に編集することで代入操作も実現しました。
具体的な実装
numpy.ndarray や torch.Tensor では各次元のサイズが揃っていることを利用して、メモリアドレスを直接求めることで高速な参照が可能でした。しかし多次元の list では各次元のサイズが揃っているとは限りません。したがって通常の多次元リストの参照と同じように、内部の実装ではリストを1次元ずつ遡って参照する必要があります。これを実装する方法として、以下の2つのアプローチを思いつきました。
-
forやwhileなどのループを用いて1次元ずつ遡る - 再帰を用いて1次元ずつ遡る
どちらの実装でも、処理の順序の概要は以下のようになります。
-
listとインデックスをまとめたtupleを受け取る -
tupleの最初の要素iを取り出す - 取り出した要素
iが、listのインデックスとして適当かチェックする -
listのi番目の要素aを参照し、取得する -
tupleにi以降の要素が存在するか確認する - 5.が存在すればリスト
aに対して2.から5.までの処理を繰り返し、存在しなければaを返す
再帰を用いたアプローチ
ここで、3.のチェック処理および4.の要素を参照・取得する処理はすでに list_subscript 関数に実装されていました。ループを用いたアプローチではこの処理を書き直す必要がありますが、再帰を用いたアプローチではこのソースコードを有効活用することができ、実装が比較的スムーズになります。したがって、新たなリストと tuple を取得して list_subscript 関数を再帰的に呼び出すという、再帰を用いたアプローチを採用することにしました。実装は以下のようになりました。
ところがこの実装には大きな欠点がありました。再帰関数を呼び出すときに新たな tuple を取得していたのですが、この処理はPythonのスライスと同じであり、計算ステップ数と消費メモリはいずれも tuple のサイズに比例します。すなわち遡る次元数を
ループを用いたアプローチ
上記の問題を解消するためには、再帰関数を工夫する必要がありました。しかし、もともと実装されている関数に手を加えて再帰関数とするのですから、引数を変えるなどの大規模な改変はできません。再帰を用いるモチベーションは3.から4.の処理を省略できることにありましたから、この部分だけ再帰を用いて残りはループで実装すれば、計算量を改善できるのではないかと考えました。実装は以下のようになり、非常に簡潔に書くことができました。
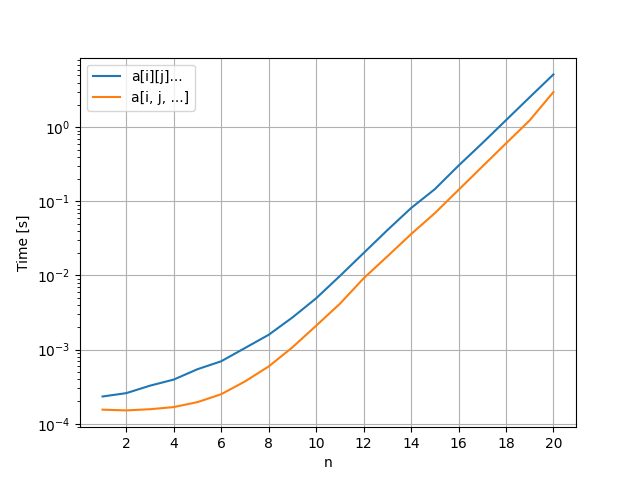
パフォーマンスの比較
まず、
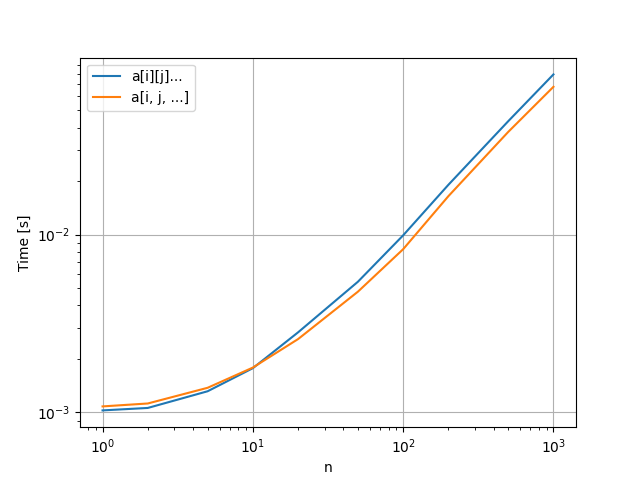
次に、 itertools.product の返り値を直接利用することができるため、全体的に新しい表記のほうが速い結果となりました。従来の書き方ではPythonのforループをネストしたり、 tuple をPythonインタプリタを通して参照したりしなければならないため、C言語で実装された新しい表記と比べるとパフォーマンスの低下が目立ちました。
おまけ: TypeVar Default Value
実験の時間が微妙に余ってしまったため、PEP696で提案されている機能の一部をサポートすることを目標に、可能な部分まで取り組みました。
提案されている機能
Pythonには標準ライブラリとしてtypingというType Annotaitonのためのライブラリが用意されています。Type Annotationは昨今のPythonを用いた開発では当たり前のように用いられる機能となっており、typingライブラリとmypyといった静的型検査ツールを組合せた使用は、より効率的で安全なPythonによる開発を実現します。
このTypingライブラリに、TypeVar, GenericというClassが存在します。
TypeVarはユーザ定義の型変数を定義できるもので、様々なOptionを指定することにより型・制約を抽象的に表現することが出来ます。GenericはC++のtemplateなどと似た機能で、Classの定義内において型変数を用いたType Annotationが可能になります。これらはいずれもType Annotationの実用性を大きく向上させる機能になっています。
PEP696の提案の一部は、このTypeVarにdefault値(型)を設定できるようにしようというものです。
サポートできたケース
今回サポートできたユースケースは次のようなものです:
from typing import TypeVar, Generic
A = TypeVar("A", default=int)
B = TypeVar("B", default=str)
C = TypeVar("C", default=float)
class Product(Generic[A, B, C]):
def __init__(
self,
attr1: A,
attr2: B,
attr3: C,
):
self.attr1 = attr1
self.attr2 = attr2
self.attr3 = attr3
p1 = Product[int, str, float]
p2 = Product[int, str]
p3 = Product[int]
assert p1 == p2
assert p2 == p3
従来であればGenericで使用している型変数全てについて具体化する必要がありましたが、TypeVarの初期化においてdefaultという引数に型を設定しておくと、何も具体的に指定しなかった場合に自動的にその型が変数に割り振られるという機能が実現できました。
実装の主な変更は以下のようになっています。
感想
@irungo_ic (GitHub: maronuu)
OSSを触った経験は若干ありましたが、ここまで大規模かつ基盤的なソフトウェアを触ったのは初めてでした。ドキュメントやコミュニティが非常に充実しているため、情報に困ることがなかったのは精神衛生上とてもよかったです。CPythonのAPIをある種“システムコール”のように扱ってCのプログラムを書くような気分で終始実装していました。 実装の中でメモリ管理周り(参照カウントなど)やPythonのObjectの構成など、Python言語自体への理解も深まり、楽しい実験でした。今回はあまり縁がなかったですが、Parser部分や、最適化部分などもソースを読んで、インタプリタへの理解を深めていきたいなと思いました。 今回追加した機能は班員で「あったらいいよね」と話し合った結果生まれたものですが、残念ながらコミュニティの指針には沿っていなかったようでした。これほど世界的に使われているOSSはCommunityによる細かい議論のもと慎重に進められているんだなぁ…というのが実感できました。 学科同期とワイワイしながら開発できて、思い出に残る実験でした! (@irungo_ic)
@yutyan_ut (GitHub: yutyan0119)
同じくOSSを触れる経験自体はありましたが、プログラミング言語そのものをいじるという経験は初めてでした。CPythonは情報がいっぱいあるだろうと思って初めましたが、実際圧倒的に充実した公式ドキュメントに圧倒され、誰でも必要な改造が出来るようになっていたのは、Pythonのコミュニティの強さを最も感じた場面だと思います。逆に、これほどまでに充実させないとOSSが生き残るには厳しいものがあるんだろうなと感じました。本当はもっと低レイヤまで掘り下げたかったのですが、はじめに決めた方向性では思ったよりも低レイヤまで掘り下げることも出来ず(これ自体は誰でもPythonを改造しやすいという点において優れていると思います)、今後はもっと深く手探りたいなぁと思っています。この実験では、なによりも自分1人では書ききれないし読みきれないような量のソースコードから必要な部分を探し出し、ピンポイントでいじるという力が磨かれたと思います。とても有意義で楽しい実験でした!(@yutyan_ut)
@ncrpy (GitHub: ncrpy)
Pythonは個人的に大好きな言語なので、今回の実験でその中身に触れることができて嬉しいです。必要な情報のほとんどは公式ドキュメントを読めば理解できるようになっていたので、実験を進める上での道しるべとなり非常に助かりました。人気のソフトウェアは機能だけでなくサポートも充実しているのだということを実感しました。また、PythonがC言語で実装されているのは知っていましたが、オブジェクト指向を持たないC言語での実装の詳細を新たに知ることができました。CPythonではオブジェクト指向的な設計を実現するために構造体とポインタがいたるところで利用されており、Python上のObjectとの対応関係を考えながらCPythonのソースコードを読むのが面白かったです。これからPythonを使うときには、内部の実装も意識しながらコードを書くことができればいいなと思います。Pythonに限らず、日頃から使っているソフトウェアの実装を知ることができるのはOSSの強みだと感じました。一緒にCPythonを手探ってくれた班員の皆さんに感謝しております。楽しかったです! (@ncrpy)
Discussion
great work
Thanks! 😊